Stable Diffusion(ステーブルディフュージョン)を使って、あなた自身やオリジナルキャラクター、特定のアートスタイルをAI画像生成に覚えさせたい。
こう考えているなら、「LoRA」と「Dreambooth」という二つの学習方法が選択肢になります。
どちらも非常に強力なAIのモデル生成手法ですが、
- VRAMの必要容量
- 学習時間
- そしてデータファイルサイズ
に決定的な違いがあります。
特にWindows PCやMac PCのローカル環境でAI画像生成を始めたばかりの初心者にとって、「どちらを選べばいいのか」は大きな課題です。
今回の記事では、LoRAとDreamboothの違いを2025年最新の技術情報に基づいて徹底比較します。
それぞれの学習方法のメリットとデメリットを分かりやすく解説します。
これを読めば、あなたの目的に合わせた最適な手法が簡単に選べるようになります。
AI画像生成の精度向上へと繋がる解決策が得られます。
LoRA Dreambooth 比較:根本的な違いを理解する
この章で伝えたい結論: LoRAは追加学習、Dreamboothは微調整(ファインチューニング)であり、ファイルサイズとVRAM容量に大きな違いがあります。
LoRAとは?
LoRA(Low-Rank Adaptation of Large Language Models)は、大規模言語モデルの学習を効率的に行う方法として登場しました。
Stable Diffusionに応用される際、既存のベースモデル(Stable Diffusion Model 1.5やSDXLなど)の重みの行列に、低ランクの小さな行列を追加学習させます。
特定の情報(キャラクター、ポーズ、スタイルなど)を効率的に覚えさせる手法です。
メリット:
- ファイルサイズが非常に小さい(数MBから数十MB程度)。
- VRAM消費量が低く、8GBや12GBのGPUでも学習が可能です。
- 学習時間が短いため、試行錯誤が簡単に行えます。
デメリット:
- ベースモデルの持つ表現の枠内でしか機能できず、モデル全体を大きく変更することは難しいです。
- 学習が浅い場合、画像生成時にプロンプトとの組み合わせ方で結果が不安定になることがあります。
Dreamboothとは?
Dreamboothは、Googleの研究者によって開発された手法で、既存のベースモデルを対象データに対して直接微調整(ファインチューニング)します。
これは、モデル全体のパラメータを一部変更することで、モデル自体に新しい特定の物体や人物を「埋め込み」ます。
画像生成時のプロンプトにトリガーワード(instance prompt)を入力することで、その物体や人物を忠実に再現可能となります。
メリット:
- 精度が非常に高い: モデル全体を変更するため、特定の被写体の外見やポーズをLoRAより忠実に再現できます。
- 応用の幅が広い: 画風やアートスタイルの根本的な変更にも適しています。
デメリット:
- VRAM消費量が非常に大きい: 学習時に16GB、SDXLの場合は24GB以上のVRAMが必要となることもあり、ローカルPCでの実行が難しい場合が多いです。
- 出力ファイルサイズが巨大: モデル全体を保存するため、数GB(通常約2GB〜7GB)のファイルサイズとなります。
- 学習時間が長い。
LoRA Dreambooth比較:目的別最適な学習手法の選び方
この章で伝えたい結論: 特定のキャラクターやアイテムの追加が目的ならLoRA、モデル全体の画風やスタイルを変えたい場合はDreamboothが最適です。
| 比較項目 | LoRA (Low-Rank Adaptation) | Dreambooth | 解決のポイント |
| 目的 | 特定の要素の追加・微調整 | モデル全体の知識の根本的な変更 | 用途に合わせた手法の選択が重要 |
| 必須VRAM(推奨) | 8GB〜12GB(16GBあれば安心) | 16GB〜24GB(クラウド利用が推奨) | ローカルPCのスペックに応じて判断 |
| ファイルサイズ | 数十MB(軽量) | 数GB(巨大) | 保存場所と共有の容易さの違い |
| 学習時間 | 比較的短い(数分〜数時間) | 比較的長い(数時間〜数日) | 試行錯誤のしやすさに影響 |
| 汎用性 | ベースモデルに依存する | モデル自体が新しくなるため汎用性が高い | 新しい画風をゼロから作りたい場合はDreamboothが有利 |
Stable Diffusion LoRA: 軽量性と柔軟性を最大限に活用する
Stable DiffusionにおけるLoRAの最大の利点は、その軽量性です。生成時に複数のLoRAを組み込むことが簡単に可能です。
- キャラクターのLoRA
- 衣装のLoRA
- 背景スタイルのLoRA
を同時に適用するといった、柔軟なカスタマイズが可能になります。
AI初心者がローカル環境(VRAMが12GB程度のPCなど)で学習を始める場合。
LoRAから入ることを強くおすすめします。
失敗しても時間やリソースの損失が少ないため、学習方法の基礎を簡単に習得可能です。
Stable Diffusion Dreambooth: 究極の再現性を追求する
Dreamboothは、特定の人の顔や物体をAI画像生成に非常に忠実に再現させたいクリエイターや企業プロジェクトに適しています。
モデル全体をファインチューニングするため、画像の品質と再現性がLoRAよりも高くなる傾向があります。
しかし、高VRAMのGPUが必須となるため、個人開発者や初心者の場合は、Google ColabやRunPodなどのクラウドサービスを利用することが前提となります。
LoRA 学習方法:初心者でも簡単!実践的な手順とコツ
この章で伝えたい結論: LoRAの学習方法はKohya’s GUIを使えば簡単で、高品質なデータセットの準備が成功の鍵となります。
LoRA 学習方法の全体像とツール
LoRAの学習は、主にKohya’s Stable Diffusion web UI GUI Trainer(通称:Kohya’s GUI)を使って行われます。
- 学習データの準備: 特定のキャラやスタイルの画像を20枚〜30枚以上用意。
- タグ付け(キャプション): BLIPやWD14 Taggerなどのツールを使って、画像ごとに詳細な説明テキスト(キャプション)を付けます。
- 環境構築: Python、PyTorch、accelerateなどの環境を構築し、Kohya’s GUIを起動します。
- パラメータ設定と実行: 学習率(Learning Rate)やNetwork Rankなどの設定を行い、学習を開始します。
- 結果の確認: 学習後、生成結果を確認し、プロンプトの調整を行います。
学習データの準備:質と量が精度を左右する
LoRAの精度を高めるためには、学習データの質と量が非常に重要です。
特定の人物やキャラを覚えさせる場合は、
- 正面
- 横
- 後ろ
様々な表情やポーズの画像を最低20枚、できれば30枚以上用意することが推奨されます。
キャプションとトリガープロンプトの調整
AIが何を覚えればいいのか理解できるように、キャプション編集が必須です。
- トリガープロンプト(例:
lt my-name): 学習させたい対象の名前を一貫して付けます。 - クラス画像の利用(正則化): AIが覚えすぎることを防ぐため、対象以外の画像(例: 人物ならperson)をクラス画像として追加します。(過学習の解決策)
LoRA学習を成功させるパラメータの知識
LoRAの学習で一般的に使われるパラメータのコツは以下の通りです。
| パラメータ | 役割 | 推奨設定のポイント |
| Network Rank (Dim) | LoRAファイルの表現力 | 16〜128(低めの値がVRAMに優しい) |
| Learning Rate | 学習の歩幅 | 1e-5〜5e-5が基本(高すぎると過学習の原因) |
| Optimizer | 学習アルゴリズム | AdamWやLion(最新のProdigyは学習時間短縮に貢献) |
| Epoch / Steps | 学習回数 | 総Step数が5000〜10000程度になるように調整します。 |
(サイト外リンク: Kohya’s sd-scripts GitHub公式)
Dreambooth 学習方法:具体的な手順と高精度化の解決策
この章で伝えたい結論: Dreamboothの学習方法はVRAMが課題ですが、適切な環境構築と学習データの準備により高精度を実現可能です。
Dreambooth 学習の環境構築(VRAMの課題)
Dreamboothは、VRAM容量の関係上、Google ColabやRunPodなどの高性能GPUサーバーを利用することが一般的です。
ローカルPCで実行する場合、RTX 4090(24GB VRAM)など最新スペックのGPUがほぼ必須となります。
学習の流れはLoRAと同様ですが、モデル全体を微調整するため、ファイルの入出力や準備時間が長くなる傾向があります。
Dreambooth 学習に必要なデータの準備
Dreamboothでは、学習させたい被写体の画像(インスタンス画像: instance images)と、その被写体が属するクラスの画像(クラス画像: class images)を用意します。
例: 特定の猫(インスタンス)を覚えさせたい場合、一般的な猫の画像(クラス)を多めに用意しましょう。
AIが「その特定の猫」と「普通の猫」の差分を理解するように促します。
この差分学習の仕組みこそがDreamboothの高精度の秘密です。
Dreamboothのクオリティを上げるコツ(解決策)
リクエストにあった内容を踏まえ、Dreamboothで高品質な結果を得るためのコツは以下の通りです。
1. 学習データを増やして精度を上げる
教師データの枚数は、AIの知識の幅を広げることに繋がるため非常に重要です。
最低5枚、できれば20枚以上用意しましょう。
多めに準備することが成功の鍵です。
画像数が少ないと過学習しやすくなります。
2. 学習データの画像サイズを正方形に統一する
Stable Diffusionのベースモデルは512×512や1024×1024などの正方形解像度で学習済みです。
学習データのサイズを正方形に統一することで、AIが効率よく特徴を抽出可能になります。
画像生成の品質が向上します。
3. max_train_stepsを増やして学習を深くする
max_train_steps(最大学習ステップ数)は、学習の総回数を決めるパラメータです。Dreamboothはモデル全体を変更するため、LoRAより多めのステップ数が必要となる傾向があります。
しかし、増やしすぎると過学習の原因となるため、損失関数(Loss)を確認して調整する必要があります。

LoRAとDreamboothの最新応用事例
この章で伝えたい結論: 2025年の最新トレンドとして、LoRAの進化系や、両手法の長所を活かした組み合わせ方が注目されています。
LoRAの進化系LyCORISと2025年のトレンド
LoRAの持つ軽量性というメリットはそのままに、表現力を向上させた進化系の手法「LyCORIS」が最近登場しています。
LyCORISには、LoHa(Low-rank Hadard product)やLoKrなど様々な方式があります。
複雑な画風や表情の再現に優れています。
そのため、LoRAで上手くいかない場合はこちらを試すことが推奨されています。
これは、Stable Diffusion LoRAのコミュニティで生まれた新しい知識であり、AI画像生成の鮮度を保つ上で非常に重要です。
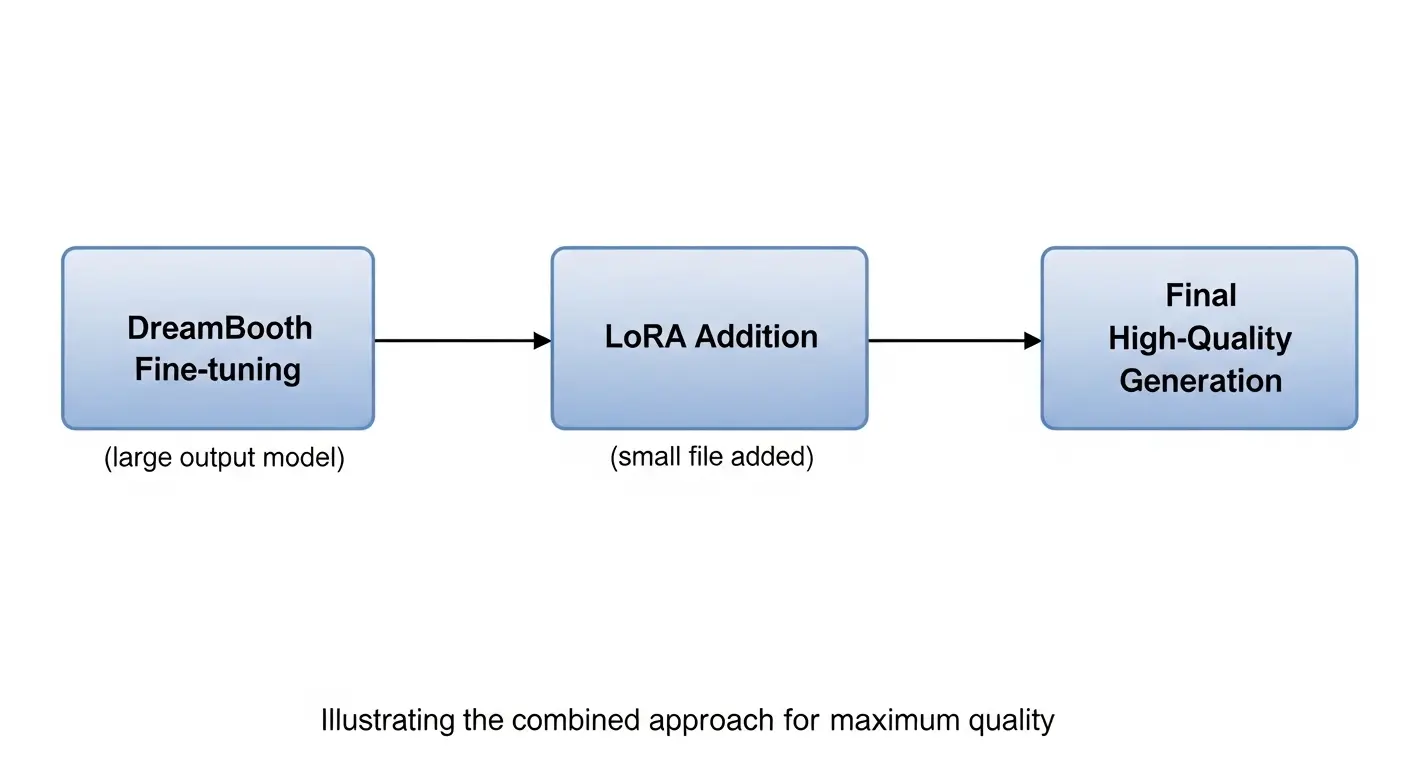
LoRAとDreamboothの組み合わせ活用術
最も高品質な結果を得るための応用方法は、両手法を組み合わせることです。
- Dreamboothでベースモデルの画風を大幅に変更(例:油絵風や水彩画風)。
- そのモデルを使って、LoRAで特定のキャラや衣装を追加学習。
この方法により、Dreamboothによる根本的なスタイル変更という高精度と、LoRAによる軽量な要素追加という柔軟性という、両方のメリットを活用可能となります。
LoRAとDreamboothの解決策と判断基準
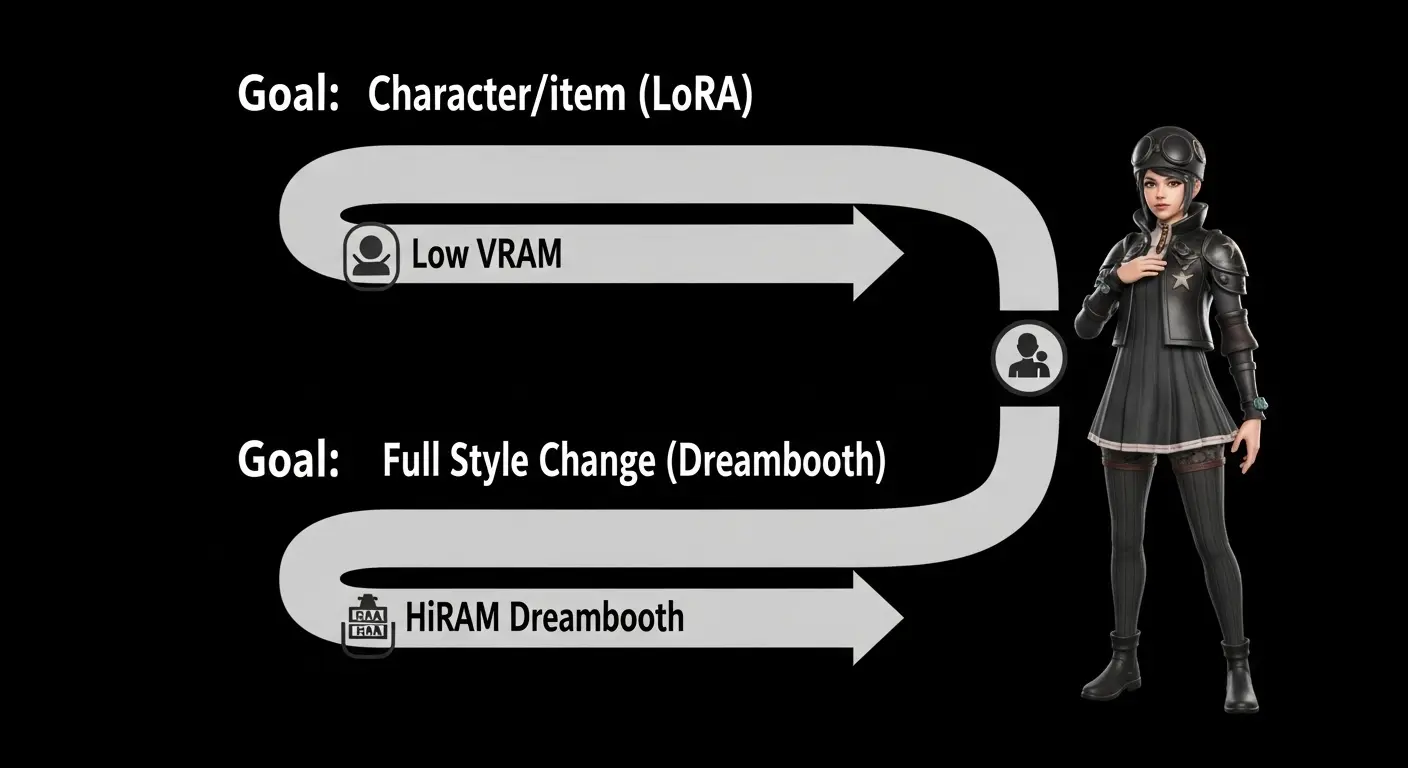
この章で伝えたい結論: 初心者は失敗リスクの低いLoRAから始め、高スペックな環境が整ったらDreamboothに挑戦しましょう。
どちらを選ぶべきか?初心者へのロードマップ
AI画像生成を始めたばかりの初心者は、まず以下のフローで判断することを推奨します。
- 目標: 特定のキャラクターやアイテムの再現ですか? → LoRAがおすすめ
- 目標: モデル全体の画風(例: 水彩風から油絵風へ)を根本的に変えることですか? → Dreamboothがおすすめ
- 環境: ローカルPCのVRAMが12GB未満ですか? → LoRA(またはクラウドの利用)が必須
LoRAは失敗しても修正が容易なため、初心者が学習の仕組みを理解するための最適な手法と言えます。
AI画像生成 学習で失敗しないための解決策
LoRAもDreamboothも共通して学習失敗の原因となる要素と解決策があります。
| 失敗の原因 | 解決策 |
| 過学習 | 教師データにクラス画像(正則化画像)を追加し、学習率を低めに設定する。max_train_stepsを減らす。 |
| 未学習 | 教師データの枚数を増やす。EpochやRepeatsを増やし、総Step数を確保する。 |
| 環境エラー | PythonやPyTorchのバージョンを確認し、GitHubの公式リポジトリから最新のスクリプトをダウンロードして使用する。 |
Dreamboothの具体的な学習方法と実践
この章で伝えたい結論: Dreamboothの学習方法を理解することで、ローカル環境の課題を乗り越え、高精度なモデル作成の知識が得られます。
Dreamboothの仕組みを理解する
Dreamboothは、画像生成AIの拡散モデル(Diffusion Model)全体に、特定の被写体の情報を新しく書き込む手法です。
既存のモデルが持っている知識と新しい情報の差分を学習することで、少ないデータ数でも高精度な結果を得ることが可能になります。
専門的に言えば、モデルの重み(Weights)全体を対象に微調整(Fine-Tuning)を行うことが特徴で、そのためVRAMを多く使用します。
Dreambooth学習の実践手順
Dreamboothの学習は、Stable Diffusion web UI(AUTOMATIC1111など)の拡張機能として利用可能な場合。
Diffusersライブラリを使ったPythonスクリプトの実行で行われます。
1. Dreamboothのインストール方法
AUTOMATIC1111 web UIを使用する場合、「拡張機能(Extensions)」タブからDreamboothの拡張機能を検索します。
インストールします。
インストール後、UIを再起動することで新しいDreamboothのタブが追加されます。
2. 学習データの準備とフォルダ構成
インスタンス画像とクラス画像は、指定された形式(通常はPNGまたはJPG)でフォルダに保存します。
例: 10_my-dog(10は学習回数、my-dogはインスタンスプロンプト)のような形式でフォルダを作成しておくことが一般的です。
3. コードの実行とパラメータ設定
Dreamboothの設定画面で、学習させたいモデルを選択。
- 学習データのパス
- インスタンスプロンプト
- クラスプロンプト
などを入力します。
高精度を得るためには、以下のパラメータ調整が必要です。
- Learning Rate: LoRAよりも低め(数値は1e-6台もあり)に設定。
- Resolution: 学習解像度は512×512や1024×1024に統一。
- Prior Preservation Loss(正則化の一種): クラス画像を使って元のモデルの知識を保持する機能。品質向上に非常に役立ちます。

AI画像生成 学習:専門用語の簡単解説(知識)
この章で伝えたい結論: 専門用語の丁寧な解説は、AI初心者の学習意欲を維持し、記事の離脱率を下げる重要な要素です。
LoRAとDreamboothで使われる主要な専門用語
h3. 専門用語解説一覧
| 専門用語 | わかりやすい解説 |
| VRAM(ビデオメモリ) | GPU(グラフィックボード)に搭載された専用メモリ。AIの学習を実行する際にデータを展開する場所であり、容量が多いほど大きなモデルの学習が可能です。 |
| ファインチューニング | 既存の学習済みモデルを使って、特定のタスクやデータに合わせて微調整する学習方法。Dreamboothはこれに該当します。 |
| 低ランク適応(Low-Rank Adaptation) | モデル全体を変更せず、新しい知識を小さな追加ファイルとして適用する技術。LoRAの核心仕組みです。 |
| インスタンス画像 | AIに覚えさせたい特定の被写体の写真。「私の猫」といった一つの例を示します。 |
| クラス画像 | インスタンス画像が属する一般的なカテゴリの画像。AIの過学習を防ぐための補助データです。 |
| Optimizer(最適化関数) | AIが最も効率よく学習を進めるためのアルゴリズム。学習時間と精度に大きく影響します。(AdamW、Lion、Prodigyなど) |
AI画像生成 学習の進化:2025年最新情報
この章で伝えたい結論: AI画像生成の学習手法は日進月歩で進化しており、最新の動向を追うことが高品質なモデル作成に繋がります。
SDXLと学習手法の変化
h3. SDXLと学習手法の最新対応
Stable Diffusion XL(SDXL)の登場により、LoRAとDreamboothの学習要件はさらに高くなりました。
SDXLはベース解像度が1024×1024と大きくなったため、学習時のVRAM要件はLoRAでも16GB程度が推奨されます。
Dreamboothでは24GB以上のGPUが事実上必須となります。
しかし、その分、生成される画像の品質や細部の表現力は従来のモデルより格段に向上しています。
最新の限定情報:クラウドサービスの進化
ローカルPCのスペック不足を補うクラウドサービスでは、NVIDIAの最新GPU(RTX 4090やH100など)を利用可能なサービスが増えています。
これらの最新GPUを活用することが、DreamboothなどのVRAM消費の多い学習方法を失敗なく実行する最良の解決策です。
(サイト外リンク: NVIDIA公式サイト-最新GPU情報)
よくある質問と回答(FAQ)
LoRAとDreamboothはどちらがファイルサイズが小さいですか?
LoRAが圧倒的にファイルサイズが小さいです。LoRAは数十MB程度です。
対して、Dreamboothはモデル全体のデータを保存します。
そのため、数GBにもなります。
多くのモデルを保存したい場合はLoRAを選択するべきです。
AI画像生成の学習はスマホ(iPhone、Android)で可能ですか?
AI画像生成の学習(LoRAやDreambooth)は、非常に大きな計算リソースとVRAMを必要とするため、現在のところスマホ単体で直接行うことは不可能です。
スマホからGoogle Colabなどのクラウドサーバーに接続します。
遠隔で実行する方法は利用可能です。
Stable Diffusion Colab完全ガイド|無料かつ高速なAI画像生成方法
まとめ:理想のAIモデルを作成しよう
この記事では、AI画像生成の二大学習手法であるLoRAとDreamboothの決定的な違い、最新の学習方法、そして初心者が失敗を解決するためのコツを徹底解説しました。
| 結論: 最適な手法の選択基準 |
| 軽量・柔軟性・低VRAMを重視するならLoRA |
| 高再現性・モデル全体の根本的な変更を重視するならDreambooth |
AI画像生成の技術は進化が速いですが、この記事で得た知識と比較基準を持っていれば、どんな新しい手法が登場しても適切な判断が可能です。
あなたの目的に合った手法を選び、AIモデル開発の次のステップに進みましょう。

サイト外リンク一覧
- Google Colab Proサービス情報
- AUTOMATIC1111 Web UI GitHub
- Kohya’s sd-scripts GitHub公式
- Diffusers公式ドキュメント
- Python公式ダウンロードサイト
- Hugging Face – Stable Diffusionモデル
- Civitai – LoRAモデル配布サイト