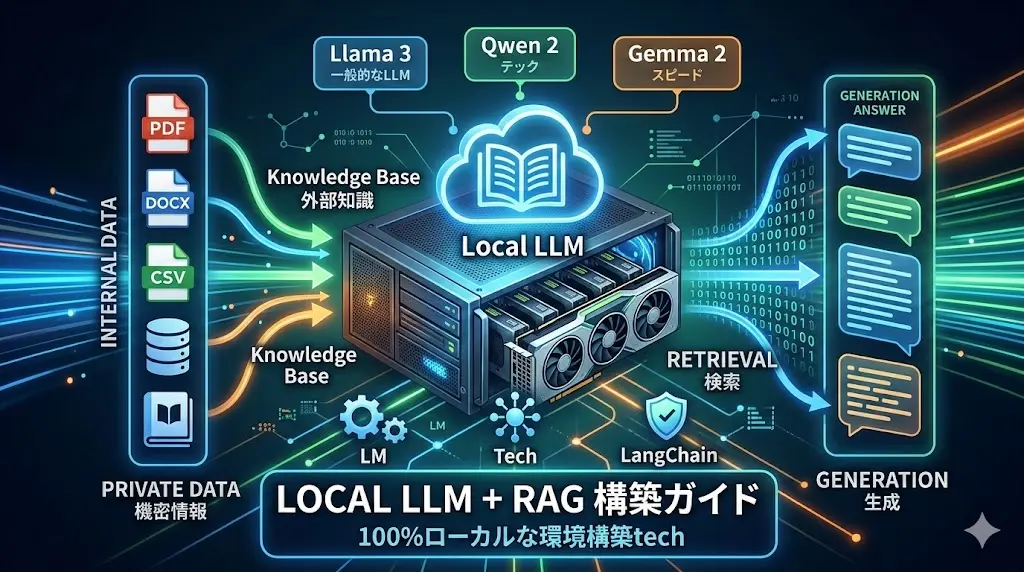
要点:ローカルLLMとRAGを組み合わせることで、クラウドサービスに依存せず、社内データに基づいた正確なAI回答環境を100%ローカルで実現できます。
2026年現在、AIの活用は新たなフェーズに入りました。
ChatGPTのようなクラウド型AIは非常に便利です。
しかし、企業が持つ機密情報を外部のサーバーに送信することには依然として大きなリスクが伴います。
そこで注目されている技術が、ローカル環境で動作する大規模言語モデル(LLM)と、特定のナレッジを外部知識として参照させるRAG(Retrieval-Augmented Generation)の組み合わせです。
本記事では、LangChainやllama.cppといった最新のツールを駆使します。
誰でも自分専用のセキュアなAIシステムを構築するための手順を詳細に解説します。
要点:ローカルLLM構築の成否は、
- ハードウェアの制約に基づいたモデル選定
- 適切な推論エンジンの導入
そして量子化技術によるリソースの最適化という3つのステップを正しく踏むことで決まります。
ローカルLLM構築の基本ステップ
ローカルLLM構築のプロセスは、かつてのような複雑なソースコードのビルド作業から、パッケージ化されたツールを使いこなすフェーズへと進化しました。2026年現在の標準的な手順を詳しく解説します。
ハードウェアリソースの現状確認
構築を開始する前に、まず自分のPC環境を正確に把握する必要があります。LLMの動作において、最も重要なのは計算速度(CPUコア数)ではなく、モデルをロードするためのメモリ(メモリ)容量です。
- GPU搭載PCの場合: NVIDIA製GPU(RTX 30シリーズ以降)を搭載しているなら、CUDAを活用した高速な推論が可能です。VRAM(ビデオメモリ)が8GBあれば軽量モデル、16GB以上あれば標準的なモデルが快適に動きます。
- Macの場合: Appleシリコン(M1〜M4チップ)搭載機であれば、ユニファイドメモリアーキテクチャにより、メインメモリの多くをAI処理に割り当てられるため、非常に強力な選択肢となります。
推論エンジンのインストールと設定
モデルを動かすための「心臓部」となる推論エンジンを選定します。2026年時点では、以下のツールが構築の主流です。
- Ollama(ollama): コマンドラインベースで動作し、バックグラウンドでサーバーとして稼働します。RAGシステムとの連携が非常に容易なため、開発者(開発)に最も選ばれています。
- LM Studio: GUI(画面)上でモデルの検索から設定まで完結するため、初心者(誰)でも迷わずに構築可能です。
- llama.cpp(llama.cpp): 限界までパフォーマンスを引き出したい上級者向けです。特定のハードウェアに最適化(最適化)された設定を細かく調整(設定)できます。
モデルの選定とダウンロード(量子化の選択)
次に、用途に応じたAIモデルを選択します。Hugging Face(face)などのプラットフォームには、MetaのLlama 3やGoogleのGemma(gemma)など、数多くのオープンソース(オープンソース)モデルが公開されています。
- パラメータ数の選択: 一般的なPCであれば「8B(80億パラメータ)」クラスが最もバランスが良く、生成速度と精度の両立が可能です。
- 量子化(形式)の選定: GGUF形式などの量子化モデルを選びます。4bit量子化(Q4_K_Mなど)を選択すれば、元のモデルの精度をほぼ維持したまま、メモリ消費量を大幅に削減(軽量)して実行(実行)できます。
動作確認とプロンプトテスト
構築が完了したら、実際にチャット(チャット)を起動して応答を確認します。
- 初期設定の変更: 推論に使用するGPUレイヤー数やコンテキストサイズ(一度に扱える情報量)を、PCのメモリ量に合わせて調整します。
- 日本語性能の確認: 「自己紹介をしてください」といった簡単な質問(質問)を投げ、出力(出力)の自然さや速度(トークン数)を確認(確認)します。
注釈:コンテキストサイズ AIが一度に覚えておける情報の長さ。
RAGで大量のドキュメントを読み込ませる場合は、この数値を大きく設定する必要があります。

要点:RAGは検索と生成を分離することで、LLMの再学習なしに最新情報や社内独自の機密データを回答に反映させ、AI特有の嘘(ハルシネーション)を劇的に抑制する仕組みです。
RAG実装の仕組みとメリット
2026年現在、ローカルLLMを実務で活用する上で、RAGは欠かせない技術となりました。
大規模言語モデルがトレーニング時に持っていない最新の情報や、社内にしかない独自の資料をAIに教えるための最も効率的な方法がRAGです。
RAGを構成する4つのコアプロセス
RAGの実装は、単なる検索ではなく、以下のステップを経て回答を生成します。
- インジェクション(投入): PDFやマニュアルなどの文書を読み込み、扱いやすいサイズに分割します。
- 埋め込み(Embedding): 分割された各チャンクを、意味を保持したまま数値のリスト(ベクトル)に変換します。
- 検索(Retrieval): ユーザーの質問に対して、ベクトルデータベースから関連性の高い情報を抽出します。
- 拡張生成(Augmented Generation): 抽出した情報を参考資料としてプロンプトに追加し、LLMに最終的な答えを出させます。
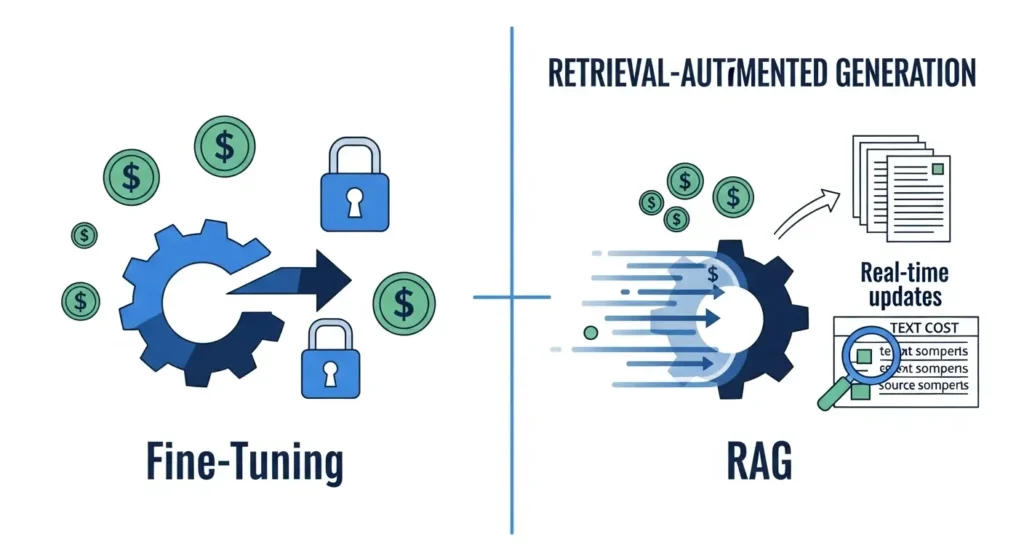
ファインチューニングと比較したRAGの圧倒的メリット
AIに新しい知識を覚えさせる方法としてファインチューニングがありますが、実務においてはRAGの方が多くの点で優れています。
- 情報の鮮度: RAGならファイルをフォルダに追加するだけで、再学習なしに最新の情報を回答に反映できます。
- 根拠の明示: AIがどの資料のどの箇所を参照したかをユーザーに提示できるため、情報の信頼性が担保されます。
- コストの最小限化: 膨大な計算リソースを必要とする学習とは異なり、ローカルなPCでも十分に実行が可能です。
ハルシネーション(嘘)の抑制と精度の向上
LLMはもっともらしい嘘をつくことが最大の課題でしたが、RAGはこの問題を根本的に解決します。
- 事実に基づいた応答: AIは自分の記憶だけでなく、目の前にある指定された文書から答えを探すため、正確な事実に基づいた会話が可能になります。
- 文脈の理解: 関連する複数の資料を横断的に参照することで、より高度で専門的な質問に対しても、的を射た回答を引き出すことができます。
注釈:ハルシネーション AIが事実に基づかない情報を、あたかも真実であるかのように生成してしまう現象。RAGによって外部知識を参照させることで、この発生確率を大幅に下げることができます。
要点:LangChainは、ドキュメントの読み込みからベクトル検索、回答生成までの一連の工程を連結するハブの役割を担い、複雑なRAGパイプラインを簡潔なコードで実装可能にします。
LangChainローカル連携の全手順
2026年のAI開発において、LangChainはローカルLLMと外部データを繋ぐ標準的なライブラリです。
LangChainを使うことで、特定のPDFや社内Wikiの内容に基づいた回答を行うアプリケーションを、Python環境上で迅速に構築できます。
Python環境の準備とライブラリ導入
まずは、プロジェクト用の仮想環境を作成し、必要なパッケージをインストールします。
- 基本パッケージの導入:
pip install langchain langchain-community ollamaを実行します。 - ドキュメント処理用: PDFを扱う場合は
pypdf、ベクトルDBとしてChromaを使用する場合はchromadbも追加で導入します。
ローカルLLMとの接続設定
LangChainからローカルで稼働しているモデルを呼び出す設定を行います。
Ollamaを使用する場合、非常にシンプルな記述で接続が完了します。
Python
from langchain_community.llms import Ollama
# ローカルで起動しているLlama 3を指定
llm = Ollama(model="llama3")
# 動作テスト
response = llm.invoke("ローカルLLMのメリットは何ですか?")
print(response)
ドキュメントローダーによるデータ取り込み
RAGの核心である外部知識を読み込みます。LangChainには、あらゆる形式に対応したローダーが用意されています。
- ファイル読み込み: 指定したフォルダ内のPDFやテキストファイルを一括で取得します。
- チャンク分割: LLMが一度に処理できるトークン数には制限があるため、適切なサイズに分割します。
Python
from langchain_community.document_loaders import PyPDFLoader
from langchain_text_splitters import CharacterTextSplitter
loader = PyPDFLoader("manual.pdf")
documents = loader.load()
# 文書を1000文字単位で分割
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=100)
texts = text_splitter.split_documents(documents)

ベクトル化と検索(Retrieval)の実装
分割したテキストを数値に変換(Embedding)し、検索可能な状態にします。
- ローカル埋め込み:
HuggingFaceEmbeddings等を使用すれば、埋め込み処理も完全にローカルで行います。 - DBへの保存: ベクトルデータベースに登録し、ユーザーの質問に似た箇所を瞬時に探し出せるようにします。
注釈:トークン
AIが文字を処理する際の最小単位。英語では単語、日本語では文字や熟語に近い単位でカウントされます。
要点:llama.cppはC++による極限の最適化とGGUF形式の採用により、一般的なコンシューマーPCでも高速な推論を実現します。
RAGの最終工程である「回答生成」のボトルネックを解消します。
llama.cppによるRAGの高速化
ローカル環境でRAGを運用する際、最大の課題は「回答が生成されるまでの待ち時間」です。
特にRAGでは、ユーザーの質問に加えて「検索された膨大な参考文書」をプロンプトに投入するため、計算負荷が通常よりも増大します。
2026年現在、この処理を最も効率的に行うエンジンがllama.cppです。
GGUF形式と量子化によるメモリ効率の極大化
llama.cppが高速である最大の理由は、GGUF(GPT-Generated Unified Format)という独自のファイル形式にあります。
- 高速なロード: モデルファイルをメモリへ直接マッピングするため、起動時間が劇的に短縮されます。
- 高度な量子化: 元のモデル(FP16)を4bitや8bitに圧縮することで、推論精度を維持しつつ、必要なVRAM容量を半分以下に抑えられます。これにより、ミドルクラスのGPUでも大規模なRAGシステムが稼働します。
AppleシリコンとNVIDIA GPUへの最適化
llama.cppは、特定のハードウェアが持つ演算加速機能を最大限に引き出す設計がなされています。
- Metalの活用: MacBookなどのAppleシリコン搭載機では、GPUとメモリが直結したユニファイドメモリアーキテクチャをMetal API経由で叩くため、驚異的な推論速度を叩き出します。
- CUDAとcuBLAS: WindowsやLinux環境のNVIDIA GPUでは、CUDAコアをフル活用して並列計算を行います。RAGにおける「長いコンテキストの処理」において、この並列演算能力が生成の速さに直結します。
RAGにおけるコンテキスト処理の高速化技術
RAGでは検索結果をプロンプトに詰め込むため、入力データが長くなる傾向があります。llama.cppはこれを処理するための独自の工夫を備えています。
- KVキャッシュの最適化: 過去の対話や参照ドキュメントの計算結果をメモリに保持(保存)し、再計算を避けることで、2回目以降の応答速度を劇的に向上させます。
- プロンプトのバッチ処理: 検索された複数の情報を一度に並列処理することで、逐次処理に比べて待ち時間を最小限に抑えます。
注釈:GGUF
llama.cppを中心に広く普及しているモデルファイル形式。単一のファイルで完結し、異なるOS間でも互換性が高いのが特徴です。
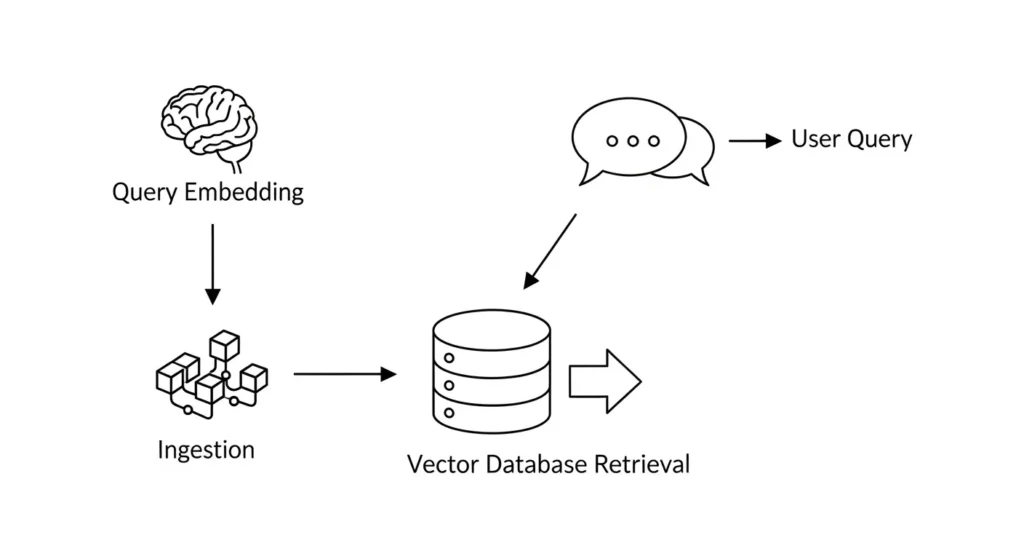
要点:ベクトルデータベースは、ドキュメントを「意味の近さ」で検索可能な数値データとして保管するRAGの心臓部です。
ローカル構築によって外部漏洩を防ぎつつ高速なナレッジ検索を実現します。
ベクトルデータベースローカル構築
RAGにおいて、大量の文書から質問に関連する箇所を瞬時に見つけ出す役割を担うのがベクトルデータベースです。
2026年現在、個人のPCや社内サーバー上で完結して動作するオープンソースの選択肢が充実しています。
ローカルで利用可能な主要データベース
用途や開発環境に応じて、最適なデータベースを選択することが構築のポイントです。
- Chroma(クロマ): Pythonとの親和性が非常に高く、LangChainでの標準的な選択肢です。設定が簡単で、インメモリでの動作も可能なため、最初のテストに最適です。
- FAISS(フェイス): Metaが公開しているライブラリで、大量のデータに対する検索速度が極めて速いのが特徴です。大規模なドキュメントを扱う実務向けと言えます。
- Qdrant(クアドラント): Rust製で安定性が高く、Dockerを用いてサーバー型として運用する際に強力なパフォーマンスを発揮します。
ベクトル化(Embedding)のプロセスと重要性
テキストをデータベースに登録する前に、必ず数値化の処理を行います。
- Embeddingモデルの役割: 文章を多次元の空間上の点として配置します。「リンゴ」と「果物」が近い位置に配置されるように変換することで、言葉の表面的な一致ではなく、意味の近さに基づいた検索を実現します。
- ローカル実行のメリット: 通常、この変換にはOpenAIのAPI等が使われますが、Hugging Faceの軽量モデルを使えば、この工程も完全にローカルで実行でき、機密情報を一切外に出しません。
ベクトルデータの保存と更新の仕組み
一度構築したデータベースは、永続的に保存して再利用することが可能です。
- インデックスの作成: 大量のベクトルの中から高速に目的の情報を探し出すために、特殊な索引を作成します。
- メタデータの活用: ベクトルデータと共に、ファイル名や作成日時などの情報を紐付けて登録することで、特定のフォルダ内だけを検索するといったフィルタリングも可能になります。
注釈:Embedding(埋め込み)
テキストをコンピューターが理解できる固定長の数値配列に変換すること。これにより、単語や文章の意味的な類似度を計算できるようになります。
要点:RAGパイプラインは、単なるデータの受け渡しではありません。
- 情報の鮮度
- 検索のヒット率
そして生成される回答の正確性を担保するための一連の高度な処理工程の集合体です。
RAGパイプラインの設計と実装
2026年のローカルAI環境において、RAG(検索拡張生成)の性能を左右するのは、LLM自体の性能よりも、むしろこのパイプラインの設計品質です。
未加工のデータをいかにAIが理解しやすい形式に整え、必要な時に正確に取り出せるかが実装の鍵となります。
データインジェクションと前処理の設計
パイプラインの入り口となるデータの取り込み(インジェクション)フェーズでは、データの「質」を向上させる処理が重要です。
- 多様なフォーマットへの対応: PDFだけでなく、社内のExcel、Markdown、あるいはWebサイトのURLから情報を取得します。
- ノイズの除去: ヘッダー、フッター、広告、あるいは不要な改行コードなどをプログラムで自動的に削除し、AIが文脈を読み取りやすくします。
- メタデータの付与: 各チャンクに「作成者」「最終更新日」「重要度」などの属性情報を付与することで、後の工程で「最新の資料だけを優先して検索する」といった高度な制御が可能になります。
チャンク分割戦略とセマンティック検索
情報をベクトル化する際、文章をどのように区切るか(チャンキング)が、検索結果の的中率に直結します。
- 固定長分割の限界: 単純に「500文字ごと」に区切ると、重要な文の途中で途切れてしまい、意味が通じなくなるリスクがあります。
- 再帰的文字分割: 段落、一文、句読点といった構造を意識して分割し、各チャンク間に一定の重複(オーバーラップ)を持たせることで、文脈の欠落を防ぎます。
- セマンティック・チャンキング: 2026年のトレンドとして、文章の意味の変わり目をAI自身が判断して分割する手法が普及しており、これにより検索精度が飛躍的に向上しています。
リトリーバル(検索)とリランキングの実装
データベースから情報を探す「リトリーバル」工程では、単純な検索を超えた多層的なアプローチが採用されます。
- ハイブリッド検索: 単語の一致を見る「キーワード検索」と、意味の近さを見る「ベクトル検索」を組み合わせ、双方の長所を活かします。
- リランキング(再ランキング): 検索でヒットした上位数件の候補を、別の軽量なAI(リランカー)が再度精査し、質問に対する真の適合順に並び替えます。
- コンテキスト圧縮: 検索された大量の情報から、回答に不要な部分を削ぎ落とし、LLMに渡すプロンプトのサイズを最適化することで、生成速度の向上とコスト削減を図ります。
要点:ローカルLLMの性能評価は、単なる「回答の自然さ」だけではありません。
- 推論速度(トークン/秒)
- コンテキスト保持能力
そしてRAG環境における引用の正確性を数値化して検証することが不可欠です。
ローカルLLM性能の検証と評価
2026年現在、数多くのオープンソースモデルが公開されていますが、自分のPC環境でどのモデルが最適に動作するかを見極めるには、客観的な指標に基づいた検証が欠かせません。
特にRAGを運用する場合、モデルの純粋な知能と、外部情報を処理する効率の両面を評価する必要があります。
推論速度とリソース消費の定量的評価
ローカル環境では、クラウドと異なりハードウェアの制限が直接パフォーマンスに影響します。
- トークン生成速度: 1秒間に何文字を生成できるかの数値です。実務では5〜10t/s以上がストレスのない会話の目安となります。
- 初回応答時間: 質問を入力してから最初の文字が出力されるまでの時間です。RAGでは検索処理が含まれるため、この数値の短縮がユーザー体験を大きく左右します。
- メモリ占有率: 実行中のVRAMおよびシステムメモリの消費量を監視し、他のアプリケーションとの共存が可能かを確認します。
RAG環境における検索精度の検証
RAG特有の評価基準として、検索結果がいかに正しく回答に反映されているかを測定します。
- コンテキスト適合性: データベースから抽出したチャンクが、ユーザーの質問に対して本当に適切な内容か。
- 忠実性: 生成された回答が、検索されたドキュメント内の事実に基づいているか。ハルシネーションが含まれていないかを厳密にチェックします。
- 回答の正確性: 最終的に出力された答えが、人間が用意した正解に近いかどうかを評価します。
日本語能力と専門性の定性的評価
ベンチマークの数値だけでは測れない、実際の使い勝手を検証します。
- 敬語・文体の安定性: ビジネスシーンで使われる適切な表現が維持されているか。
- 長文理解力: 複数のPDFにまたがる複雑な指示を正しく理解し、論理的な構造で出力できるか。
- コード生成・数式処理: 開発業務で用いる場合、構文エラーのないソースコードを書けるか。
注釈:RAGAS RAGシステムの性能を自動で評価するためのフレームワーク。検索の質と生成の質を、LLMを評価者として用いて数値化する手法が一般的です。
要点:ローカルLLMとRAGを組み合わせることで、従来は検索が困難だった社内の非構造化データを「動くナレッジ」へと変えました。
カスタマーサポートから開発、人事まで幅広い業務の劇的な効率化を実現します。
社内ナレッジ活用の具体的活用事例
2026年、多くの企業が直面している情報の属人化やドキュメントの死蔵という課題に対し、ローカルRAGは強力な解決策を提供します。
外部にデータを漏らさないセキュアな環境だからこそ、機密情報を扱う実務に深く踏み込んだ活用が可能です。
カスタマーサポート・テクニカルサポートの高度化
製品マニュアルや過去の問い合わせ対応記録をRAGに学習させることで、サポート品質を均一化します。
- 即時回答の実現: 複雑な仕様書をめくる時間を削減し、AIが数秒で正確な手順を提示します。
- トラブルシューティングの自動化: エラーコード A102といった具体的な入力に対し、過去の修理記録に基づいた解決策を出力します。
- 多言語対応: 日本語の資料を元に、海外拠点のスタッフが英語で質問しても、内容を理解して適切な回答を生成できます。
開発部門における設計・コード資産の継承
過去の設計書やソースコード、社内WikiをRAGのパイプラインに組み込みます。
- レガシーコードの解析: 担当者が不在になった古いプログラムの仕様を、現在のエンジニアがAIに質問して解読できます。
- 設計の整合性チェック: 新しい設計案が、過去の失敗事例や社内の規定に抵触していないかを自動で確認します。
- API利用ガイドの即時参照: 社内限定のライブラリの使い方を、ドキュメントから検索してコード例と共に提示します。

人事・総務・経理のバックオフィスDX
社員が日々行う社内ルールの確認という小さな作業の積み重ねを削減します。
- 就業規則・福利厚生の照会: 育休の手続きはどこでやる?といった質問に対し、最新の規定PDFから該当箇所を引用して答えます。
- 経費精算ルールの自動判定: 領収書の処理方法や、出張手当の計算ルールをマニュアルから正確に取得します。
- オンボーディングの効率化: 新入社員が社内特有の用語や組織について、誰かに聞くことなくAIに試して自己解決できます。

営業・マーケティングのナレッジ共有
競合他社の分析資料や過去の提案書を活用して、勝率を高めます。
- 提案書の自動生成: 過去の成功事例を元に、特定の業界向けの提案文骨子を数分で作成します。
- 競合分析の即時参照: 営業先での急な質問に対し、社内の比較表から最適な切り返しを導き出します。
注釈:非構造化データ PDF、画像、音声、動画、自由記述のテキストなど、特定の形式に整理されていないデータのこと。RAGはこれらを宝の山に変える技術です。

要点:2026年のローカルLLMとRAGは、マルチモーダル化と自律型エージェントの統合により、単なる検索ツールから「自ら考えて行動する実務パートナー」へと劇的な進化を遂げています。
最新トレンドと2026年の展望
2026年現在、ローカルLLMを取り巻く環境は、かつてのテキスト生成のみのフェーズから、より高度で多角的な活用フェーズへと移行しました。
技術の進化は止まることなく、個人のPCや社内サーバーで実行できることの限界を日々更新しています。
マルチモーダルRAGの普及
テキストデータだけでなく、画像や音声、動画を直接処理できるマルチモーダルなローカルLLMが主流となりました。
- 視覚情報のナレッジ化: 過去の設計図面や製品の故障箇所の写真をベクトルデータベースに保存し、この図面の構造に似た過去の不具合事例は?といった質問に回答が可能です。
- 音声・動画の即時参照: 社内会議の録音データや研修動画を自動で文字起こしし、RAGのソースとして利用することで、動画内の特定の時間を指定した回答の抽出も容易になりました。
自律型AIエージェントとの統合
2026年最大のトレンドは、RAGとエージェント機能の融合です。AIが単に答えを探すだけでなく、目的達成のために自らプログラムを書き、実行する段階に達しています。
- 自己完結型タスク実行: 最新の売上PDFを読み込み、グラフを作成して社内共有用のフォルダに保存してという指示に対し、エージェントが自律的にパイプラインを動かします。
- ツールの自動選択: 質問の内容に応じて、ローカルのデータベースを検索すべきか、あるいは計算プログラムを回すべきかをAIが判断します。

エッジデバイスでのRAG実行とプライバシーの極致
PCだけでなく、スマートフォンやシングルボードコンピュータ上でも動作する超軽量な言語モデル(2bや3b)の品質が飛躍的に向上しました。
- 完全オフラインのモバイルRAG: 外出先や電波の届かない現場でも、スマホ内のマニュアルをAIが参照して即座に回答します。
- プライバシーの究極化: インターネットに一度も接続することなく、個人の日記や健康データを元にしたパーソナルアシスタントが完結します。
オープンソースコミュニティの成熟
2025年から2026年にかけて、Hugging Face等のプラットフォームで公開されるモデルの多様性が爆発しました。
- 特定ドメイン特化型モデル: 医療、法律、金融など、特定の業界知識を事前に深く学習した軽量モデルが多数提供され、RAGの回答精度をさらに底上げしています。
- 標準化された評価フレームワーク: 誰もが客観的にモデルの性能を比較できる仕組みが整備され、導入の失敗リスクが大幅に減少しました。
注釈:マルチモーダル(Multimodal) テキスト、画像、音声など異なる種類の情報を統合して処理できる能力のこと。2026年のローカルLLMにおける必須な要素の一つです。

ローカルRAG構築における注意点
要点:インデックスの更新頻度やデータの重複、検索精度のチューニングなど、運用面での課題への対策が不可欠です。
構築が完了した後も、継続的なメンテナンスが重要です。データが古いままだと、AIは間違った情報を答えとして表示してしまいます。
運用上のポイント
- 情報の更新:新しいファイルを追加した際の自動登録の仕組み作り。
- クエリの最適化:ユーザーの入力文を、検索しやすい形に変換する工夫。
- コスト管理:高性能なPCを稼働させる際の時間や電力の管理。
よくある質問(FAQ)
要点:構築や利用に関する疑問を解消し、スムーズな導入をサポートします。
Q1:ローカル環境でRAGを構築するのは難しいですか?
A1:2026年現在、LM StudioやOllamaといった手軽なツールとLangChainを組み合わせることで、基本的な構築は数時間で完了します。
最初は小さなフォルダから試してみるのが良いでしょう。
Q2:日本語の資料でも正しく検索できますか?
A2:はい、日本語に対応したEmbeddingモデルを選択することで、非常に正確な検索が可能です。
QwenやLlama 3の日本語版を使い、ベクトル化の際の言語設定を正しく行うことがポイントです。
Q3:機密情報は本当に安全ですか?
A3:インターネット接続を切断した状態でも動作するため、物理的に外部へ情報が漏れることはありません。
これがクラウドと比較した際の最大のメリットです。

まとめ:ローカルLLMとRAGで未来を創る
要点:技術の進化により、個人や企業が自分たちのデータを安全にAIの力に変えられる時代が到来しました。
本記事では、100%ローカル環境でのLLMおよびRAGの構築方法について解説してきました。
クラウドの利便性も大きいですが、自分たちの手元で自由にAIを活用し、知識を資産化できることの意味は非常に大きなものです。
まずは、自分のPCにPythonをインストールし、今回紹介した手順で最初のステップを踏み出してみてください。
その一歩が、あなたの業務や開発を劇的に変える可能性を秘めています。

公式サイト・リファレンスリンク
- LangChain 公式ドキュメント
- Ollama 公式サイト
- llama.cpp GitHub リポジトリ
- Hugging Face – モデル共有プラットフォーム
- Python 公式ダウンロードページ