AIで理想の顔を作るLoRA学習の魅力
要点:LoRA(※1)を活用して顔だけの学習を行うことで、Stable Diffusion(※2)で特定の人物やキャラクターを驚くほど似せて出力せることが可能になります。

AIイラストを制作する中で、「特定のキャラクターをいつも同じ顔で描きたい」と思ったことはありませんか?
標準のチェックポイント(※3)だけでは、プロンプト(※4)を変えるたびに顔立ちが変わってしまい、キャラクターの固定が難しいという問題があります。
そこで重要になるのがLoRAの作成です。
2026年現在、sdxlや最新のflux(※5)モデルが普及しました。
ローカル環境での学習はより身近になりました。
本記事では、初心者でも簡単に実践できるLoRAの学習方法を詳しく解説します。
- データセットの準備
- 学習パラメータの設定
まで、自分だけの最強モデルを作るためのノウハウをすべて紹介します。
- ※1 LoRA:Low-Rank Adaptation。特定の概念を低コストで追加学習させる技術。
- ※2 Stable Diffusion:オープンソースの画像生成AI。WebUI等で操作する。
- ※3 チェックポイント:AIモデルの本体。絵のベースとなる巨大なファイル。
- ※4 プロンプト:AIに指示を与えるためのテキスト命令。
- ※5 flux:2024年後半から流行した、極めて描写能力の高い最新モデル。
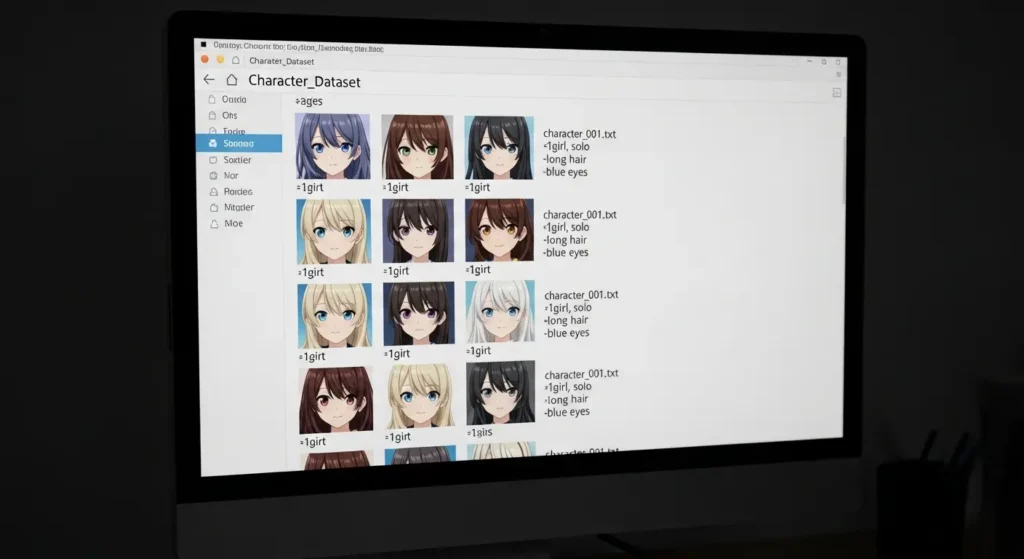
【LoRAで顔作成】学習データセットの準備
要点:LoRAで顔を作成する際、学習データセットの質と数は、生成される画像の精度に直結するため、多角度かつ高解像度な素材を用意することが必要不可欠です。
画像の選別とトリミング
学習に使う画像は、正面だけでなく横顔や斜めの角度を含めるのがポイントです。
枚数は15枚から30枚程度あれば十分な結果が得られます。
画像編集ソフトやphotoshopを使って、顔が中心に来るように正方形(512×512や1024×1024)にクロップ(※6)しましょう。
キャプション付けのコツ
wd tagger等の拡張機能を利用して、画像にタグを付けます。
顔だけを学習させたい時は、衣装や背景に関するタグをしっかり残すことが重要です。
そうすることで、AIは「この部分は衣装だ」と認識し、結果的に顔の特徴だけを吸収してくれます。
Stable Diffusionで顔LoRAの作り方【実践編】
要点:Stable Diffusionで顔LoRAの作り方において、kohya scripts(※7)やguiツールを使用し、適切な値のnetwork rankやlearning rateを設定することで、過学習を防ぎつつ再現性を高められます。
LoRAの作成は、
- 環境構築
- データセットの配置
そしてパラメータの微調整という3つの大きなステップに分かれます。
1. 学習環境の構築とツールの導入
ローカルPCで学習を行う場合、kohya_ssというGUI(※12)ツールをインストールするのが最も一般的です。
GitHubから最新のソースをダウンロードします。
- Python
- Git
- NVIDIAのCUDA(※13)
上記の環境を整えます。
VRAMが不足している場合は、Google Colab(※14)などのクラウドサービスを利用する方法も有効です。
2. データセットの階層構造と繰り返し数の設定
フォルダ構成は、AIが正しく学習するために非常に重要です。
- 10_face_name: フォルダ名の先頭の数字は「その画像を何回繰り返しトレーニングするか」を意味します。
- 画像が20枚で、数字を「10」にした場合、1エポック(※15)につき200回の学習が行われます。
顔だけを際立たせるには、背景がバラバラな写真を用意し、AIに「共通しているのは顔だけだ」と認識させるのがコツです。
3. 学習を成功させる核心パラメータの設定
Stable Diffusionで精度の高い顔を生成するための、2026年版推奨設定は以下の通りです。
- Network Rank (Dimension): 32〜64。顔の複雑な表情を捉えるには少し高めの設定が良いです。
- Network Alpha: Rankの半分(16〜32)に設定すると、学習が安定しやすくなります。
- Optimizer: AdamWや最新のProdigy(※16)。Prodigyは学習率を自動調整してくれるため、初心者には特におすすめです。
- Resolution: SD1.5なら512、SDXLやFluxなら1024を選択。
4. 過学習(Overfitting)を防ぐテクニック
LoRAが似すぎてしまい、どんなプロンプトを入れても同じ構図や背景しか出ない状態を過学習と呼びます。
- 対策: エポック数を減らすか、学習率(Learning Rate)を少し下げて実行します。1g(※17)あたりの情報密度を調整するイメージで、サンプル画像を見ながら最適なポイントを見つけましょう。
- ※12 GUI:グラフィカル・ユーザー・インターフェース。文字入力だけでなくマウスで操作できる画面。
- ※13 CUDA:NVIDIA製グラボでAI計算を高速化するための技術。
- ※14 Google Colab:ブラウザ上でPythonを実行できるサービス。高性能なGPUを借りられる。
- ※15 エポック:全学習データを一通り読み込み終える単位。
- ※16 Prodigy:2024年以降に普及した、設定の手間を省く高度な最適化アルゴリズム。
- ※17 1g:ここではデータの重みや学習の単位を指す比喩的表現。
学習済みの顔をLoRAで活用【品質向上】
要点:作成したLoRAをWebUI(Automatic1111やForge)に導入し、トリガーワードとウェイトを組み合わせて、最高の一枚を生成します。
トリガーワードの入力と効果の確認
学習時に設定した名前(トリガーワード)をプロンプトの先頭に入力します。
例:
(trigger_word:1.2), 1girl, looking at viewer, masterpiece...括弧と数値で強調(※18)を付けることで、顔の再現度を自由に変えることができます。
ADetailerを使った顔の自動再描画
全身の構図を生成すると、どうしても顔の解像度が不足します。
崩れが発生しやすくなります。
この時、拡張機能のADetailer(※19)のモデル設定に自作のLoRAを適用すると、仕上げの段階でAIが顔だけを高精細に描き直してくれます。
- ※18 強調:特定の単語の影響力を強める記述方法。
- ※19 ADetailer:顔や手を自動で検出し、再描写してクオリティを上げる必須級ツール。
学習パラメータの最適設定
顔のような複雑な要素を学習させる際、network dim(rank)は16から32程度がおすすめです。
値が高すぎるとファイルサイズが大きくなり、低すぎると特徴を反映しきれません。
最近のトレンドでは、sdxlモデルベースならより高い解像度でのトレーニングが推奨されます。
学習の実行と確認
作業はgpu(※8)のvramを消費するため、nvidiaのrtxシリーズ(12gb以上推奨)を搭載したpcが望ましいです。
学習途中で出力されるサンプル画像を確認します。
似ているかどうかをチェックしましょう。
絵柄までコピーされてしまう場合は、lr(※9)を調整するか、画像のバリエーションを増やす必要があります。
- ※7 kohya scripts:LoRA学習において世界的に標準となっている学習用プログラム。
- ※8 GPU:画像処理を専門に行うパーツ。AI学習には不可欠。
- ※9 lr:Learning Rate(学習率)。AIが一度にどれだけ学ぶかの度合い。
【AIイラスト】顔の差し替えと精度向上
要点:AIイラストで顔の差し替えはLoRAを活用すれば、すでに生成した画像に対して、adetailer(※10)などのツールを使い後から顔だけを修正することも簡単に出来ます。
顔崩れへの対策
Stable Diffusionで顔の崩れをLoRAで解決するためには、ウェイト(※11)の調整が不可欠です。
強すぎると全体が崩れてしまいます。
通常は0.5から0.8程度で使用します。
他のLoRAと組み合わせる際は干渉に注意しましょう。
2026年はflux用LoRAのクオリティが劇的に向上しております。
プロレベルの制作が個人でも可能です。

素材の個性を引き出す高度なデータセット構築
要点:1枚の画像から得られる情報には限りがあります。そのため、動画からの切り出しや多角的な撮影素材を含め、最低限必要な枚数を確保しつつ左右の対称性や表情の作りを含めた内容を充実させることが、精度向上の近道です。
キャラクターの元のイメージを壊さずにLoRAを作っていく作業は、デザイナーとしての経験が強く問われる部分です。
何も知らずに適当な画像を放り込むだけでは、ai特有の不自然な歪みが発生してしまいます。
最初の項目として意識すべきは、素材のバリエーションです。
- 左右に顔を振った状態
- 目を細めた笑顔
など、いろいろなパターンを撮影、あるいは動画から抽出して用意しましょう。
SNSや専門サイトでのリサーチ活用
最新の技術情報は、X(旧Twitter)やRedditといったSNS、あるいはcivitaiのページに多く投稿されています。
他の人がどのようなpromptを使って、どのような結果を出しているのかを参考にするのは非常に有効です。
コメント欄に書かれた失敗談や解決策は、自分の制作においてかなり参考になる貴重な情報源となります。
2026年のトレンド:最新モデルとの互換性
要点:2026年現在、illustriousやFluxといった高性能なモデルがメイン機能として使えるようになります。mac等の環境でも有料サービスを併用することで、プロ級の顔生成が身近になっています。
2024年頃から、AIイラストの世界はsdxlからより高度なアーキテクチャへと移行します。
顔の質感や人間としてのリアリティが飛躍的に向上しました。
特に、illustrious系モデルをベースにしたLoRA学習は、アニメ調からリアル系まで幅広く対応しており、気になる崩れを大幅に軽減できます。
生成時の試行錯誤とChatGPTの活用
学習が完了した後は、実際にWebUIなどで生成を試します。
内容を精査する段階に入ります。
promptの組み立てに迷った際は、ChatGPTにイメージを伝えます。
効果的な単語の羅列を作成してもらうのもおすすめです。
1枚ごとに条件を少しずつ変更しながら、どのウェイトが最も似ているかを確認しましょう。
- 注意点: 有料のクラウドGPUを使う場合は、時間あたりの料金がかかります。無駄を省くために、事前にフォルダ内のファイルを整理しておきましょう。学習設定にミスがないか最低限のチェックを行いましょう。
もう、初心者だからと諦める必要はありません。
ホームページやコラムを読み込み、先人たちの知恵を活用すれば、それなりのスペックのPCでも最高のキャラモデルを作成できる時代です。
自分が作ったLoRAで理想のイラストが出た時の感動は、何物にも代えがたい経験となるはずです。
よくある質問 (FAQ)
要点:LoRAの学習に関してよくある疑問にお答えします。
Q1: 学習に必要なPC スペックは?
A1: VRAM 12GB以上のRTXグラフィックボードを推奨します。
メモリが不足するとエラーが出るため、事前にスペックを確認しましょう。
Q2: 自作LoRAを公開してもいい?
A2: 実在の人物や著作権のあるキャラクターのLoRAには注意が必要です。
プライバシーポリシーや利用規約を確認しましょう。
権利を侵害しない範囲で活動してください。
自分だけのAIモデルで創造を楽しもう
要点:LoRA 顔だけ 学習方法をマスターすることで、AIイラストのクオリティは飛躍的に向上し、キャラクターの再現という新たな分野へ踏み出し次世代のクリエイティブを実現できます。

今回紹介した手順を一つ一つ丁寧に行えば、誰でも高品質なLoRAを作れるはずです。
過学習や崩れに悩んだ時は、本記事のガイドに戻って、パラメータやタグを見直してみてください。
AIの世界は日々進化しています。
新しく登場する技術を柔軟に取り入れ、充実した制作ライフを送りましょう。
LoRA学習の実践と悩み解決のための関連記事
この記事を読んでいるユーザーは「作り方」に興味がありますが、同時に「失敗」への不安も抱えています。
LoRA学習の失敗はこれで解決!原因特定とパラメーター設定の完全ガイド
【2025年最新】LoRAモデル配布サイト完全版|おすすめダウンロードと使い方
「顔」から「全身・ポーズ」へ
顔の固定に成功したユーザーは、次に「ポーズ」や「構図」の制御へ関心が移ります。
Stable Diffusionで全身画像を完璧に生成!高画質化とプロンプト呪文全集
「技術」から「ツール・API」へ
ローカル環境の構築にハードルを感じている層や、API利用を考えている層を救い上げます。
LLM APIを無料で使い倒す!2025年最新の無料枠・制限・活用法徹底ガイド