- 「自分だけのオリジナルのAIイラストを生成したい」
- 「既存のStable Diffusionのモデルにはない、特定のキャラクターや服装を再現したい」
そう思って、LoRAの作り方に興味を持たれたのではないでしょうか。
LoRA(ローラ/Low-Rank Adaptation)は、画像生成AIの世界で最も革新的な技術の一つです。
この技術を使えば、大規模な学習を必要とするモデル作成とは違います。
あなたのPC(Windows、Mac問わず)のVRAMリソースが少ない場合でも、特定のスタイルやキャラクターを再現できる追加学習モデルを作成する方法を知ることが可能になります。
しかし、いざ作り方を調べてみると、「環境構築が難しそう」「設定項目が多すぎる」と途中で挫折してしまいそうになります。
ご安心ください。
今回の記事は、2025年最新の情報に基づき、Windows PC、Mac PCユーザー、そしてAIイラストの初心者でも、最後まで迷うことなく、自分だけの高品質なLoRAを自作し、Stable DiffusionのWeb UIで使えるようになる完全ガイドです。
- 必要な知識
- 環境構築
- 学習方法の手順
- 失敗しない設定のコツ
そして商用利用の注意点まで、全てを体系的に解説します。
さあ、あなただけのオリジナルモデルを作成し、AIイラストの表現の幅を広げていきましょう!
LoRAの基礎知識
LoRAの仕組みとメリット
LoRAとは?少ないリソースでもできる仕組み
LoRA(ロー・ランク・アダプテーション)は、大規模言語モデル(LLM)の学習効率を向上させるために開発された技術です。
Stable Diffusionのような画像生成AIに適用することで、既存のモデル(Checkpointファイル)の画風を変えることなく、特定の要素(キャラクター、服装、ポーズ、絵柄など)を追加で学習させることが可能になります。
通常のモデル学習(ファインチューニングやDreamboothなど)では、数十GB以上の大きなVRAM容量と長い時間が必要でした。
しかし、LoRAは差分ファイルという小さいデータ(数MB~数百MB程度)を既存のモデルに上乗せする形で機能するため、VRAM 8GBや12GBのPCでも比較的簡単に学習を実行できます。
少ないリソースで作成できることが、LoRAの一番の特徴です。
個人のクリエイターに広まった理由です。
LoRAモデル自作のメリット
| メリット | 詳細 |
| 好きなキャラクターの再現 | 既存のモデルに存在しない、あなたの好きなアニメやゲームのキャラを生成することが可能です。 |
| オリジナルスタイルの作成 | あなた自身の絵柄や写真の雰囲気を学習させ、誰とも違う唯一無二のAIイラストを作れるようになります。 |
| 商用利用の自由度 | 自作したLoRAは、ライセンスの制限を気にすることなく、収益化や副業に活用できる可能性が高まります。 |
| 知識・技術の習得 | 学習の仕組みを理解することで、プロンプトの調整スキルやトラブル解決能力が大幅に向上します。 |
LoRA作成の全体像
LoRA 学習方法を紹介
LoRAの作り方を簡単に試そう!ステップごとの進め方
LoRAの作り方は、大きく分けて以下の3つのステップで完了します。
| ステップ | 作業内容 | ツール・知識 |
| ステップ1: 環境構築 | 学習用ツール(Kohya’s GUIなど)をPCに導入し、必要なファイルを用意します。 | Python、Git、Anacondaなど |
| ステップ2: データセット作成 | 学習元となる画像を集め、キャプション(タグ)を付けます。 | AIタグ付けツール(WD1.4 Taggerなど) |
| ステップ3: 学習・出力 | Kohya’s GUIでパラメータを設定し、学習を実行してLoRAファイルを生成します。 | Kohya’s GUI、VRAM、Learning Rateなど |
この記事では、初心者が一番難しいと感じる「ステップ1」と「ステップ2」を特に丁寧に解説します。
LoRA作成に必要な準備
必要な作業とツール一覧
Stable Diffusion LoRA 作り方を開始するために、必要なものを一覧にまとめました。
| 項目 | 詳細と推奨 |
| PCスペック | VRAM 12GB 以上の NVIDIA GPU(GeForce RTX 3060や4060以上)を搭載したPCが推奨されます。8GBでも可能ですが、設定を工夫する必要があります。 |
| 学習ツール | Kohya’s GUI(Kohya’s Stable Diffusion webui)が最も一般的で機能が豊富です。 |
| 環境構築ツール | Python(3.10.11など、特定のバージョンが推奨)、Git、Anaconda(またはvenv) |
| データセット | 学習させたい対象の画像(20枚~100枚程度) |
| タグ付けツール | WD1.4 TaggerやDeepBooruなど、画像に自動でキャプションを付けるツール(Kohya’s GUIに内蔵されている場合もあります) |
必要なGPUスペック LoRA学習にはGPUが必須です。特にVRAM(GPU専用メモリ)の容量が重要で、学習時間や設定の自由度に大きく影響します。
- 推奨:VRAM 12GB以上(RTX 3060、4060、4070系列)
- 最低:VRAM 8GB(設定で
--lowvramなどを使う必要があります) - SDXL モデルのLoRAを作る場合:VRAM 16GB 以上(RTX 4090、A100など)
注釈(VRAM): Video RAM(ビデオラム)の略称で、GPU(グラフィックボード)専用のメモリのこと。AIの学習や画像生成の際に大きなデータを一時的に保存する場所で、容量が不足するとエラーになったり、処理速度が遅くなります。
PCのスペックが不足している方は、高性能なGPUをインターネット経由で利用できる「GPUクラウドサービス」の利用を強く推奨します。(→ GPUSOROBAN公式サイト])
ステップ1:環境構築
AnacondaのインストールとKohya’s GUIの導入の環境づくり
LoRAの学習方法の中で、環境構築が最も挫折しやすいところです。
ここではWindowsを中心に、初心者でも確実に成功する手順を解説します。
- Gitのインストール: GitHubからKohya’s GUIのソースコードをダウンロードするために必須です。(→ [サイト外リンク:Git公式サイト])
- Anacondaのインストール:Pythonのバージョン管理を簡単に行うため、Anacondaのインストーラー(.exe)をダウンロードして導入します。
- 仮想環境の作成:Anaconda Promptを開き、Python 3.10.11を使った新しい仮想環境を作ります。
Bash
conda create -n lora-train python=3.10.11
conda activate lora-train
- Kohya’s GUIのダウンロード:GitHubからリポジトリを
cloneしてフォルダに保存します。
Bash
git clone https://github.com/kohya-ss/sd-scripts.git
cd sd-scripts
- GUI起動と必要なライブラリのインストール:フォルダ内のsetupファイルを実行し、必要なファイル(PyTorch、CUDAなど)を自動的にダウンロードさせます。
注釈(仮想環境): PCの中に隔離した別の作業場所を作る機能。AI学習ツールは特定のPythonバージョンを必要とすることが多いため、既存の環境を壊さないように作ります。
Mac PCやGoogle Colabでの環境構築
- Mac PC: Windowsと同様にGitとPythonの環境を作り、ターミナルでコマンドを実行します。ただし、Apple Silicon(M1/M2/M3)チップ搭載機の場合は、特別なライブラリ(PyTorchのMPS対応版など)のインストールが必要になる点に注意が必要です。
- Google Colab: GPUクラウドサービスの一つで、ブラウザ上で簡単にLoRA学習を実行できます。Colab上で公開されているノートブック(学習用コードと設定が書かれているファイル)をコピーし、実行ボタンを押すだけで完了するため、初心者に最も簡単な方法です。(→ [内部リンク:Google Colabを使ったLoRA作成ガイド])
ステップ2:データセット作成
画像の選び方と集め方
高品質なLoRAを作るために最も重要な要素は、学習元となるデータセット(画像素材の集まり)の質です。
- 対象を決める:特定のキャラクター、特定の服装、特定の絵柄など、LoRAで再現したい対象を明確にします。
- 画像の枚数:最低 10枚、推奨 20枚~50枚程度が目安です。多すぎると学習時間がかかり、少なすぎると過学習(特定の1枚の画像を記憶しすぎて応用が利かない状態)の原因になります。
- バリエーションを持たせる:正面、側面、背面、異なるポーズ、異なる背景など、多様な条件の画像を用意することで、応用力の高いLoRAが完成します。同一のポーズや背景ばかりだと、生成時も同じ構図になりやすいです。
注釈(過学習): AIがデータセットの画像を丸暗記してしまい、新しいプロンプトや環境で試すと破綻したり、学習元の画像と全く同じものしか出せない状態のこと。
キャプションの整備とコツ
画像のタグ付け(キャプション)は、AIに「この画像は何が写っているか」を教えるための必須作業です。
- 自動タグ付け:Kohya’s GUIに内蔵されているWD1.4 Taggerなどのツールを使って、最初に自動でタグを付けます。
- トリガーワードの設定:特定のタグを、LoRAを呼び出すための「トリガーワード」に設定します。(例:
1girlの代わりに、キャラ名のsaku_chanに変更して、全ての画像のキャプションに入れます。) - 不要なタグの削除:自動的に付いたタグの中から、学習に必要ない要素(
low quality、text、bad anatomyなど)や、モデル本体が既に知っている一般的なタグ(long hair、blue eyesなど)を削除します。
タグの整備は、生成時にプロンプトで細かい調整を行うための土台作りです。
キャプションの精度が高いほど、LoRAの応用力が増します。
ステップ3:Kohya’s GUIでの学習方法
Kohya’s GUIを使って学習する方法
Stable Diffusion 学習方法として最も一般的なKohya’s GUIを使った手順を解説します。
- 設定ファイルの準備:GUIを起動し、「LoRA」タブを選択します。
- Source Model: 学習のベースとなるStable Diffusionのモデル(
sd-v1-5.ckptなど)を選択します。 - Folders: 画像を入れたデータセットフォルダ、出力フォルダ(完成したLoRAの保存場所)、ログフォルダを指定します。
- Source Model: 学習のベースとなるStable Diffusionのモデル(
- パラメータの設定:学習の結果に大きく影響する重要な設定です。
| パラメータ | 役割(意味) | 初心者向け推奨値 |
| Network Rank (Rank, Dim) | LoRAファイルの大きさと表現力。高いほど詳細な表現が可能ですが、ファイルサイズが大きくなります。 | 128(推奨)、64(軽量モデル向け) |
| Learning Rate (LR) | AIがどれだけ大きく学習内容を反映させるかの速度。高すぎると崩壊し、低すぎると時間がかかります。 | 0.0001 程度(AdamW系最適化手法の場合) |
| Epoch (エポック) | データセット全体を何回繰り返して学習するかの回数。 | 10~20(画像枚数に応じて調整) |
| Batch Size | 1回の学習で使う画像の枚数。大きいほど高速ですが、VRAMを消費します。 | 1(VRAM 8GBなど少ない場合の推奨)、2~4(VRAM 16GB以上) |
- 学習開始:「Train」ボタンを押すと、学習が開始します。
学習中は、コマンドプロンプトにloss(損失)の値が表示されます。このlossの値が安定して下がり続け、0.01~0.05程度になったあたりが「完成」の目安です。
高品質なLoRAを作るためのコツ(ランキング)
LoRAの作り方のコツ:高品質に仕上げる3つの工夫
タグ整理とキャプション精度の上げ方
AIイラスト LoRAの例を見ると、細部までしっかり再現されています。その裏側には、徹底したタグ整理があります。
- トリガーワードの単一化:トリガーワード(例:
saku_chan)は、データセット全体で一貫して使用します。また、プロンプトで呼び出しやすいよう、他の一般的な単語と被らない名前にすることが重要です。 - ノイズタグの徹底排除:背景の影響を除きたい場合は、背景に関するタグ(
outdoors、cityscapeなど)を削除し、キャラクターの特徴に集中させます。 - 強調タグの使用:キャラクターの目の色や髪型など、特に再現したい部分のタグを手動で調整し、重みを付けることで学習を強化します。
画像枚数・エポック数の目安と調整法 画像枚数とエポック数は、学習の「量」を決める重要なパラメータです。
| 画像枚数(Dataset Size) | 推奨エポック数(Epochs) | 調整のコツ |
| 20枚程度 | 20~30 | 枚数が少ないため、エポック数を多くして学習を深くします。過学習に注意。 |
| 50枚程度 | 10~15 | 安定した学習が可能。lossの値を見て調整しやすい枚数です。 |
| 100枚以上 | 5~10 | 学習の時間がかかりますが、汎用性の高いLoRAが作れます。 |
Epoch数を増やすと、過学習のリスクが高まるため、途中で保存されるファイルを定期的にチェックして、最も良い結果のものを選択します。
失敗しない学習率&ステップ設定 Learning Rate(学習率)は、LoRA作り方の中で最も繊細な調整が必要なパラメータです。
| 項目 | 推奨の値 | 失敗しないコツ |
| Learning Rate | 0.0001(1e-4)程度 | 大きく変えない。高くしすぎると画像が「崩壊」します。 |
| Optimizer(最適化手法) | AdamWやAdafactor | AdafactorはLearning Rateの設定が比較的不要なため、初心者に簡単です。 |
| Steps(ステップ数) | 画像枚数 × Epoch数 / Batch Size | 総ステップ数が1000~3000程度になるよう、Epochを調整します。 |
学習率を低く設定して、何回も繰り返し学習する(Epochを増やす)ほうが、急激に学習して崩壊するよりも、結果的に高品質なLoRAが完成しやすい方法です。
完成したLoRAの活用法
LoRA モデルの使い方を解説
学習が完了して出力された.safetensors(または.ckpt)ファイルがLoRAモデル本体です。
- Web UIへの読み込み方:ダウンロードしたLoRAファイルを、Stable Diffusion Web UI(AUTOMATIC1111など)のインストールフォルダ内の
stable-diffusion-webui/models/Loraフォルダに入れます。 - Web UIの再起動:LoRAを格納した後、Web UIを一度閉じて再起動します。
- 反映の確認:Web UIの右上にある「再読み込み」ボタンを押すか、プロンプト欄の下にある「Show/hide extra networks」ボタンを押して、一覧に自分のLoRAの名前が表示されるかを確認します。
Promptへの適用とweight値の調整例 LoRAを実際に画像生成に使う際は、プロンプトに特定の文字列を入力する必要があります。
- LoRAの呼び出し:プロンプト欄の下にある「Show/hide extra networks」ボタンを押すか、手動で以下の形式で入力します。
<lora:ファイル名:強度> - トリガーワードの入力:LoRAを学習させた時に設定したトリガーワード(例:
saku_chan)を、プロンプトの先頭に入れることで効果を発揮させます。 - Weight(強度)の調整:強度の値を変更することで、LoRAの影響度合を調整します。
- 0.6~0.8:推奨の範囲。元のモデルの画風を保ちつつ、LoRAの特徴を反映させます。
- 1.0:LoRAの影響を強くするため、過学習の傾向があると崩壊しやすいです。
| プロンプト例 | 効果 |
saku_chan, <lora:saku_chan-v1:0.7>, masterpiece, white dress | LoRAで学習したキャラクター(saku_chan)を、0.7の強度で反映させます。 |
SD1.5モデル、SDXLモデルでのLoRAの使用と注意点
- SD1.5 モデル:現在、LoRA学習で最も使われているベースモデルです。特に注意点はありません。
- SDXL モデル:2023年に登場した最新のモデルで、LoRA学習にもSDXL専用の設定(SDXL-LoRA)が必要になります。SDXLの特徴として、高解像度(1024×1024以上)を前提とするため、VRAM 16GB 以上の高性能PCが必要になります。
2025年最新のトラブル解決と応用
よくある質問とトラブル対処法
学習中に止まる/保存エラーになる原因 LoRA学習を実行している途中で処理が止まる(フリーズ)、あるいは「CUDA out of memory」などのエラーが表示されて保存が失敗する主要な原因は、VRAM不足です。
| エラー内容 | 主な原因 | 解決策 |
CUDA out of memory | Batch Sizeが大きすぎる、または画像サイズが大きすぎる。 | Batch Sizeを1に下げる。画像サイズを512×512に統一する。Kohya’s GUIの設定でMemory Efficientを有効にする。 |
| 学習が進まない | Learning Rateが低すぎる、またはlossが既に十分低い。 | Learning Rateを微調整(0.0001程度に上げる)する。学習を停止して結果を確認する。 |
| ファイルに名前がない | 出力ファイルの名前を指定していない。 | GUIの設定でModel output nameを必ず記述します。 |
Mac PCの場合は、out of memoryではなく、メインメモリの不足で処理速度が極端に遅くなることがあります。
崩壊・色ずれなどを防ぐTips
- 崩壊:学習率(
Learning Rate)が高すぎる時、画像がノイズのように崩壊します。 - 色ずれ:学習元の画像の色味が極端に偏っている場合(例:全て白背景)、LoRAを使った時に色がずれることがあります。この場合はデータセットに別の背景の画像を追加したり、プロンプトで
white backgroundなどをネガティブプロンプトに入れます。 - 汎用性の向上:定期的に別のプロンプトと別のモデルで試して、LoRAの汎用性を確認します。

LoRAを配布する場合のマナーとライセンス
LoRAを自作した後、CivitaiやHugging Faceなどのサイトで公開することで、収益化(アドセンスや寄付)に繋がる可能性があります。
- ベースモデルのライセンス:最も重要な点は、学習に使ったベースモデル(例:Stable Diffusion 1.5)のライセンスを確認することです。派生モデルは、元のモデルの規約に従う必要があります。
Commercial Use Allowed(商用利用可能):収益化を目的とした利用が可能です。Non-commercial Use(非商用利用):個人の趣味の範囲内に限定されます。
- マナー:公開時は、必ず推奨するプロンプト、トリガーワード、推奨強度を記載します。また、LoRAのバージョン管理を行い、更新情報を明記します。
LoRAの最新応用技術
最新のデータセット作成ツール:より高度なタグ付け 2025年最新のLoRA学習では、より高度なタグ付けツールが登場しています。
- Caption-AIO:画像の解析精度が高く、一括でキャプションの編集やトリガーワードの挿入が可能なツールです。タグ付けの作業時間を大幅に短縮します。
- 多属性学習:特定のキャラクターの服装、髪型、表情など、複数の属性を個別に学習させる方法も一般的になりました。(→ [内部リンク:LoRA学習用データセット作成完全マニュアル:画像集め・キャプション付与の全て])
LoRA作成と活用に関するFAQ
Q. スマホ(iPhone/Android)でもLoRA作成は可能ですか?
A. スマホ単体でLoRAの学習を実行することはできません。
しかし、解決策は二つあります。
一つは、Google Colab(有料のPro/Pro+を推奨)のノートブックをスマホのブラウザから操作して学習を開始する方法です。
もう一つは、GPUSOROBANなどのGPUクラウドサービスに接続して学習を行います。
その進捗をスマホで確認する方法です。
スマホは「学習を開始/停止するリモートコントローラー」として活用できます。
Q. LoRAがうまく反映されない、または画像が崩れてしまいます。
A. LoRAがうまく反映しない問題は、主に3つの原因が考えられます。
- Web UIに読み込まれていない:ファイル名や格納場所(
stable-diffusion-webui/models/Lora)を確認し、Web UIを再起動して反映させます。 - トリガーワードを入れていない:プロンプトに、学習時に設定したトリガーワード(例:
saku_chan)を入れていないと、AIがLoRAの存在を認識できません。 - Weight(強度)の設定が不適切:画像が崩れる場合は強度を0.8以下に下げ、反映が弱い場合は0.6以上に上げて調整します。
Q. LoRAとTextual Inversion(TI)の違いは何ですか?
A. LoRAとTextual Inversion(TI/テキストual インバージョン)は、どちらも追加学習モデルですが、仕組みが違います。
- LoRA:AIモデル本体の一部の重み(重さ)を調整するため、キャラクターのポーズや服装など「画像の構造」に大きく影響させることが可能です。ファイルサイズは数十MB~数百MB程度です。
- Textual Inversion:新しいプロンプトの「単語」を作り出す技術で、「絵柄」や「雰囲気」を変えるのに向いています。ファイルサイズは数百KBと非常に軽量です。
LoRA作成成功のためのチェックリスト
本記事で解説したLoRAの作り方の知識、解決策、最新のコツをまとめて最終チェックリストとします。
| 項目 | チェックポイント |
| 知識・環境 | VRAM 12GB 以上のPC、またはGPUクラウドサービス(→ [アフィリエイトリンク:GPUSOROBAN])を用意しましたか? Kohya’s GUIの環境構築(Git、Python 3.10)は完了しましたか? |
| データセット | 学習画像は20枚~50枚程度用意しましたか? キャプション(タグ)に、トリガーワードを追加して不要なタグを削除しましたか? |
| 設定・学習 | Learning Rateは0.0001程度に設定しましたか? Epoch数は過学習を防ぐために少なめに調整しましたか? Batch SizeはPCのVRAMに応じて1~4に設定しましたか? |
| 活用 | 完成したLoRAをstable-diffusion-webui/models/Loraフォルダに入れましたか? プロンプトに<lora:ファイル名:0.7>とトリガーワードを両方入れましたか? |
あなただけのオリジナルモデルを作成することは、AIイラストの可能性を大きく広げます。
今回作ったLoRAを使って、さらに高品質な画像生成を追求していきましょう。
次のステップへ(関連コンテンツ)
LoRAの作り方をマスターしたら、次は以下の記事を参考にして、さらなるスキルアップを目指しましょう。
[Stable Diffusion Web UI (AUTOMATIC1111) 2025年最新の使い方:初心者向けインストールから神プロンプトまで徹底解説](関連記事):LoRAを使って画像を生成するためのWeb UIの基礎を固めます。
LoRAの作成プロセス詳細と応用
LoRAモデルの構造と役割
LoRA 学習 方法を深く理解するために、AIモデル内でのLoRAの役割を把握しましょう。
LoRAはTransformerブロックのAttention層に追加される 2 つの低ランク行列 (Rank Matrix) で構成されています。
学習時、この行列を調整します。
既存のモデル全体(Checkpoint)は変更しない状態で学習内容を追加します。
- Network Rank (Dim) の値が大きいほど、この行列の表現能力が増し、より複雑な髪型や衣装の細部を再現できる可能性が高まります。
- しかし、Rankを大きくしすぎると 過学習の傾向が強まります。学習時間とファイルサイズも増えます。
- 一般的にキャラクター学習では128が推奨されますが、特定の画風(絵柄)のLoRAを作る場合は 256など高めの設定も試す価値があります。
この知識は、生成結果が理想と違った時にパラメータを調整するための基礎となります。
LoRAの適用とWeight値の調整例
LoRA モデル の使い方を解説します。Stable Diffusion Web UIでLoRAを使う際、プロンプトへの入力形式は以下の通りです。
<lora:ファイル名:強度>強度(Weight)の値は通常0から1の間で調整します。
- 強度 0:LoRA の影響は全くありません。
- 強度 0.5 程度:元のモデルの雰囲気を活かしつつ、LoRA の特徴を微妙に反映させたい時に向いています。
- 強度 0.7 程度:キャラクターの顔や髪型など核となる特徴を確実に再現したい時に推奨される標準的な値です。
- 強度 1.0:LoRA の特徴を最大限に反映させます。過学習している LoRA の場合は画像の崩壊や色ずれの原因になります。
プロンプト内で複数のLoRAを使用することも可能です。
例えば、キャラクターLoRA (強度 0.7)と特定の衣装 LoRA (強度 0.5)を組み合わせて使うことで、より複雑な表現を実現できます。
この時、全体のバランスを見て調整することが重要です。
SD1.5モデル、SDXLモデルでのLoRAの使用と注意点
現在(2025年)、Stable Diffusion の学習方法で使われるモデルは SD1.5系列 と SDXL系列 に大別されます。
- SD1.5のLoRA:基本的に 512×512 や 512×768 などの小さめのサイズの画像で学習されることが多く、VRAMの消費も少なめで済みます。多くの Web UI や拡張機能に対応しているため、初心者はまずこのモデルで LoRA 作り を始めることを推奨します。
- SDXL の LoRA:高解像度(1024×1024以上)を前提としているため、学習の際により大きな VRAM(最低 16GB)が必要となります。SDXL はプロンプトの理解力が高いため、タグの付け方も SD1.5 に比べてシンプルで構いません。しかし、SDXL 専用の学習設定が必要な点に注意が必要です。
LoRA ファイル自体は SD1.5とSDXLで互換性はありません。
ベースモデルとLoRA モデルの系列は必ず一致させる必要があります。
データセット作成の重要性と応用
タグ整理とキャプション精度の上げ方(詳細なテクニック)
AIイラストの LoRAで特定のキャラを高精度で作るためには、キャプションの中で 「学習させたい要素」 と 「学習させたくない要素」 を区別することが鍵です。
- 汎用タグの削除:
1girl、long hair、blue eyesなどはベースモデルが既に知っている単語です。これらのタグは全て削除し、代わりに トリガーワード(例:saku_chan)を挿入します。これにより、LoRAは 「saku_chanという単語が持つ特徴」だけを効率的に学習します。 - 服装のタグ付け:もし特定の衣装を学習させたい場合は、その衣装に関するタグ(例:
school uniform、white kimono)を残します。しかし、生成時に別の服装を着せたい場合は、これらのタグをキャプションから削除。服装の学習を 「抑える」 ことが可能です。 - ブレンド(Mix)用データセット:LoRA を使って多様な服装やポーズを生成したい場合は、学習画像の中に 「全く関係ない背景や服装の画像」を少なく(10%程度)混ぜるテクニックもあります。これにより汎用性が増します。過学習を防ぐ効果もあります。
画像枚数・エポック数の目安と調整法
LoRA 学習 の成功は「いつ学習を止めるか」にかかっています。
エポック数と過学習の関係を理解しましょう。
- エポック数が少なすぎる(未学習):LoRA を使ってもほとんど変化がありません。
- エポック数が適切(ゴール):キャラクターの特徴が反映されつつ、プロンプトの自由が利く状態です。
- エポック数が多すぎる(過学習):生成画像がぼやけたり崩壊します。また、学習画像と全く同じ画像しか作れなくなります。
Kohya’s GUIでは、学習の途中で「保存」の間隔を設定できます。
例えば5エポックごとに保存するように設定します。
完成後に一番良い結果のファイルを選ぶ(選別)ことが一般的な方法です。

収益化と著作権・ライセンス
LoRAを配布する場合のマナーとライセンス
LoRA モデル を作ることで収益化を目指す方へは、ライセンスの知識が必須です。
- ベースモデルの確認:SD1.5 は CreativeML Open RAIL-M ライセンスが適用されている場合が多い。基本的に商用利用は可能です。しかし、AI生成物の著作権は国や地域の法に依存するため、不安な場合は専門家に問い合わせることを推奨します。
- Civitai で の配布ルール:
- CC0:著作権を放棄し、全ての利用が可能な状態です。
- CC-BY:クレジット表記(作者名を書くこと)が必要な状態です。
モデルの中で 「特定のAIモデルとの利用禁止」 などの制限が書かれている場合もあります。そのため、ライセンス情報は必ず読む必要があります。
自作のLoRAを使って生成した画像を販売する場合は、その画像がベースモデルとLoRAの両方の規約を満たしているかを確認しましょう。

2025年最新トレンドと応用技術
LoRA学習方法の進化:より効率的な設定
2025年のLoRA学習方法はより効率的に進化しています。
- Resolution(解像度):SD1.5 の場合でも512×512より大きい解像度(例:640×640)で学習することで、出力時の細部の再現性が高まります。
- DPM-Solver(スケジューラー):学習の最適化手法でDPM-SolverやDPM-Solver++などを使用することで、学習速度を向上させつつ安定させることが可能になっています。
- Batch Size の工夫:VRAM が少ないPCでもBatch Size を1に設定。その分Epoch数を増やすことで結果的なSteps数を確保する方法が一般化しています。
GPUSOROBANを活用したLoRA学習
LoRA学習に必要な VRAM(最低 12GB以上)を持っていないユーザーにとって、GPUクラウドサービスは最適な選択肢です。
- GPUSOROBAN:日本の企業が提供する業界最安級のサービスで、特にAI学習に特化した GPU(RTX 3090、RTX 4090 など)を時間貸しで利用できます。Kohya’s GUIの環境構築もサポートされていることが多く、初心者でも安定して学習が可能です。(→ [アフィリエイトリンク:GPUSOROBAN公式サイト])
- Google Colab:無料枠があるため「試しに」LoRA を作ってみるのには最適です。しかし、無料版は使える GPU に制限があります。長時間の学習や高性能なGPUは有料版(Pro、Pro+)が必要となります。
LoRAの作り方の中で 「高スペックPCが必要」という問題は、GPUクラウドサービスを使うことで完全に解決できます。

環境構築と推奨スペック
AnacondaのインストールとKohya’s GUIの導入の環境づくり(Windows/Mac)
Kohya’s GUIの環境構築に失敗する原因の多くは「パスの通し方」 と「バージョンの不一致」です。
- PythonのPATH設定:Anacondaで仮想環境を作った場合でも、一部のプログラムはPC全体の Pythonのインストールパス(PATH)を参照することがあります。インストール時に必ず 「Add Python to PATH」にチェックを入れる必要があります。
- Gitの導入:
git cloneコマンドが認識されない場合は、Gitのインストールが正しく行われていないか、再起動が必要な場合があります。 - 仮想環境の有効化:Kohya’s GUIを起動する際は、必ず
conda activate lora-trainなどで作成した仮想環境を有効化(activate)してから、学習を開始します。
おすすめの高性能GPUと周辺機器
ローカル PCでLoRA学習を安定的に行いたい方向けに、2025年最新の推奨スペックと製品を紹介します。
- 推奨 GPU(NVIDIA):
- RTX 4060 Ti(VRAM 16GB 版):コストと性能のバランスが最適。SDXLのLoRA学習も可能な最低ラインです。
- RTX 4070 / 4080(VRAM 12GB ~ 16GB):速度を重視するクリエイターに向いています。
- 学習用データの保存:大量の学習画像(LoRA データセット)を高速で読み込み、保存するためには高速なM.2 SSDが必須です。

LoRA作成後の収益化の道筋
作成したLoRAを使って生成した画像を「商品」として販売するためには、画像編集ツールが必要です。
- Canva Pro:ブログのアイキャッチ、SNS投稿、電子書籍の表紙など、生成した画像を簡単にデザインに落とし込めるツールです。(→ [アフィリエイトリンク:Canva Pro])
- Adobe Photoshop:より高度なレタッチや合成、色の調整を行いたいプロのクリエイター向けです。
LoRA で生成した画像に 付加価値を付けて販売することが、継続的な収益化の鍵となります。
専門用語解説とQ&A
LoRA関連の用語集
| 用語 | 注釈(初心者向け解説) |
| Checkpoint | Stable Diffusion本体の大規模AIモデルファイル(数 GB)。LoRA はこれに追加されて動きます。 |
| Optimizer | 学習時に AI が一番効率良く知識を吸収するための計算アルゴリズム(手法)。AdamWや Adafactor が有名です。 |
| Learning Rate | 学習率。AIがどれだけ大きく設定変更を受け入れるかの度合。大きいと速いが崩壊しやすい。 |
| Batch Size | 1回の学習で同時に処理する画像の枚数。VRAM の消費量に直接影響します。 |
| Epoch | データセット全体を使って学習を行った回数。多いと過学習のリスクが高まります。 |
| Triger Word | 生成時にLoRAを「呼び出す」ための特定のプロンプト(呪文)。 |

LoRA学習の応用的なQ&A
Q. 崩壊したLoRAを修正することはできますか?
A. 一度過学習(崩壊)してしまったLoRAファイルを直接修正することは難しいです。しかし、解決策はあります。
- 途中保存のファイルを使う:過学習を起こす前に保存されたファイル(例:
Epoch 15のファイル)があれば、それを使えば問題ありません。 - 新しいデータセットで再学習:「背景のバリエーションを増やした新しいデータセット」を使って再学習することで、汎用性の高い LoRA を作り直すことが可能です。
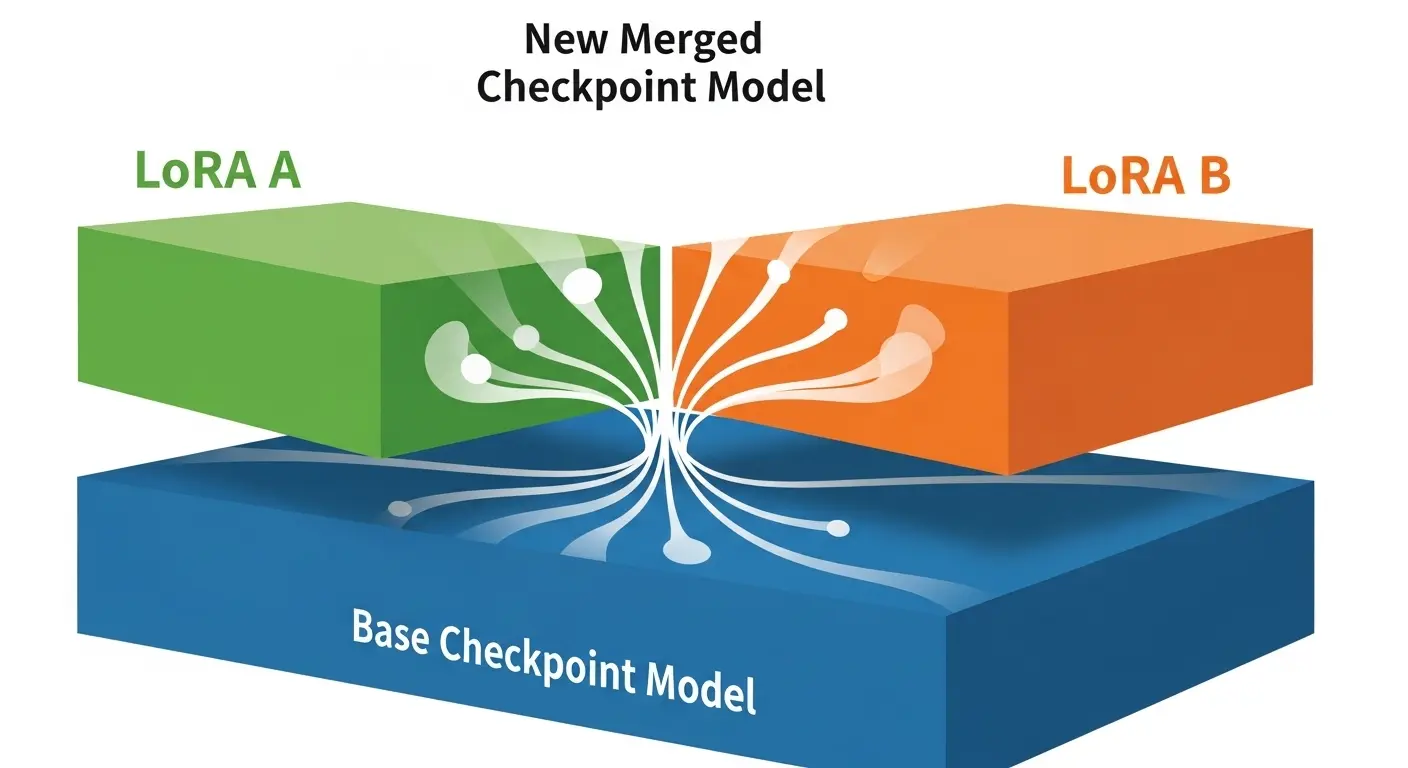
Q. LoRAとCheckpointモデルを混ぜることはできますか?
A. はい、可能です。
LoRAモデル は Checkpointモデルと同様に 「追加学習」の要素を持つため、Merge(混合)ツールを使って既存のCheckpointにLoRAの学習結果を統合し、新しい Checkpoint モデルを作ることができます。
これにより、LoRAを使わなくても常に特定のキャラクターを出せる「専用モデル」 を作ることが可能になります。