
ローカルLLM導入で未来を掴む
要点:2026年現在、プライバシー保護とコスト削減を両立するローカルLLMは、ITエンジニアや研究者にとって不可欠なツールとなっています。
最近、ChatGPTやClaudeといったクラウド型aiを利用する中で、機密情報の送信や従量課金のコストに不安を感じたことはありませんか。
多くのプロフェッショナルが抱えるこの悩みに対し、今、明確な解決策として提示されているのがローカルLLM(大規模言語モデル)の構築です。
手元のpc環境でaiを動かすことは、単なるトレンドではありません。
自社のデータを守りながら知能を拡張する実務的な変革を意味します。
本記事では、
- 2026年最新のおすすめモデル
- 失敗しない環境構築のポイント
を徹底解説します。
最後まで読むことで、あなたに最適なローカルai環境が明確になるはずです。
ローカルLLMの基礎知識と2026年の動向
要点:ローカルLLMはPC内部で完結して動くため、情報漏洩のリスクを極限まで低減し、業務効率化を加速させる強力なツールです。
近年、AI技術は急速に進化し、従来のクラウド型AI(ChatGPTやGeminiなど)に加え、手元のPCで動作するローカルLLM(Large Language Model)が注目を集めています。
特に2026年は、モデルの軽量化(圧縮技術)が進んだことで、一般のデスクトップPCやノートPCでも高品質な回答を得られる状況が整いました。

なぜ今ローカル環境が必要なのか
最大の理由は、インターネット接続を介さないことによる安心感です。
クラウドサービスでは入力データが学習に利用される可能性がゼロではありませんが、ローカル版であれば社外秘のプロジェクトや顧客情報を含む作業も、情報の外部送信なしに実行できます。
また、従量課金によるコストを気にせず、24時間使い放題となる点も大きな魅力です。
ローカルLLM 比較:2026年版おすすめモデル一覧
要点:用途やPCスペックに応じ、Llama、Mistral、Phiなどの代表的なモデルから自分に合ったものを選定しましょう。
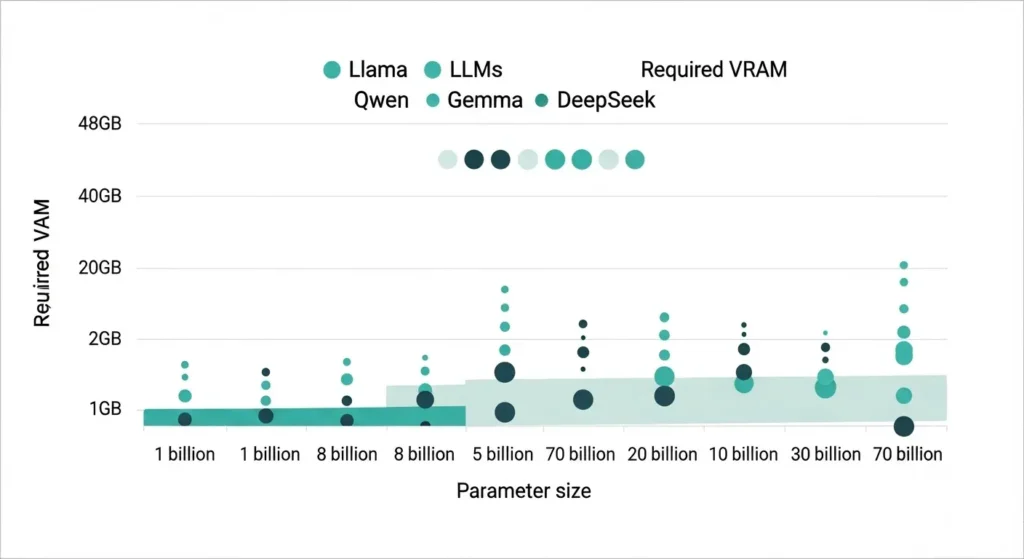
ローカルLLM 比較を行う際、まず確認すべきはモデルのパラメータ数と推奨メモリ容量です。
2025年から2026年にかけては、比較的小さなsmallモデルでありながら、多言語対応に優れた高品質なモデルが豊富に登場しています。
推奨モデルの選定ガイド
- Llama 3.3 (Meta): 世界的に最も人気があるシリーズ。幅広い用途に適しており、特に長文の要約や複雑な指示の理解に強いのが特徴です。
- Mistral 7B / 12B (Mistral AI): 高いパフォーマンスと効率性のバランスが魅力。エンジニアの間でも評価が高く、カスタマイズ性が抜群です。
- Phi-3 / Phi-4 (Microsoft): 4bや2bといった非常に小さなサイズでありながら、推論能力が高いモデルです。8GB RAM程度のPCでも比較的スムーズに動くため、試しに導入してみたい初心者に向いています。
- Qwenシリーズ (Alibaba): 多言語能力に優れ、特に日本語の自然な翻訳やチャットにおいて、同等のサイズの他モデルと大きな違いを見せます。

ローカルLLM比較とモデル選定
要点:2026年のローカルLLM選定では、
- パラメータ数
- ライセンス
- 日本語対応精度
の3点を軸に、自分のpcスペック(特にvram)と照らし合わせることが成功の鍵です。
現在、Hugging Faceなどのプラットフォームで公開されているモデルの数は数万を超えています。
初心者が自分に合ったものを選ぶのは容易ではありません。
しかし、2026年現在の主要なシリーズを理解すれば、目的に対して最適なモデルを絞り込むことができます。
ローカルLLM 比較の主要指標
モデルを比較する際、以下の3つの基準を意識してください。
- パラメータ数(サイズ): 1b(10億)〜70b(70億)など。数が多いほど高性能ですが、動作に必要なメモリ量も増えます。
- アーキテクチャ: Dense(密)型かMoE(混合専門家)型か。DeepSeekなどに採用されるMoE型は、推論速度と精度のバランスに優れています。
- ベンチマークスコア: MMLU(知識)やHumanEval(コード生成)などの指標。ただし、実際の日本語での使い心地とは必ずしも一致しない点に注意が必要です。
2026年おすすめの主要モデルシリーズ
実用性が高く、エンジニアから高い評価を得ているモデルを具体的に紹介します。
- Llama 3.2 / 3.3シリーズ (Meta): 世界で最も普及しているオープンウェイトモデルです。3.2の1b/3bといった小型モデルはスマートフォンのようなデバイスでも動作し、3.3の70bはGPT-4oに匹敵する能力を持ちます。エコシステムが最も充実しており、困った時の情報が多いのが最大のメリットです。
- Qwen 2.5 / 2.6 (Alibaba Cloud): 2025年から2026年にかけて、世界中のベンチマークを塗り替えた驚異的なシリーズです。特に32bや72bといったサイズでは、数学やコーディング能力においてトップクラスの性能を誇ります。日本語の扱いも非常に安定しています。
- Gemma 2 (Google): Googleが開発した軽量かつ高性能なモデルです。9bサイズでありながら、他社の14b〜20bクラスに相当する知識量を持ちます。短いプロンプトに対する応答のキレが良いのが特徴です。
- DeepSeek R1: 推論プロセスを明示的に出力する思考型モデルです。数学の難問や論理パズル、複雑なプログラミングのデバッグにおいて、従来のモデルとは一線を画す解決能力を見せます。
日本語特化モデルの重要性
英語ベースのモデルを日本語で使うと、時折不自然な表現や「ハルシネーション(嘘の回答)」が発生しやすくなります。
そのため、CyberAgentやELYZAといった国内企業が公開している日本語継続学習済みモデルを選択肢に入れることも重要です。
これらは日本の文化や法律、特有の言い回しを理解しているため、社内業務での文章作成や要約において、非常に高い満足度を得られます。
量子化フォーマットの選び方
ローカルLLM モデルをダウンロードする際、
- 「GGUF」
- 「EXL2」
- 「AWQ」
といった形式が並んでいます。
- GGUF: OllamaやLM Studioで最も広く使われる形式。CPUとGPUの両方を活用でき、最も安定しています。
- EXL2: GPU専用ですが、生成速度が極めて高速です。
自分のハードウェア環境(GPUかMacか)に合わせて、これらのフォーマットを適切に選ぶことが、快適な推論環境を構築する最後のステップとなります。
ローカルLLM GPUとCPUの役割
要点:ローカルLLMの動作速度と精度は、計算処理を担うGPUとシステム全体を統括するCPUの連携、そしてそれらを支えるメモリ帯域に大きく左右されます。
ローカルLLM 構築を検討する際、最も大きな投資(コスト)が必要となるのがハードウェアです。
特にAIの「推論」処理において、GPUとCPUがそれぞれどのような役割を果たすのか?
どちらに比重を置くべきか?
この2つを理解することは、失敗しないデバイス選びの第一歩となります。
GPU(グラフィックスプロセッシングユニット)の圧倒的役割
AIの演算は、膨大な数の単純な行列計算で構成されています。これに最適なのが、数千個のコアを持つGPUです。
- 推論速度の向上: NVIDIA製のGeForce RTXシリーズ(3060, 4060 Ti, 4090など)は、AI専用のTensorコアを搭載しており、CPUとは比較にならない圧倒的な速度を実現します。
- VRAM(ビデオメモリ)の重要性: GPU 推論において最も重要な指標は「VRAM容量」です。モデルの全パラメータをVRAM内に読み込み(load)できれば、1秒間に生成されるトークン数は最大化されます。2026年現在、16GB以上のVRAMを持つグラフィックボードが、中規模モデルを動かすための実質的な基準となっています。
- CUDAとエコシステム: NVIDIA製GPUが選ばれる最大の理由は、CUDAと呼ばれる並列計算プラットフォームの存在です。多くのオープンソース(OSS)ライブラリやツールがNVIDIA向けに最適化されており、トラブルが少なく安定した動作が期待できます。
CPU(中央演算処理装置)とRAMの役割
GPUが「計算機」なら、CPUは「監督」の役割を担います。
- システム全体の管理: モデルの読み込み、プロンプトのテキスト解析(トークナイズ)、結果の表示制御などはCPUが行います。
- メインメモリ(RAM)へのフォールバック: VRAM容量が不足した場合、モデルの一部をPCのメインメモリに配置して動作させることが可能です。これを「オフロード」と呼びますが、メインメモリはVRAMに比べてデータ転送速度(帯域幅)が極めて低いため、推論速度は大幅に低下します。
- AVX-512等の命令セット: CPU 推論を行う場合、IntelやAMDの最新CPUが持つ高度な命令セットが活用されます。GPUがないノートPCやサーバー環境では、CPUの性能が直接的に生成速度に影響します。
Apple Silicon(Mac)というハイブリッドな選択
2026年のトレンドとして無視できないのが、AppleのM2/M3シリーズです。
Macのチップは「ユニファイドメモリ(統合メモリ)」を採用しております。
CPUとGPUが同じメモリプールを共有します。
- 大規模モデルへの対応: Windows機では24GBのVRAMが限界であるケースが多い中、64GBや128GBのメモリを積んだMacであれば、70bクラスの巨大なモデルを単体で動かせるという独自の強みがあります。
- 電力効率: 消費電力が低く、静音性に優れているため、オフィスや自宅での長時間運用に向いています。
最適なハードウェアバランスの考え方
予算が限られている場合、まずは「VRAM容量が大きいGPU」を最優先してください。
CPUは中堅クラス(Core i5やRyzen 5以上)であれば、推論速度のボトルネックになることはほとんどありません。
一方で、ストレージ(SSD)の速度も重要です。数十GBのモデルファイルを高速に読み込むためには、NVMe規格の高速なSSDを搭載することが、快適なローカルAIライフを送るための隠れたポイントとなります。
ローカルLLM環境構築のおすすめツール
要点:2026年現在は、OllamaやLM Studioといった「ワンクリックで導入可能」なツールが普及しました。
構築のハードルが劇的に下がっています。
Ollama おすすめの理由
Ollama(注釈:コマンドラインベースの軽量な実行エンジン)は、エンジニアに最も支持されているツールです。
コマンド一つでモデルのダウンロードから実行まで完結します。
apiサーバーとしても機能します。
そのため、自社開発のシステムにaiを組み込むpoc(概念実証)に最適です。
apache 2.0ライセンスなどの下で配布されるモデルを、コマンドラインから手軽に扱える利便性は、一度体験すると元には戻れません。
LM Studio おすすめのポイント
LM Studio おすすめの理由は、その直感的なgui(注釈:マウスで操作できる画面)にあります。
hugging face(注釈:aiモデルの世界最大級の共有サイト)からモデルを探してくだsだい。
pcのスペックに合っているかを確認しながら導入できます。
特定の技術的知識がなくても、視覚的にパラメータを調整できます。
そのため、デザイナーやライターといった非エンジニア層にも広く利用されています。
2026年のローカルAI活用術
要点:2026年のローカルAI運用は、単なるチャット(対話)を超え、推論ループを持つ自律型エージェントやマルチモーダル解析が実務の主役に躍り出ています。
2026年現在、ローカルLLM 構築の目的は「AIと話すこと」から「AIに仕事を完結させること」へと大きくシフトしました。
OpenAIなどのクラウドサービスが進化を続ける一方で、あえて手元のハードウェアでAIを動かす理由は、その「圧倒的な自由度」と「秘匿情報の絶対的な保護」にあります。
ここでは、最新のトレンドに基づいた具体的な活用手法を解説します。
自律型AIエージェントによる業務自動化
2026年の最大の特徴は、AIが自ら考え、複数のステップを実行する「エージェント化」です。
- 推論ループの搭載: 最新のDeepSeek R1やLlama 3.3(Instruct版)は、回答を出す前に「思考プロセス(Chain of Thought)」を内部で行います。これにより、複雑な数学の難問や論理パズルの正解率が飛躍的に向上しました。
- マルチエージェント連携: CrewAIやLangGraphといったフレームワークを活用し、一つのpc内で「法務担当AI」「広報担当AI」「校正担当AI」といった複数の専門家を連携させ、議事録の作成からプレスリリースの下書きまでを一気に完了させるフローが一般的になっています。
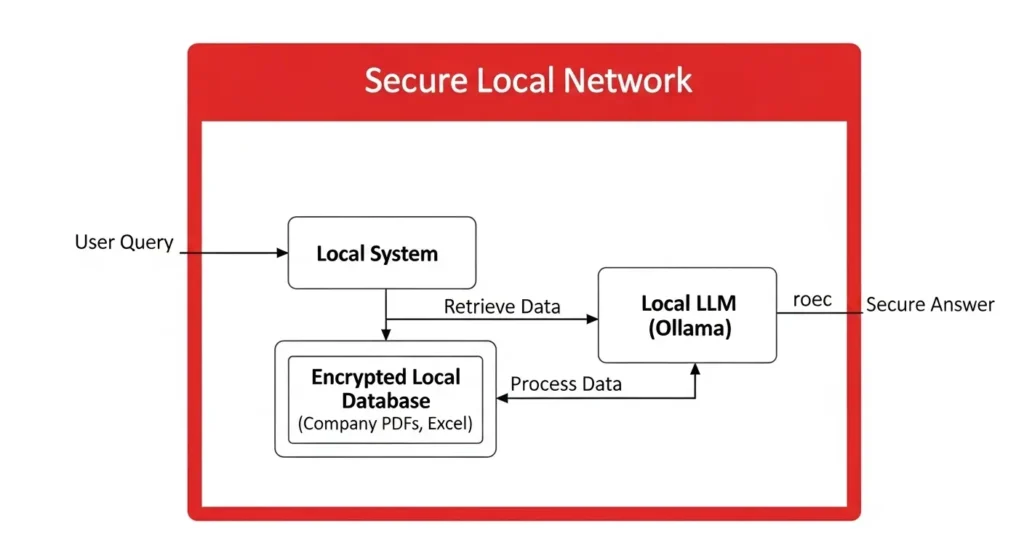
ローカルRAG(検索拡張生成)の高度な運用
社内ドキュメントを参照するRAGは、2026年において「精度」と「セキュリティ」を両立させるための必須技術となりました。
- Graph RAGの普及: 従来のベクトル検索だけでなく、文書間の関係性をグラフ構造で保持する「Graph RAG」がローカルでも実用化されています。これにより、「このプロジェクトの遅延の根本原因は?」といった、複数の文書にまたがる複雑な文脈理解が可能になりました。
- 機密文書の自動匿名化: 3月時点の最新事例では、ローカルLLMが読み込んだ文書内の個人情報や顧客情報を検知し、自動でマスキング処理を行う機能が注目されています。これにより、これまで社外秘扱いでAIに入力できなかった契約書なども、安全に解析できるようになりました。
マルチモーダル解析による現場変革
テキストだけでなく、画像、音声、動画を同時に扱うマルチモーダル(注釈:複数の種類の情報を統合して処理する能力)がローカルの標準となりました。
- 製造業の品質管理: 工場内のカメラ映像をエッジデバイス(注釈:現場に設置された小型計算端末)のローカルLLMで解析し、リアルタイムで異常検知や製品の検査を行う事例が増えています。
- 医療・法務分野の高度化: 大量のレントゲン画像や証拠資料のpdfを一度に読み込み、視覚的な変化や文章の矛盾点を数秒で特定するタスクが、インターネット接続なし(完全オフライン)で実現されています。
2026年版:運用コストとリソースの最適化
投資(コスト)を抑えつつ、最高の結果を得るための戦略的な選び方が求められています。
- SLM(小型言語モデル)の活用: 1b〜3bの小さなモデルであっても、ファインチューニング(注釈:特定のデータで追加学習させること)を施すことで、特定分野では大規模モデルに匹敵する能力を発揮します。
- 従量課金からの脱却: クラウドAIへの支払いを月額固定の電気代とハードウェア代に置き換えることで、大規模なデータ処理を行う企業ほど、1年〜2年スパンでのコスト削減効果が明確になっています。
このように、2026年のローカルAI活用術は、個人の生産性を上げるツールから、企業の意思決定を支える「閉域網内の脳」へと進化しました。
適切なモデルとハードウェアを組み合わせることで、あなたは外部のリスクに怯えることなく、最先端の知能を独占することができるのです。
失敗しないローカルLLM 導入手順
要点:成功の秘訣は、最初から最高スペックを求めず、段階的なステップアップ(PoC)を通じて自社の業務に最適なバランスを見極めることです。
ローカルLLM 導入において、多くの担当者が陥る失敗が「過剰なハードウェア投資」や「複雑すぎる初期設定」での挫折です。2026年現在のトレンドに基づき、最短距離で実用的な環境を手に入れるためのステップバイステップガイドを解説します。
ステップ1:目的の明確化とユースケースの選定
まず、なぜローカル環境が必要なのかを定義します。
- 解決したい課題: 議事録の要約、ソースコードの補完、あるいは法務・財務の機密文書解析など、特定分野に絞ることでモデル選定が容易になります。
- セキュリティポリシーの確認: 社内の情報セキュリティ規定を改めてチェックし、入力データが外部経路へ送信されない「閉域網環境」の要件を整理おきしましょう。
ステップ2:最小構成(MVP)での試験運用
いきなり100万円単位の予算をかける前に、手元のデバイスや安価なプランで「概念実証(PoC)」を行います。
- Ollamaのインストール: 公式サイトからインストーラーをクリックし、数分でセットアップを完了させます。
- 軽量モデルの試行: 1bや3bといった小さなサイズのモデル(Gemma 2やLlama 3.2)を動かし、推論速度や日本語の自然さを体験します。これにより、必要なハードウェアスペックの概算がつかめます。
ステップ3:ハードウェア選定とシステム構築
PoCの結果に基づき、本格的な運用に向けたパーツを選定します。
- GPUの購入: NVIDIA GeForce RTX 4060 Ti(16GB)や4090(24GB)など、目的のモデルがVRAM内に収まるデバイスを優先的に選びます。
- OSとドライバーの準備: WindowsであればWSL2環境、LinuxであればUbuntuなどが、各種ライブラリとの互換性が高くおすすめです。最新のNVIDIAドライバーをインストールし、CUDAのバージョンが適切であることを確認してください。

ステップ4:高度なカスタマイズと運用管理
環境が整ったら、実務レベルの精度を高めるためのチューニングを行います。
- RAGの組み込み: 自社独自のナレッジベース(PDFやデータベース)を統合し、AIが「知らないことは知らない」と言える、ハルシネーションの少ない環境を作ります。
- API経由での連携: OllamaやLM Studioが提供するOpenAI互換APIを活用し、既存のチャットツールや社内システムと接続します。
- 継続的なメンテナンス: モデルは日々進化します。新しいモデルの「重み」ファイルが登場した際、スムーズに差し替え(更新)が行える体制を整えておくことが重要です。
導入時に注意すべき「隠れたコスト」
ハードウェア代以外にも、
- 消費電力
- 冷却システムの騒音
- 保守に関わる人件費
などがランニングコストとして発生します。
法人向けに大規模なクラスターを組む場合は、クラウド上での運用と比較して、どちらが中長期的にコストメリットがあるかを改めて計算(シミュレーション)しておくことを推奨します。
2026年のローカルAI活用術と注意点
要点:翻訳、コード生成、長文要約など、業務に合わせた独自のプロンプトを保存しておくことで、生産性はさらに向上します。
ローカルLLM モデルを導入した後は、いかに実務に組み込むかが重要です。
- 翻訳の強化: 自社特有の用語集をプロンプトに入れ、多言語対応のモデル(Qwenなど)を使うことで、外部の翻訳サービスより高品質な結果が得られる可能性があります。
- 非公開データの要約: 議事録や未発表の企画書など、クラウドに上げられない情報を中心に処理させる使い方が最も効果的です。
運用上の注意点
- 回答の検証: AIは時としてもっともらしい嘘(ハルシネーション)をつくため、重要な判断を下す際は必ず人間による確認が必要です。
- 最新情報の不足: ローカルモデルは学習時のデータに基づいているため、今日のニュースなどのリアルタイムな質問には、RAG(検索拡張生成)などの仕組みを追加しない限り答えられません。
よくある質問と回答
要点:導入時に多くの人が直面する疑問に対し、専門的な視点から回答します。
8GBのRAMでも動かせますか?
はい、phi-3などのsmallモデルや、2bサイズの軽量モデルであれば、8GBのメモリでも動作します。
ただし、複数のアプリを同時に立ち上げると動作が重くなる傾向があります。
そのため、不必要なプログラムを閉じて作業することをおすすめします。
インターネット接続は全く不要ですか?
モデルのダウンロード時のみ通信が必要ですが、一度保存してしまえば、以降のチャットや推論作業は完全にオフラインで行えます。
場所を選ばず、飛行機の中やセキュリティの厳しい閉域網内でも利用可能です。
ノートPCでもローカルLLMは動きますか?
はい、最新のゲーミングノートやmacbook proであれば十分に動作します。
ただし、長時間の推論は発熱を伴うため、冷却ファンなどの対策を講じるのが良いでしょう。
特にnvidia製gpuを搭載したモデルであれば、14bクラスのモデルも実用的な速度で動かせます。
ハルシネーション(嘘の回答)は防げますか?
100%排除することは難しいですが、前述のRAGを用いることで、根拠となる文書をaiに示し、正確性を飛躍的に高めることが可能です。
また、最新の「instruct」モデルを使用します。
プロンプトで「分からないことは分からないと答えて」と指示することも重要です。
セキュリティパッチやモデルの更新はどうすればいいですか?
ローカルLLMもソフトウェアである以上、定期的なアップデートが欠かせません。
実行エンジン(Ollamaなど)のバージョンアップはもちろん、Hugging Faceで配布されているモデルファイルの「最終更新日」をチェックします。
精度が向上した新しい版へ切り替えることで、常に最先端の恩恵を受けられます。
導入失敗を避けるための「相談」先はありますか?
個人開発者であればGitHubのコミュニティやRedditでの情報収集が有力です。
企業であれば、PoCの伴走支援を行っている専門家や、株式会社としての実績を持つコンサルティング会社へ相談することで、初期の技術的ハードルを迅速に突破できます。
商用利用に費用はかかりますか?
モデルのライセンス(llamaは一定のユーザー数まで無料、apache 2.0は完全無料など)によります。
多くのオープンソースモデルは、小規模〜中規模のビジネスであれば実質無料で利用可能ですが、各モデルのライセンス条項を必ず事前にチェックしてください。

まとめ:あなた専用の知能をその手に
要点:2026年は、ローカルLLMが「一部のマニア向け」から「実務の標準」へと変わる節目の年です。
ローカルLLM おすすめのモデルやツールを知ることは、単なる知識の習得ではありません。
あなたのキャリアやビジネスにおける圧倒的な優位性を築く第一歩です。
プライバシーを守り、従量課金のストレスから解放された環境で、最新の言語モデルを使いこなす。
この新しい自由を手に入れるために、まずは今日、OllamaやLM Studioをインストールして、小さなモデルを一つ動かしてみることから始めてみてください。
そこには、インターネットの壁を超えた、あなただけの広大な知能の領域が広がっています。