
要点:ローカルLLMを快適に動作させるにはGPUのVRAM容量が最も重要です。
最低でも8GB、実用レベルでは16GB以上の搭載が推奨されます。
AI技術の急速な進歩により、OpenAIのChatGPTやGoogleのGeminiといったクラウドサービスを利用するだけではありません。
自分のPC上で大規模言語モデル(LLM)を動かすローカルLLMに注目が集まっています。
ローカル環境でAIを稼働させる最大のメリットは、プライバシーの保護とカスタマイズ性の高さです。外部のサーバーにデータを送信しません。
機密性の高い情報を扱うことが可能になります。
しかし、実際に自宅のPCでLlama 3.1やGemmaなどの最新モデルを動かそうとすると、ハードウェアのスペック不足が大きな壁となります。
この記事では、2026年現在の最新トレンドを踏まえ、推論処理を高速化するために必要なハードウェア構成を詳細に整理して紹介します。

要点:ローカルLLMの動作可否はモデルのパラメータ数と量子化レベル、そしてそれらを格納するVRAMおよびメインメモリの物理的容量によって決定されます。
ローカルLLM必要スペックの概要
ローカルLLMを導入する際、最も重要なのは「自分がどの程度の規模のAIを、どの程度の速度で動かしたいか」という目的を明確にすることです。
AIモデルの知能指数とも言えるパラメータ数(モデルの規模)が大きくなればなるほど、要求されるハードウェアのハードウェアスペックは指数関数的に跳ね上がります。
モデルサイズとVRAM容量の絶対条件
ローカルLLMにおいて、推論速度を実用レベルにするためには、モデルのデータをすべてGPUのビデオメモリ(VRAM)に読み込ませることが基本です。
- 7B(70億)パラメータクラス: 2026年時点でも最も汎用性が高く、日本語能力も高いこのクラスを動かすには、4bit量子化版で約5GBから8GBのVRAMが必要です。
- 14B〜30B(140億〜300億)パラメータクラス: より高度な推論や長文要約が得意なこのクラスには、16GBから24GBのVRAMが必須条件となります。
- 70B(700億)パラメータ以上: クラウドサービスに匹敵する性能を発揮しますが、量子化しても40GB以上のVRAMを消費するため、一般家庭では複数のGPUを搭載するか、Macのユニファイドメモリを活用する構成が現実的です。
量子化技術によるスペックの妥協点
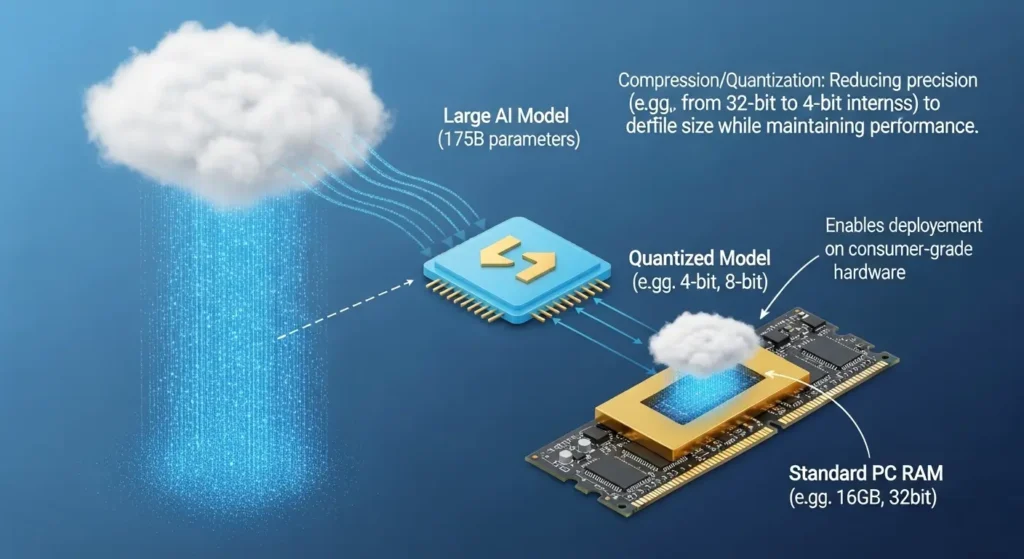
本来、巨大なメモリを必要とするLLMですが、量子化という技術を使うことで、一般家庭のPCスペックでも動かせるようになります。
量子化とは、モデルを構成する数値の精度を16bitから4bitや8bitに圧縮する手法です。
- メリット: 必要なメモリ容量を約4分の1に削減でき、動作速度が大幅に向上します。
- デメリット: 圧縮しすぎると、AIの回答精度や日本語の自然さが若干低下する可能性がありますが、現在の技術では4bit程度であれば実用上の問題はほとんど感じられません。
ストレージと通信環境の注意点
スペックを考える際、メモリ以外に見落としがちなのがストレージ(SSD)の性能と空き容量です。
- SSDの速度: モデルファイルは1つで数GBから数十GBに及びます。これを読み込む際、低速なHDDでは起動に数分かかるため、NVMe接続の高速なSSDの使用が推奨されます。
- ディスク容量: 複数のモデルを試し(試し)ていると、すぐに数百GBの容量を消費します。AI専用のパーティションや追加ドライブの検討が必要です。
注釈:量子化 膨大な計算データを圧縮し、メモリ消費を抑える技術。4bit量子化は、現在のローカルLLM利用において、性能と軽さのバランスが最も良い「黄金比」とされています。
要点:ローカルLLM GPUの選定基準はVRAM容量を最優先とします。
その上で2026年最新のRTX 50シリーズや、マルチGPU構成によるスケーラビリティを考慮することが、長期的な満足度につながります。
ローカルLLM GPUの選定基準
ローカルLLMを動かすためのPCパーツ選びで、最も予算を投じるべきはGPUです。
2026年現在、AIモデルの巨大化に伴い、単純な計算速度よりもどれだけ大きなモデルをメモリに載せられるかが実用レベルの境界線となっています。
VRAM容量:動作可否を分ける絶対指標
GPUに搭載されているビデオメモリ(VRAM)の量は、そのPCで動くモデルのサイズを決定します。
- 12GB〜16GB(エントリー〜ミドル): Llama 3.1 8Bなどの軽量モデルを、高い精度や長いコンテキストで動作させるための目安です。RTX 5070やRTX 5070 Tiが選択肢となります。
- 24GB(ハイエンド・定番): 2026年時点でもRTX 4090は神スペックとして君臨しています。多くの実用的な日本語モデルを快適に動かすためのスイートスポットです。
- 32GB以上(ウルトラハイエンド・最新): 2026年に導入されたRTX 5090は、単体で32GBのGDDR7メモリを搭載しており、これまで複数枚のGPUが必要だった中規模モデルも1枚で稼働可能にしました。
メモリ帯域幅:生成速度(トークン/秒)の鍵
VRAMの量が動作を決めるとすれば、メモリの速度はAIの回答の速さを決めます。
- GDDR7の恩恵: 最新のRTX 50シリーズに採用されたGDDR7は、前世代のGDDR6Xと比較して帯域幅が大幅に向上しています。これにより、大規模なモデルを読み込む際の待ち時間や、推論時の生成速度が飛躍的に高まっています。
- 推論速度の重要性: 文章生成が1秒間に何文字進むかは、実際の使い勝手に大きく影響します。速度を重視するなら、帯域幅の広い上位シリーズの選定が重要です。
NVIDIA CUDA環境の圧倒的優位性
現状、ローカルLLM動作環境を構築する上で、NVIDIA製品以外の選択肢は非常に限定的です。
- CUDAサポート: ほとんどのAIツール(Ollama、LM Studio等)は、NVIDIA専用の演算基盤であるCUDAに最適化されています。
- AMDやMacの現状: AMDのRadeonシリーズもROCmを通じて対応が進んでいますが、設定の難易度やライブラリの安定性の面で、初心者にはNVIDIA製をおすすめします。Macはユニファイドメモリアーキテクチャにより、大容量メモリを扱えるメリットがありますが、純粋な推論速度ではハイエンドGPU搭載PCに軍配が上がります。
注釈:GDDR7 2026年世代のGPUに搭載される超高速なビデオメモリ規格。
データの転送効率が劇的に向上しており、AIの処理能力を支える心臓部となります。

要点:ローカルLLMにおけるCPUは、GPUへのデータ転送や周辺処理を担うだけでなく、VRAM不足時にシステムメモリを活用して推論を継続させる重要なバックアップの役割を果たします。
ローカルLLM CPUの役割と性能
ローカルLLM環境において、演算の主役はGPUですが、システム全体の制御を司るCPUの性能も軽視できません。2026年現在のAI活用シーンでは、GPUとのデータ転送効率や、AVX-512などの拡張命令セットを駆使したCPU推論の重要性が再認識されています。
GPUへのデータ供給と前処理
CPUの最も重要な任務は、ストレージから読み込んだAIモデルをメモリへ展開し、GPUへ効率良く転送することです。
- ボトルネックの解消: CPUのシングルスレッド性能が低いと、GPUへのデータ供給が追いつかず、高性能なビデオカードの性能をフルに発揮できない可能性があります。
- 並列処理の最適化: 最新のRyzenやIntel Coreシリーズは多くのコア数を持っており、トークンの生成前後のテキスト処理を高速化します。
VRAM不足時のバックアップ(CPU推論)
VRAM容量を超えてしまうような大規模なモデルを動かす際、CPUとシステムメモリがその肩代わりをします。
- llama.cppの活用: このツールを使えば、GPUメモリに収まりきらない部分をメインメモリへオフロードして実行可能です。
- 速度とトレードオフ: CPU主体の推論はGPUに比べて速度は大幅に落ちますが、128GBなどの大容量メモリを積んだPCであれば、一般的なGPUでは不可能な超巨大モデルを動かせるというメリットがあります。

最新アーキテクチャとAI命令セット
2025年から2026年にかけてのCPUは、AI処理を加速させるための専用回路を搭載するものが増えています。
- 拡張命令の恩恵: AVX-512やAMXといった命令セットに対応したCPUを選ぶことで、モデルの量子化処理やベクトル計算の効率が向上します。
- 推奨クラス: ローカルLLMをストレスなく扱うなら、Ryzen 7 / Core i7 以上のクラスが目安となります。
注釈:AVX-512 CPUが一度に大量の計算を行うための拡張命令セット。AIの数学的演算を効率化し、CPU推論の速度を底上げする効果があります。

要点:ローカルLLMにおけるメモリは、GPUに搭載されたVRAMとPC本体のシステムメモリ(RAM)の二層構造で機能します。
モデルのロード可否と動作の安定性を決定づける生命線です。
ローカルLLM メモリの重要性
ローカルLLMを実行する際、メモリの容量は計算速度以上に重要視されます。
なぜなら、AIモデルのデータがメモリ内に収まらない場合、エラーが発生してプログラムが起動すらしないからです。
2026年の環境では、
- 16GBが最低ライン
- 32GBが実用ライン
- 64GB以上が快適ライン
として定着しています。
VRAMとシステムメモリの決定的な違い
ローカルLLMの動作環境を構築する上で、二種類のメモリの役割を正しく理解する必要があります。
- VRAM(ビデオメモリ): GPUに直接搭載されている超高速なメモリです。推論(文字の生成)の際、AIモデルがこのVRAM内にすべて収まっていると、非常に高速な回答が得られます。
- システムメモリ(RAM): マザーボードに差し込む一般的なメモリです。VRAMが不足した際、モデルの一部をこちらに逃がす(オフロードする)ことができますが、VRAMに比べて通信速度が遅いため、生成速度は著しく低下します。
量子化モデルとメモリ消費の相関
メモリの必要量は、使用するモデルのパラメータ数と量子化の度合いによって決まります。
- 16GB環境: Llama 3(8B)の4bit量子化版が余裕を持って動作します。OSの消費分を含めても、ブラウザを立ち上げながらAIと対話することが可能です。
- 32GB環境: 2026年の標準的な動作環境です。14Bクラスの中規模モデルや、複数の軽量モデルを同時に起動して比較(比較)検証する際にも安定した稼働(稼働)を実現します。
- 64GB以上の環境: システムメモリだけで数十GB規模の大規模モデルを「動かす」ことが可能になります。GPUのVRAM(24GB)と組み合わせることで、本来は家庭用PCでは動かせないほど巨大なモデルを扱う(扱う)道が開けます。
メモリ速度規格DDR5の恩恵
2026年時点では、DDR4からDDR5への移行が完全に完了しています。
LLMの推論において、メモリの帯域幅(データの通り道の広さ)は速度に直結します。
- 帯域幅の重要性: CPU推論(推論)を行う場合、DDR5-6000以上の高速なメモリを使用することで、DDR4環境と比較して1.5倍から2倍程度のトークン生成速度の向上が見込めます。
- 安定性(安定)への投資: 容量を増やすだけでなく、信頼性の高いメーカー製品を選定(選定)することで、長時間の高負荷処理(処理)時におけるデータ化(化)エラーを最小限に抑えることができます。
注釈:オフロード GPUのVRAMに収まりきらないデータを、一時的にシステムメモリ(RAM)へ肩代わりさせること。動作は継続できますが、速度は低下します。

要点:2026年現時点のローカルLLM市場では、Meta社のLlamaシリーズやAlibaba系のQwenなど、高性能なOSSモデルが百花繚乱の状況です。
FP16や量子化形式の選択がベンチマーク結果を大きく左右します。
最新OSSモデルのベンチマークと比較
ローカル環境で使えるAIモデルは、2025年から2026年にかけて、クラウド型のGPT-4クラスに匹敵する品質へと進化しました。
各開発元の設計思想により、特徴や得意分野が異なります。
主要モデルの性能一覧と特徴
現時点で主要なモデルのスペックと特徴は以下の通りです。
- Llama 3シリーズ(Meta): Facebookを運営するMeta社が公開。英語・日本語の両方で高い性能を発揮し、2bや3bといった軽量型から本格的な大規模モデルまで揃っています。
- Qwenシリーズ(Alibaba Cloud): 2026年に注目を集めているQwenは、コーディングや数学的推論において非常に正確な回答を出すのが最大の特徴です。
- Gemma(Google): Googleが提供するオープンなモデルで、軽量ながら推論速度が速く、特定のタスクに特化させたカスタマイズに適しています。
量子化形式(FP16/INT4)による品質の変化
モデルをダウンロードする際、ファイル名の最後に表記されているFP16やQ4_K_Mといった形式に注目してください。
- FP16(非量子化): データの欠落がない最高品質ですが、VRAMを大量に消費するため、十分なスペックを持つPC以外では動作が困難です。
- Q4 / Q5(量子化): メモリ制約がある一般的なPCでも、少しの精度低下と引き換えに、長い文章の生成や高速な処理を実現します。実際、多くの人がこの形式を使っています。
購入前に参考にすべき情報
高価なGPUを搭載したPCを株式会社の業務や個人で導入する前に、実際の動作報告を確認しましょう。
- ベンチマークサイト: 実際の生成速度(トークン/秒)をモデルごとに一覧化しているサイトを参考にしてください。
- 価格と性能のバランス: 数十万円の投資を行う際、Proレベルの作業に耐えうるか、自分の用途に十分な性能かを見極めることが重要です。
要点:2026年のローカルLLM構築は、高度なGUIツールの普及により「専門知識不要」で開始できる時代となりました。
プライバシーを完全に保護しながら、自分専用のAIアシスタントを自宅で安全に運用するための具体的な手順を解説します。
LLM 自宅での動作環境構築
自宅でローカルLLMを動かすための環境構築は、一昔前のような複雑なコマンド操作を必要としません。
2026年現在、主要なソフトウェアはWindowsやMacに最適化されており、インストールから数分でAIとの対話が可能です。
初心者向け:LM Studioによる直感的な構築
非エンジニアの方や、まずは気軽に試したい方に最適なのが「LM Studio」です。
- 導入のステップ: 公式サイトからインストーラーをダウンロードし、画面上の検索バーからLlama 3やGemmaといったモデルを探すだけです。
- スペックの自動判定: 自分のPCのVRAMやメモリ容量を自動で認識し、動作可能な量子化レベルを推奨してくれるため、選定ミスが起きません。
- プライバシーの確保: インターネットから切り離された完全なオフライン環境でチャットが実行されるため、情報の漏洩を気にする必要はありません。
開発者・中級者向け:OllamaとDockerの活用
システムを他のアプリと連携させたり、サーバーとして運用したい場合は「Ollama」がデファクトスタンダードです。
- ワンラインでの起動: コマンド一つで最新のモデルをプルし、APIサーバーとして稼働させることができます。
- Open WebUIとの連携: Dockerを使用してOpen WebUIを導入すれば、ブラウザ経由でChatGPTのような使い勝手の良いインターフェースを自宅環境に構築できます。
- マルチモデルの管理: 複数のモデルを瞬時に入れ替えながら、タスクごとに最適なAIを使い分ける高度な運用が可能です。
セキュリティと長期運用のポイント
自宅で24時間安定してAIを動かし続けるための注意点です。
- 熱対策と電源: LLMの推論はGPUに大きな負荷をかけるため、PCケース内の排気を整理し、余裕のあるワット数の電源ユニットを選定することが重要です。
- データのバックアップ: 自分で調整したパラメータやチャット履歴は、定期的に外部ストレージやクラウドへ保存しておくと安心です。
- 利用規約の遵守: オープンソースモデルであっても、商用利用や再配布に関する規約はモデルごとに異なります。導入前に必ずライセンスを確認しましょう。
注釈:API(Application Programming Interface) ソフトウェア同士が情報をやり取りするための窓口のこと。
Ollamaなどが提供するAPIを利用することで、自作のアプリやWebサイトからローカルAIを呼び出すことができます。
要点:ローカルLLMの推奨スペックは、
- テキスト生成のみか
- 画像生成も含めるか
あるいは大規模モデルの推論を行うかという目的別に明確な階層が存在します。
ローカルLLM 推奨スペックの一覧表
2026年現在のAI技術環境に基づき、ローカルLLMを動かすための推奨スペックを目的別に整理しました。
スペック選びのポイントは、VRAM容量を軸に、メモリやCPUのバランスを整えることにあります。
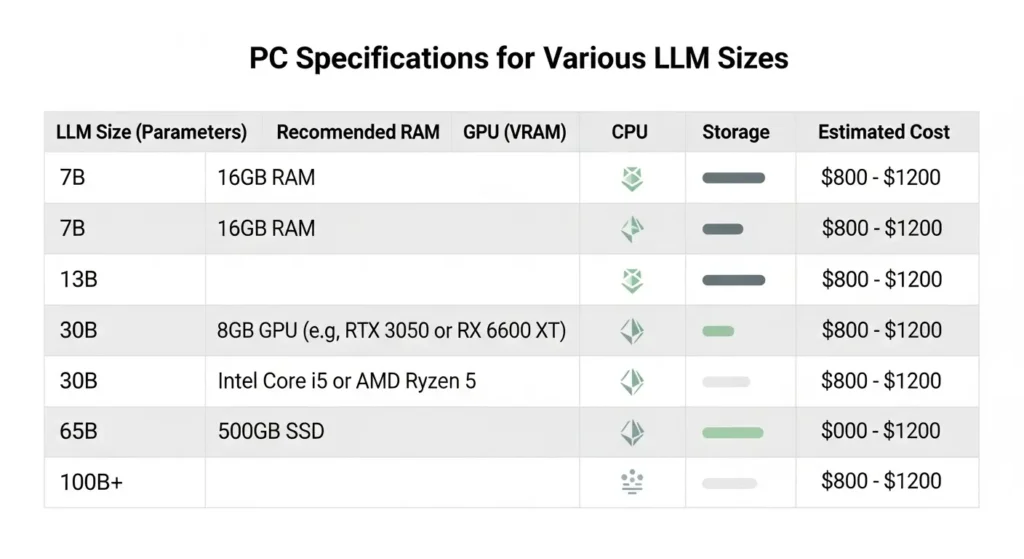
目的別・推奨ハードウェア構成表
自身の用途が
- 「学習・研究」なのか
- 「日常的なアシスタント」なのか
によって、投資すべきパーツが変わります。
| 利用レベル | ターゲットモデル | 推奨GPU | 推奨メモリ | 推奨ストレージ |
| ライト級 | 1B〜8Bクラス (Llama 3, Gemma) | RTX 4060 / 5060 (VRAM 8GB以上) | 16GB以上 | 500GB SSD |
| スタンダード | 14B〜32Bクラス (Command R, Mistral) | RTX 4070 Ti / 5070 (VRAM 16GB以上) | 32GB以上 | 1TB NVMe SSD |
| プロフェッショナル | 70B以上 / 画像生成併用 | RTX 4090 / 5090 (VRAM 24GB〜32GB) | 64GB以上 | 2TB NVMe SSD |
| ウルトラ(自宅サーバー) | 100B超モデルの推論 | RTX 5090 × 2枚 または Mac Studio (M4 Ultra) | 128GB以上 | 4TB以上 |
ノートPCとデスクトップPCのスペック比較
持ち運びを重視するか、拡張性を重視するかで選定基準が異なります。
- ノートPC(Laptop): GPU搭載(dGPU)モデルが必須です。2026年モデルのゲーミングノートやクリエイター向けノートは、16GB以上のVRAMを搭載した製品が増えていますが、熱による性能低下に注意が必要です。
- デスクトップPC(Desktop): パーツの交換が可能なため、将来的にVRAMがさらに必要になった際、GPUを追加・交換できるメリットがあります。電源ユニットは、上位GPUの稼働を支えるために850W〜1200Wクラスが推奨されます。
Appleシリコン(Mac)の特殊なスペック要件
Mac(Mac Studio / MacBook Pro)は、Windows機とは異なるメモリ管理(ユニファイドメモリ)を採用しています。
- メモリの共通化: CPUとGPUが同じメモリ(RAM)を共有するため、128GBのメモリを積んだMacであれば、その大部分をAIモデルのロードに充てることが可能です。
- 推奨モデル: M3/M4 Max以上のチップを搭載し、メモリは最低でも64GB以上を選択するのが、ローカルLLM環境として実用的な構成となります。
注釈:ユニファイドメモリ
CPUとGPUが物理的に同じメモリチップにアクセスする仕組み。
データのコピーが発生しないため、大規模なAIモデルの処理において非常に高い効率を発揮します。
ローカルLLMに関するよくある質問
要点:導入時の疑問を解消し、電力消費や騒音といった運用面の注意点を把握することで、トラブルを未然に防げます。
Q: ノートPCでもローカルLLMは動きますか?
A: はい、可能です。
ただし、ゲーミングノートPCのような高性能GPU(RTXシリーズ)を搭載していることが条件です。
薄型のビジネスノートPCでは、CPU推論になるため非常に低速になります。
また、実行中はファンが高回転になり、高い熱が発生するため、冷却対策も気にする必要があります。
Q: MacBookでの動作はどうですか?
A: Appleのシリコン(Mシリーズ)を搭載したMacは、ローカルLLM実行において非常に優秀です。
特にメモリを多く搭載したモデルなら、24GB以上のVRAMに相当する処理をユニファイドメモリで実行できるため、Windows機よりも大規模なモデルを動かせる場合があります。
Q: 電源ユニットは何ワット必要ですか?
A: RTX 4090などのハイエンドGPUを使用する場合、システム全体で850Wから1000W以上の高品質な電源が推奨されます。
AIの推論時はGPUがフル稼働するため、消費電力が大きく増加します。

まとめ:自分に最適なAI環境を自宅に
要点:2026年はローカルLLMの黄金期であり、VRAM 16GB以上の環境を整えることで、大半のオープンソースモデルを自在に操ることが可能です。
本記事では、ローカルLLMを動かすためのスペック情報について、GPUの重要性を中心に解説してきました。
技術の進化により、かつては巨大なサーバーが必要だった大規模言語モデルが、今や個人のPC上で稼働する時代です。
プライバシーを守りながら、自分専用にカスタマイズされたAIを持つことは、今後の開発や創作活動において大きなアドバンテージとなります。
まずは、自分の今持っているPCでGemma 2やLlama 3の軽量版を試しに動かしてみてください。
動作の遅さを感じたら、それはスペックアップを検討する最高のタイミングです。
今後も新しいモデルが続々と公開されますが、大容量のVRAMとメモリを持った構成であれば、長期にわたって最新のAI技術を享受できるはずです。

公式サイト・リファレンスリンク
- NVIDIA 公式サイト:AIおよびディープラーニング向けGPU
- LM Studio 公式サイト
- Ollama 公式サイト
- Hugging Face(AIモデルの共有プラットフォーム)
- GitHub:llama.cpp リポジトリ