
ローカルLLM導入で変わるAI活用
要点:ローカルLLMとは、外部のクラウドサービスを介さず、自社のPCやサーバー上で大規模言語モデルを実行する技術であり、機密情報の保護に最適です。
最近、ChatGPTやGoogleのGeminiといった生成AIの進化には目を見張るものがあります。
しかし、企業や個人開発者がこれらのサービスを利用する際、入力したデータが外部へ送信されることによる情報漏洩のリスクを懸念する声が高まっています。
そこで注目されているのがローカルLLMです。
自社のハードウェア内で推論を完結させるこの手法は、まさにプライベートLLMとしての価値を持ち、機密情報を扱う業務において不可欠な存在となりつつあります。
本記事では、
- ローカルLLMとは何かという基礎知識
- 構築方法
- メリット・デメリット
まで、2026年の最新トレンドを踏まえて徹底解説します。
ローカルLLM導入のメリットとデメリット
要点:ローカルLLMの導入は、機密情報の保護やコストの固定化といった大きなメリットがある一方で、ハードウェアへの初期投資や運用リソースの確保というデメリットも存在します。
2026年現在、企業がAI活用を本格化させる中で、クラウドサービスへの依存を脱却し、自社専用のローカル環境を構築する動きが加速しています。
導入を成功させるためには、その「光と影」を正しく理解し、自社のニーズに合致しているかを精査することが不可欠です。
導入する5つの大きなメリット
1. 究極のプライバシーとセキュリティ
外部のサーバーにデータを送信しないため、個人情報や開発中のソースコード、未発表の経営戦略などを安全にAIへ入力できます。
クラウド型AIで懸念される「入力データの再学習利用」というリスクを物理的にゼロにできる点は、企業ガバナンスにおいて最大の強みです。
2. 月額コストの固定化と削減
クラウドAI(ChatGPT Plusや各種API)は利用量に応じて従量課金が発生しますが、ローカル環境は一度PCを構築してしまえば、かかるのは電気代のみです。
24時間365日、どれだけ大量のタスクを投げても追加費用が発生しないため、大規模なデータ処理を行うほどコストメリットは大きくなります。
3. 圧倒的なカスタマイズの自由度
特定の業務知識を反映させるRAG(注釈:検索拡張生成)や、自社専用のトーン&マナーを学習させるファインチューニングを制限なく行えます。
また、llama.cppなどの軽量な推論エンジンを活用することで、特定のハードウェアに最適化された独自のAIアシスタントを構築可能です。
4. オフライン動作と安定性
インターネット接続が不安定な場所や、セキュリティポリシーにより外部接続が遮断された閉域網でもAIが動作します。
クラウド側のサーバーダウンやメンテナンスによる業務停止の影響を受けないため、24時間稼働の製造ラインや医療現場でも安定した運用が可能です。
5. 超低遅延なレスポンス
ネットワーク通信(HTTPリクエスト等)を介さないため、高性能なGPUを搭載した環境であれば、プロンプトを入力した瞬間に回答が生成されるほどの低遅延を実現できます。
これは、リアルタイムな音声対話や、瞬時のコード補完を求めるエンジニアにとって極めて大きな利点です。
把握しておくべきデメリットと制約
高額な初期投資(ハードウェアコスト)
最新のLlama 3.3やDeepSeek-R1などの大規模なモデルを快適に動かすには、NVIDIA RTX 4090などのハイエンドGPUや、大容量のVRAM(ビデオメモリ)を搭載したPCが必要です。
1台あたり数十万円から、構成によっては数百万円の投資が必要になるケースもあります。
2. ハードウェア選定と運用の専門知識
適切なモデル(パラメータ数)に対して、どれだけのメモリ容量が必要かを見極める知識が求められます。
また、
- ドライバの更新
- 量子化(注釈:データを圧縮して軽くする技術)の最適化
- 排熱管理
など、システムを健全に保つためのメンテナンス作業も自社で行わなければなりません。
3. 技術進化のスピードへの追従
AIモデルの進化は非常に速く、最新のアルゴリズムが発表されるたびに環境をアップデートする必要があります。
クラウドサービスであれば自動で最新版に更新されますが、ローカル環境では常に自分たちで情報をキャッチアップします。
モデルを入れ替える手間が発生します。
4. 消費電力と物理的な設置場所
高性能な計算を行うため、PCは大量の電力を消費します。
熱を発します。
サーバーを常時稼働させる場合は、電気代の増加だけではありません。
冷却のための空調設備や、ファンの騒音に対する物理的な配慮も必要になります。
5. モデルサイズの物理的限界
クラウドAI(GPT-4クラス)は、数テラバイト規模の超巨大な計算リソースで動いています。
これと全く同等の性能を、一般企業のPC1台で実現するのは現時点では困難です。
ローカル環境では、目的(タスク)に応じて「必要十分なサイズ」のモデルを選定する取捨選択が求められます。
2026年におけるメリットの深化
2026年現在のトレンドとして、メリットの質が以下のように変化しています。
マルチデバイス連携の容易化
以前は単体のPCでしか使えなかったローカルLLMですが、現在はOllamaなどをサーバーとして機能させることで、社内のスマートフォンやタブレット、ノートPCから一つの高性能PCにあるAIを共有利用する「ホームサーバー型」の運用が容易になっています。
エッジデバイスへの最適化
Apple Silicon(M4/M5チップ)などの急速な進化により、これまではデスクトップ級のGPUが必須だった高度な推論が、薄型のノートPCでもストレスなく実行できるようになりました。
これにより「持ち運べる高度なプライベートAI」という新しい価値が生まれています。
エネルギー効率の劇的な改善
2025年後半から登場したモデルは、パラメータを大幅に削減(圧縮)しても性能を維持する「スリム化」が極限まで進んでいます。
これにより、かつてデメリットとされていた消費電力の問題が大幅に緩和され、家庭用電源でも24時間安定して運用できる実用性が確立されました。
ローカルLLM環境構築の具体的な方法
要点:2026年現在のローカルLLM環境構築は、専門的なコマンド操作を必要とする手法から、ボタン一つで完了するアプリケーションまで幅広く、目的とスキルに応じた選択が可能です。
かつてはLinuxの深い知識や複雑なライブラリ管理が必須だったLLM 環境構築ですが、現在はツール群の進化により、個人のPCでも短時間でセットアップを完了できるようになりました。
ここでは、現在主流となっている4つの具体的な構築アプローチを、推奨スペックとともに詳しく解説します。
初心者向け:GUIツールを活用した導入
プログラミングの経験がない方や、まずは手軽に最新モデルを動かしてみたい方に最適な方法です。
- LM Studio: Hugging Faceと直接連携し、モデルの検索、ダウンロード、実行を一つの画面で完結できます。PCスペックに合わせた推奨量子化版(注釈:モデルのデータ精度を調整して軽量化する技術)を自動で提示してくれるため、失敗がありません。
- GPT4All: 非常にシンプルなUIが特徴で、インターネット接続がない環境でもインストーラー一つでセットアップが完了します。比較的スペックの低いノートPCでも動作するように最適化されています。
エンジニア・開発者向け:CLIツールによる構築
API連携や自動化、詳細なパラメータ調整を行いたい場合に選ばれる、現在最も勢いのある手法です。
- Ollama: macOS、Linux、Windowsのターミナルからコマンド一つでLlama 3.3やMistral、Qwenなどの最新モデルを起動できます。バックエンドでサーバーとして常駐するため、後述するLangChainなどとの連携が非常にスムーズです。
- llama.cpp: C++で書かれた極めて軽量な推論エンジンです。Apple Silicon(Mシリーズ)の性能を限界まで引き出したり、GPUがないPCのCPUリソースを最大限に活用したりする場合に必須となるツールです。
本格的な開発・研究向け:Python環境とライブラリの利用
自社の独自データを読み込ませたり、複雑なワークフローを構築したりするための、エンジニア向けの正攻法です。
- Hugging Face Transformers: 世界標準のライブラリを用いて、モデルをプログラムコード(Python)から直接呼び出します。最新の論文で発表されたアルゴリズムを即座に試すことが可能です。
- LangChain / LlamaIndex: ローカルLLMを自社のPDFやデータベースと接続し、RAG(検索拡張生成)を実現するためのフレームワークです。これにより、AIが「自社専用のナレッジ」に基づいて回答するようになります。
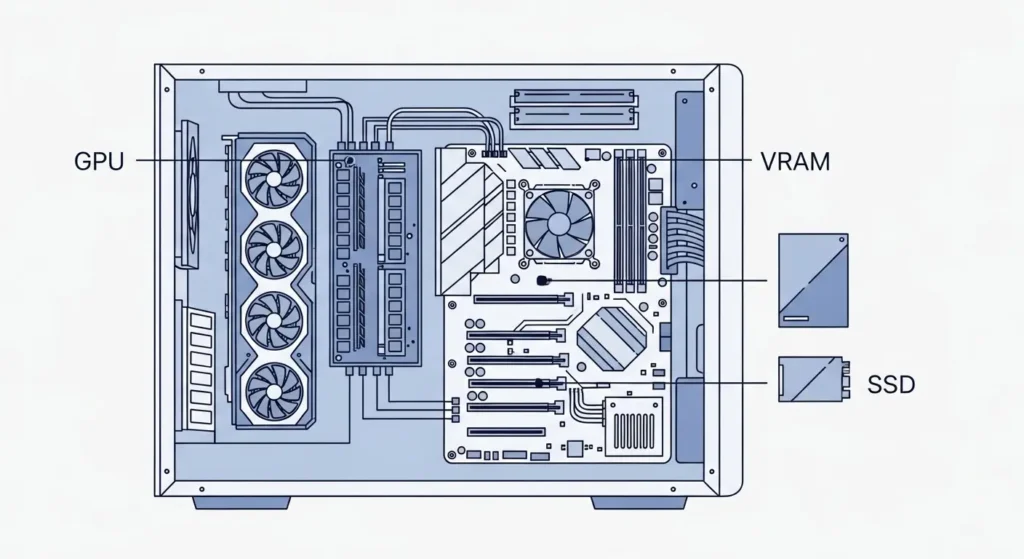
構築を成功させるハードウェア要件とOSの選択
PCスペックの選定は、構築方法以上に重要なポイントです。
- OSの選択: WindowsであればWSL2(注釈:Windows上でLinuxを動かす仕組み)を活用するのが、開発効率とパフォーマンスのバランスが良くおすすめです。Macであれば、M2以降のハイエンドモデルを選ぶことで、GPU 推論の恩恵を最大限に受けられます。
- メモリ(VRAM)の確保: ローカルLLM 推論のボトルネックは、常にVRAM容量にあります。例えば、7b(70億パラメータ)のモデルを動かすなら12GB以上、70bクラスを狙うなら24GB以上のVRAM、あるいはMacのユニファイドメモリが必要です。
2026年最新の構築テクニック
従来の解説記事にはない、2026年時点での「一歩先を行く」構築手法を紹介します。
MCP(Model Context Protocol)によるアプリ連携
Anthropicが提唱し、オープンソース界隈で急速に普及したMCPを活用することで、ローカルLLMがあなたのPC内のブラウザやファイルエディタ、カレンダーを直接操作できるようになります。
構築時にMCPサーバーを立ち上げておくことで、単なるチャットボットから「あなたの代わりに作業するエージェント」へと進化します。
分散コンピューティングによるリソース共有
社内にある複数のPCのGPUリソースをネットワーク経由で束ね、一つの巨大なLLMを動かす「Petals」のような分散構築手法が、中堅企業のDX現場で採用され始めています。
高価なサーバーを一台買うのではなく、チーム全員のPCの余剰パワーを合わせるという、新しいコスト削減の形です。
エネルギー効率を最大化する「低電圧推論」
2026年のトレンドとして、電力消費を抑えつつ24時間常時稼働させるための設定が注目されています。
Pythonスクリプトによる電圧制御と、量子化モデルの組み合わせにより、電気代を抑えながら「常に声をかけられるAIサーバー」を自宅や社内に構築するノウハウが確立されています。
2026年のローカルLLMを取り巻く状況
要点:2026年、ローカルLLMは企業のデジタル基盤として定着し、OpenAI等のクラウドサービスと使い分けるハイブリッド運用が一般的になっています。
AI技術の急速な拡大に伴い、多くの会社が自社のインフラ上で動作するオンプレミス型のAI活用を推進しています。
背景には、機密情報の取り扱いに関する厳しいコンプライアンスや、個人情報保護の観点から外部送信を避けたいというニーズがあります。
実際、2025年から2026年にかけて、国内の金融分野や医療業界を中心に、高度なセキュリティ対策を備えたローカルLLMの導入事例が急増しました。
本記事の目次をご覧いただければ、なぜ今ローカル環境が求められているのか、その概要と具体的な構築手順を詳しく学ぶことができます。

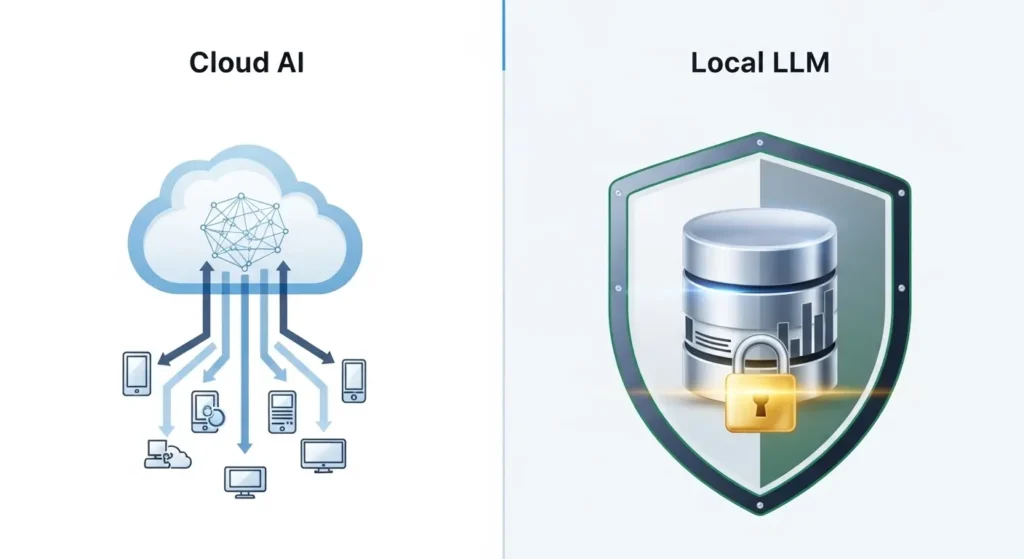
ローカルLLMとクラウドの決定的な違い
要点:ローカルLLMとクラウドAIの決定的な違いは「データの所在」と「計算リソースの占有権」にあります。
これがセキュリティとコストの差を直接的に生み出します。
ローカルLLM(Large Language Model)とは、ChatGPTに代表されるクラウド型サービスとは異なります。
自分自身のPCや自社が所有するサーバー内でAIモデルを動かす形態を指します。
2026年現在、多くの企業がオンプレミス(注釈:自社内にサーバーを設置・運用する形態)でのAI活用を推進していますが、その背景にはクラウドサービスでは解決できない構造的な差異があります。
データの所在:外部送信か、完全隔離か
クラウドAIを利用する場合、私たちが入力した質問やデータは、インターネットを経由してベンダー(OpenAIやGoogle、Microsoftなど)のサーバーへと送信されます。
一方、ローカルLLMでは、推論(注釈:AIが答えを導き出す計算処理)のすべてが手元のハードウェア内で完結します。
- クラウドの状況: データが社外のインフラを通過するため、たとえ暗号化されていても、情報の取り扱いに関する透明性やガバナンス(注釈:企業による統制)の面で懸念が残ります。
- ローカルの状況: PCのLANケーブルを抜いた状態でもAIが動作するため、機密情報が外部に漏れる経路が物理的に存在しません。これが金融や医療といった機密性を最優先する分野で採用される最大の理由です。
計算リソースの占有:共有か、独占か
クラウドAIは世界中のユーザーが一つの巨大なサーバー群を共有しています。
そのため、ピーク時には応答が遅くなったり、サービス側の障害によって業務が完全に停止したりするリスクがあります。
ローカルLLMは、PCのGPU(グラフィックスプロセッシングユニット)やCPUのリソースを自分一人で独占して使用します。
- クラウドの制約: 混雑時に「トークン(文字の最小単位)」の出力速度が制限されることがあります。
- ローカルの利点: ハードウェアの性能が許す限り、常に一定の高速レスポンスを維持できます。また、サービス側の利用規約変更や突然の料金改定、サービス終了の影響を受けずに、自社のインフラとして継続して使い続けることが可能です。
料金体系:従量課金か、固定資産か
決定的な違いは、財布への影響にも現れます。
- クラウド型: 使うほどに課金される従量制や、高額な月額プランが一般的です。大量のデータ分析や24時間稼働のbot運用では、コストが予測しにくく膨らみがちです。
- ローカル型: 最初にPCやサーバーを購入する予算(初期コスト)はかかりますが、導入後の利用料金は実質無料(電気代のみ)です。数年スパンで考えれば、投資回収効果(ROI)が非常に高く、予算管理が容易になります。
2026年におけるハイブリッド運用の正解
これまでの解説サイトでは「どちらか一方を選ぶ」という視点が中心でしたが、2026年の実務現場ではハイブリッド運用が主流となっています。
クリエイティブはクラウド、分析はローカル
一般的な市場調査や多言語翻訳など、ネット上の最新知識を必要とするタスクには、OpenAI等の強力なクラウドサービスを利用。
一方で、社内の売上データ分析や未発表製品のキャッチコピー作成にはローカルLLMを適用する、という「データの重要度に応じた自動切り分け」が、専用のソフトウェア基盤によって自動化されています。
開発コストの劇的な逆転
かつてはローカル構築の方が人件費や技術的なハードルが高いとされてきましたが、2026年現在はDocker(注釈:アプリを簡単に動かすためのコンテナ技術)やOllamaの普及により、導入手順が極めてシンプルになりました。
その結果、複雑なAPI連携のコードを書くよりも、ローカルに環境をインストールして自社ツールと直結させる方が、開発期間を短縮できるという逆転現象が起きています。
LLM セキュリティと機密情報の扱い
要点:企業においてLLM セキュリティは最優先事項であり、ローカル環境はガバナンスを維持するための究極のソリューションです。
クラウドサービスを利用する場合、利用規約(注釈:サービス提供者との契約ルール)によっては、入力したプロンプトがモデルの再学習に利用される可能性がゼロではありません。
これが、多くの企業が導入を躊躇する最大の理由です。
プライベートLLMによるリスク回避
- 情報漏洩の防止: 顧客情報やソースコードを外部のサーバーに送信する必要がありません。
- アクセスコールの制御: 誰が、いつ、どのような情報をAIに聞いたかのログを社内ストレージに保存し、監査が可能です。
- コンプライアンス遵守: 法務や財務など、厳しい規制がある業界でもAIの恩恵を安全に受けることができます。
LLM オフライン環境の価値
物理的にインターネットから切り離された環境でも動作するため、サーバー攻撃や不正アクセスによるデータ流出のリスクを物理的に最小限に抑えられます。
これは、製造業の設計部門や医療機関など、絶対的な秘匿性が求められる現場において、最高の結果をもたらします。
最新のモデル比較とライセンスの注意点
要点:MetaのLlamaシリーズやMistral、GoogleのGemmaなど、高性能なオープンソースモデルが次々と登場しています。
2025年から2026年にかけて、ローカルLLM モデルの進化は加速しています。どのモデルを選ぶかは、目的(タスク)と手元のPCスペックに応じて判断する必要があります。
主要なローカルLLM 比較
- Llama 3.2 / 3.3 (Meta): 汎用性が高く、日本語能力も向上。70bなどの大規模モデルは非常に高い精度を誇ります。
- Mistral 7B / 12B (Mistral AI): 軽量ながらも強力で、カスタマイズがしやすいため人気です。
- Qwen 2.5 (Alibaba): コーディングや数学的な計算において圧倒的な性能を示します。
- Phi-3 / Phi-4 (Microsoft): 4b程度の小規模なパラメータ数でありながら、特定のタスクでは大規模モデルに匹敵します。
ライセンスと商用利用の確認
オープンソース(OSS)といっても、すべてが完全に自由なわけではありません。
Apache 2.0やMITライセンスのものもあれば、商用利用に際して一定の条件があるモデルもあります。
導入の前には、必ずライセンス条項を確認する体制が必要です。

LangChainを活用したローカルLLMの高度な運用
要点:LangChainを用いることで、ローカルLLMは単なるチャットボットから、自社のデータベースや社内文書を自在に操る自律的なAIエージェントへと進化します。
2026年現在、ローカルLLM 構築の最終目的地は「独自のナレッジを活用した自動化」にあります。
これを実現するための強力な基盤がLangChain(注釈:LLMを用いた高度なアプリケーション開発を支援するオープンソースのライブラリ)です。
LangChainを導入することで、モデルそのものが持っていない専門知識を補完し、実務レベルの正確な回答を得ることが可能になります。
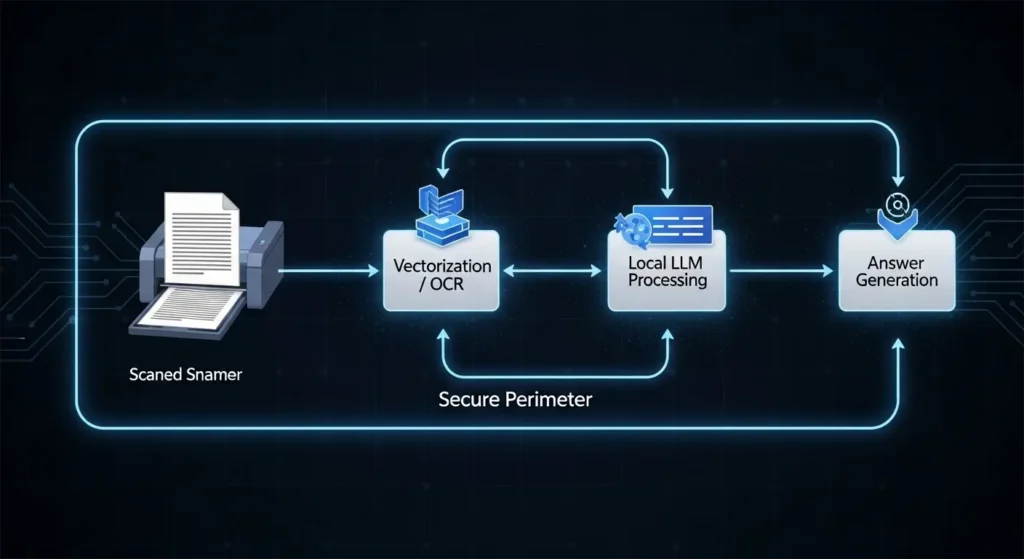
1. RAGによる専門知識の拡張
ローカルLLMは学習時点のデータしか持っていませんが、RAG(注釈:検索拡張生成。必要な情報を外部から取得して回答に反映させる手法)を適用することで、最新の社内情報を踏まえた回答が可能になります。
- 情報の読み込み: 自社のPDF、Excel、マークダウン形式の資料をLangChainで読み込みます。
- ベクトル化と検索: 情報をベクトル化(注釈:AIが計算できる数値に変換すること)してデータベースに保存。ユーザーの質問に関連する断片を瞬時に探し出します。
- 文脈に基づいた回答: 探し出した情報を「コンテキスト(背景情報)」としてローカルLLMに渡し、回答を生成させます。これにより、ハルシネーション(注釈:AIがもっともらしい嘘をつく現象)を劇的に軽減できます。
2. マルチステップなタスクの自動化(エージェント機能)
LangChainの「エージェント」機能を活用すれば、AIに道具(ツール)を渡すことができます。
- SQL実行と分析: AIが自らローカルのデータベースに対してSQLを発行し、売上の推移を分析。
- Pythonコードの実行: 複雑な数学的計算が必要な際、AIがその場でPythonプログラムを書いて実行し、正確な数値を算出。
- ブラウジング連携: 2026年最新の動向を自らローカルの検索エンジン経由で調べに行き、その結果を整理して報告。
3. メモリ機能による長期的な一貫性の保持
通常のAPI利用では会話ごとに文脈がリセットされがちですが、LangChainのメモリ機能を使えば、過去のやり取りやユーザーの好みをローカルのデータベースに保存します。
継続的な学習に近い体験を実現できます。
これにより、「前回の会議の続きから話そう」といった、人間同士のようなスムーズな連携が可能になります。
2026年におけるLangChain×ローカルAIの進化
従来のコラムでは語られていなかった、2026年ならではの高度な活用法を紹介します。
ローカル専用エージェント「MCPサーバー」との統合
2026年のトレンドであるMCP(Model Context Protocol)とLangChainを組み合わせることで、ローカルLLMがあなたのPC内のカレンダーやメールソフト、ファイルエディタを直接操作する環境を、わずか数行のコードで構築できるようになりました。
これにより、スケジュール調整から報告書のドラフト作成まで、完全にオフラインで完結します。
マルチモーダルRAGの実現
テキストだけでなく、社内の図面画像やプレゼン資料のスクリーンショットをベクトル化して検索対象に含める「マルチモーダルRAG」が実用化されています。
LangChainの最新モジュールを用いることで、言葉では説明しにくい設計図の仕様を、画像を参照しながら日本語で解説させることが可能です。
独自性3:エネルギー効率を考慮した「動的モデル切り替え」
タスクの難易度に応じて、LangChainが背後のモデルを自動で切り替えます。
簡単な挨拶やスケジュール確認には超軽量な2bモデル(低消費電力)を、複雑な財務分析には高性能な70bモデル(高負荷)を呼び出すことで、PCの電力消費と推論時間を最適化する賢い運用が普及しています。
企業がローカルLLMを導入するためのステップ
要点:小規模なPoC(概念実証)から始め、段階的にハードウェアや人材を整備していくアプローチが成功の鍵です。
- ユースケースの特定: どの部門のどの作業を効率化するかを明確にします。
- スペックの選定: 必要なモデルのサイズに応じたVRAM容量を確保します。
- 環境構築とテスト: Ollamaやllama.cppを用いて試行錯誤を行い、レスポンス速度を検証します。
- 全社展開と教育: セキュリティルールの周知と、プロンプトエンジニアリング(注釈:AIから良い回答を引き出すための指示の出し方)の研修を実施します。
よくある質問と回答
要点:導入時に多くの人が抱える疑問を解消し、スムーズな検討を支援します。
ノートPCでもローカルLLMは動きますか?
はい、最新のMacBookやゲーミングノートPCであれば、7b(70億パラメータ)程度の軽量なモデルであれば十分に動作します。
ただし、長時間の実行は発熱を伴うため、安定した運用にはデスクトップPCが向いています。
日本語での対応は完璧ですか?
Llama 3以降のモデルは日本語の理解力が大幅に向上していますが、やはり英語に比べると精度が落ちる場合があります。
その際は、日本語に特化したファインチューニング済みモデル(例:ELYZAなど)を選択することをおすすめします。
情報の更新はどうすればいいですか?
ローカルLLMは学習時点のデータしか持っていません。最新情報に対応させるには、前述のRAG(検索拡張生成)を導入します。
AIが最新のドキュメントやWeb上の情報を参照できるようにする設定が必要です。
構築中に「メモリ不足」のエラーが出た場合は?
最も一般的なトラブルです。原因はモデルのサイズがVRAMに入り切っていないことです。
解決策として、よりビット数の低い量子化版(例:Q8からQ4へ)をダウンロードするか、モデルの一部をCPUにオフロード(分担)させる設定に変更してください。
WindowsとMac、どちらが構築しやすいですか?
手軽さで言えばMacです。ユニファイドメモリのおかげで、特別な設定なしに大規模なモデルを動かせます。
一方で、カスタマイズ性や最新のライブラリへの対応速度、そしてコストパフォーマンスを重視するなら、NVIDIA製GPUを搭載したWindows(WSL2)環境に軍配が上がります。
2026年のローカルAIトレンド
要点:2026年のローカルAIは、単なる「回答ツール」から、自らタスクを完遂する「自律型エージェント」や、画像・音声をネイティブに扱う「マルチモーダル」へと進化を遂げています。
2024年から2025年にかけてのローカルLLMブームを経て、2026年現在は技術の成熟期に入りました。
かつては「クラウドAIの代替」でしかなかったローカル環境が、今やクラウドには真似できない独自の価値を持つようになっています。
ここでは、今押さえておくべき3つの主要トレンドを解説します。
エージェント型AI(Agentic AI)の普及
2026年の最大の変化は、AIがプロンプトに対してテキストを返すだけでなく、自らPC内のツールを操作して仕事を完結させる「エージェント化」です。
- 自律的な問題解決: 例えば「先月の売上データをExcelから抽出してグラフ化し、メールで送っておいて」という指示に対し、ローカルLLMが自ら複数のステップを構築し実行します。
- MCP(Model Context Protocol)の標準化: ローカルAIがファイルシステムやカレンダー、ウェブブラウザを安全に操作するための共通規格が普及し、導入のハードルが劇的に下がりました。
ネイティブ・マルチモーダルとSLMの台頭
テキストだけでなく、画像や音声を直接理解する「マルチモーダル」能力が、軽量なモデル(SLM)にも標準搭載されるようになりました。
- SLM(小型言語モデル)の高性能化: 1b〜3b(10億〜30億パラメータ)程度の極めて小さなモデルでありながら、2024年当時の巨大モデルに匹敵する知能を持つようになりました。これにより、スマートフォンのようなモバイル端末やエッジデバイス(注釈:現場の小型端末)上でも、画像解析を伴う高度な推論が可能です。
- リアルタイム画像検査: 製造現場では、カメラ映像をローカルLLMがリアルタイムで監視し、異常を検知した瞬間に指示を出す「見逃しゼロ」の検査体制が、インターネット接続なしで実現されています。
クラウドとローカルの「ハイブリッド運用」の標準化
すべてのAI処理をローカルで行うのではなく、用途に応じて使い分ける「ハイブリッド構成」が企業の標準となっています。
- 機密情報の切り分け: 顧客データや財務分析、特許に関わる深い思考は「ローカルLLM」で秘匿性を担保。一方で、一般的な市場調査やクリエイティブなアイデア出しには、より巨大な知能を持つ「クラウドAI」を併用します。
- コストと遅延の最適化: 頻繁に発生する定型タスクをローカルで処理することで、クラウドのAPIコストを大幅に削減しつつ、ネットワーク遅延のない快適な作業環境を実現しています。
結論:今こそローカルLLMでAIを自社資産に
2026年のビジネスシーンにおいて、AIはもはや外部から「借りる」ものではありません。
自社内に「所有」する資産へと変わりつつあります。
ローカルLLMとは、単なる技術的な選択肢ではありません。
- 情報の安全性
- コストの最適化
そしてイノベーションのスピードを左右する経営戦略そのものです。
情報漏洩の懸念を理由にAI導入を諦める必要はありません。
本記事で解説した導入方法やメリットを踏まえ、まずは小規模な環境構築から始めてみてはいかがでしょうか。
手元のPCでAIが動き出し、自社専用のナレッジを語り始めたとき、あなたのビジネスは真のDXへと踏み出すことになるでしょう。

公式サイト・関連リンク
- Meta Llama 3 公式サイト
- Mistral AI 公式サイト
- Ollama – Get up and running with Llama 3
- Hugging Face – The AI community
- LangChain Documentation
- llama.cpp – GitHub
- NVIDIA CUDA Toolkit
内部リンク