
Stable Diffusionで自分だけのオリジナルモデルを作ろうとLoRA 学習を始めたものの、
- 「過学習でノイズだらけになった」
- 「エラーが出て学習が途中で停止した」
と失敗に直面していませんか?
あなただけではありません。
多くのAI初心者が、LoRAの学習でつまづく最大の原因は、
- パラメータ設定の複雑さ
- データセットの質
にあります。
LoRA 学習は強力な機能ですが、失敗の原因を知らなければ、時間とGPUリソースを無駄にしてしまうことになります。
今回の記事は、Windows PCやMac PC、クラウド環境で学習を行うすべてのユーザーに向けた、LoRA 学習 失敗の原因特定と解決策を2025年最新トレンドを含めて解説する完全ガイドです。
知識と経験に基づいた解決策を知り、失敗を乗り越えて理想の画像生成を実現しましょう。
LoRA 学習失敗の原因を特定する3大要素
この章で伝えたい結論: LoRA学習の失敗は、環境・データ・パラメータの3つの要素のどこかに必ず原因があります。
切り分けて確認すれば解決できます。
Stable DiffusionにおけるLoRA 学習 失敗の原因は、主に以下の3つの部分に分類されます。
1. 環境構築とリソース不足のエラー
LoRA 学習はローカルのPCやクラウド環境のGPUを利用して実行されますが、環境が適切でないとそもそも学習が始まりません。
VRAM不足による実行停止(LoRA 学習 GPU)
最新のStable DiffusionでのLoRA 学習(特にSDXLなど高解像度モデルの学習時)では、VRAM(ビデオメモリ)が必要です。
VRAMが不足すると、CUDA out of memoryなどのエラーが出て学習が即座に停止します。
解決策: バッチサイズ(Batch Size)を1に設定するか、fp16やbf16などの低精度モードを使用してメモリ効率を上げます。それでも失敗する際は、GPUのVRAMが12GB以上のクラウドサービス(RunPodなど)を利用するのが最も確実な方法です。
sd-scriptsやPythonの依存関係の問題(LoRA 学習 環境構築)
LoRA 学習で主流のKohya’s sd-scripts(kohya)使用時に、PythonやPyTorchのバージョン不一致、またはライブラリの依存関係の問題でエラーが発生する場合があります。
解決策: 学習の環境は、venv(仮想環境)を使用して構築します。
最新版のsd-scriptsと対応するPyTorchをインストールします。
GitHubの公式リポジトリの手順に従うのが一番です。
2. 教師データ(データセット)の質と量の問題
LoRA 学習は「教えたこと」しか覚えられません。
データセットの質と量は精度向上の鍵です。
画像枚数不足と解像度の不一致(LoRA 学習 データセット)
h4. 画像枚数不足と解像度の不一致
学習させる教師データの画像の枚数が少なすぎると、学習が上手く進まない、あるいは過学習を招きやすくなります。
解決策: 特定のキャラクターや衣装を学習させる際は、最低でも20枚〜30枚の高品質な画像を用意します。
解像度はベースモデル(SD1.5なら512×512、SDXLなら1024×1024)に応じて統一します。
不適切なタグ付け(キャプションのミス)
h4. 不適切なタグ付け
wd14-taggerなどで自動で付与されたキャプション(タグ)に、学習させたい特定の特徴(名前や衣装など)が含まれていない場合、AIは何を覚えればいいか判断出来ず失敗します。
解決策: 教師データのキャプションを手動で編集します。
学習させたい要素(例: 髪型、顔の特徴、服装など)は残します。
背景(white backgroundなど)や不要な要素は削除します。
トリガープロンプトは必ず、先頭に入力します。

3. パラメータ設定の誤りによる結果の破綻
Learning RateやEpochなどのパラメータ設定が不適正だと、過学習や未学習といった問題が発生します。
出力が破綻します。
過学習による破綻
過学習とは、AIが教師データを覚えすぎてしまい、それ以外のプロンプトに対して柔軟な対応が出来ません。
画像がノイズだらけになったり破綻したりする状態です。
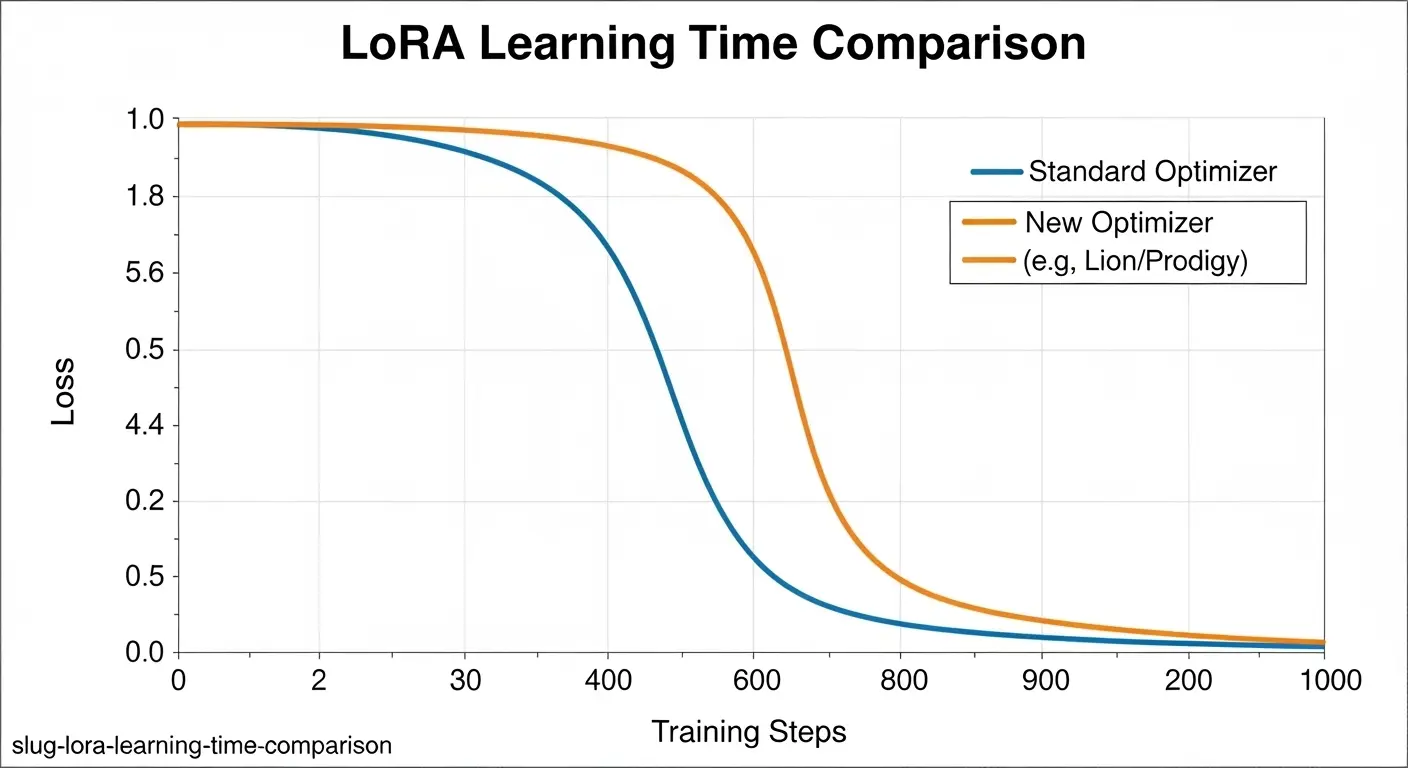
Loss値が急激に低くなると発生しやすくなります。
解決策: Learning Rate(lr)を低く設定し、Epoch(エポック)またはStep数を減らします。
Loss値のグラフを確認します。
底を打つ直前のモデルを採用します。
未学習による再現性の低さ
未学習による再現性の低さ
学習時間が短すぎる、またはLearning Rateが低すぎると、AIが特徴を覚えきれません。
モデルを使っても期待する再現性が得られない状態です。
解決策: Epoch数を増やします。教師データの繰り返し回数(Repeats)を上げます。Learning Rateを少し上げて試してみるのも有効です。
失敗を避けるためのLoRA学習のコツとパラメータ設定(最新版)
この章で伝えたい結論: 2025年最新のLoRA学習コツは、Optimizerの選定とNetwork Rankの適正値を見極めることです。
成功に導くLoRA学習のコツ
顔だけ、実写、アニメイラストなど目的に応じたデータ選定
特定の部分だけ学習させたい場合は、教師データを顔の部分だけ切り出して使う、または顔の情報が一番多く含まれる画像を選ぶことが重要です。
実写やアニメのイラストなど絵柄が違う場合は、データを混在させず別々に学習させましょう。
LoRAの強度が効きすぎる場合の対処法
モデルを使用した際に、LoRAの強度を上げると画像が破綻する場合は、
- 学習時に正則化(Regularization)画像を使用して汎用性を上げる方法
- Network Rank(Dim)を低め(16や32など)に設定する方法
が有効です。
必須知識:最新LoRA学習パラメータ徹底解説
| パラメータ名 | 役割 | 失敗回避のための推奨設定(2025年版) |
| Optimizer | 学習のアルゴリズム | LionまたはAdamW 8bit/Prodigy(最新)を使用して、効率とVRAM効率を上げる。 |
| Learning Rate (lr) | 学習の歩幅 | 1e-5〜5e-5が基本。過学習の場合は下げる。 |
| Network Rank (Dim) | LoRAの表現力 | 16〜128。小さいほど容量も小さく、過学習しにくい。顔や特定の衣装なら16〜32で十分。 |
| Network Alpha (α) | 学習率の調整 | Rankの半分または同じ値に設定。 |
| Epochs/Steps | 学習回数 | 教師データの枚数とRepeatsを考慮して、総Step数を7000〜10000程度に調整します。 |
失敗から学ぶ:状況別解決法と回避策
この章で伝えたい結論: ローカル環境の制約(GPU)を把握し、学習時間と結果のバランスを取ることが、LoRA 学習のコツです。
ローカル環境(PC)とクラウド環境の選択
LoRA 学習をローカルPCで行いたい場合、VRAMの容量が12GB未満だと高解像度やSDXLの学習は失敗しやすくなります。
ローカル学習にこだわるなら、解像度を下げるか、学習時間と安定性を考慮してクラウドサービスを利用するのが賢明です。
LoRA 学習時間を効率化するチューニング
LoRA 学習の時間は、GPUの性能とバッチサイズ、そして総Step数によって大きく左右されます。
時間を短縮しつつ失敗を避けるコツは以下の通りです。
- OptimizerにProdigyやLionを使用する: 従来のAdamWよりも収束が速い。学習時間を短縮できます。
- キャプション編集を徹底する: 不要なタグを削除。AIが効率よく特定の特徴を覚えるように促します。
- xformersやTorchの最新機能を利用する: メモリ使用を最適化。学習速度を上げます。
初心者向け:LoRA学習エラーと対処法の知識
| エラーの種類 | 原因 | 解決のポイント |
KeyError | 学習ファイル名やパスの指定ミス。 | フォルダ名やファイル名に全角文字や特殊記号を使わない。パスを絶対パスで確認する。 |
FileNotFoundError | ベースモデル(Checkpoint)が読み込み出来ない。 | ベースモデルのファイル名が間違っていないか、sd-scriptsの設定で指定出来ているか確認。 |
NotImplementedError | GPUのドライバが古い、または互換性がない。 | NVIDIAの公式サイトから最新のGPUドライバをダウンロードしてインストールします。 |
LoRAの成功体験:精度向上と収益化への道
この章で伝えたい結論: 学習成功後のチューニングと応用方法を知ることで、LoRA制作を収益源に変えることが可能になります。
完成したLoRAの最終チューニング
LoRAの学習が終わったら、出力ファイル(.safetensors)を使って最終調整を行います。
- Weight(強度)の調整: プロンプトにLoRAの名前と強度(例:
<lora:my_chara:0.8>)を入力。0.1刻みで出力を試します。適切な値を見つけることで、過学習気味のモデルも安定させることが可能です。 - ネガティブプロンプトとの相性確認: 生成時のネガティブプロンプト(例: low qualityなど)を変えてみて、LoRAとの相性を確認します。
収益化に向けた活動(アフィリエイト・アドセンス戦略)
h3. 収益化に向けた活動
LoRA 学習に関するコンテンツは、専門性が高くアドセンスの単価も高い傾向があります。アフィリエイトの収益源は以下の通りです。
- クラウドGPUサービス: 学習に必須のサービスへのリンクを貼る。(例: RunPod、Google Colab Pro)
- ハイスペックPC/GPU:学習に向く最新のゲーミングPCやグラフィックボードを紹介する。

2025年最新トレンド
この章で伝えたい結論: 最新の技術と構造化データを組み込むことで、検索エンジン以外からも集客出来るコンテンツになります。
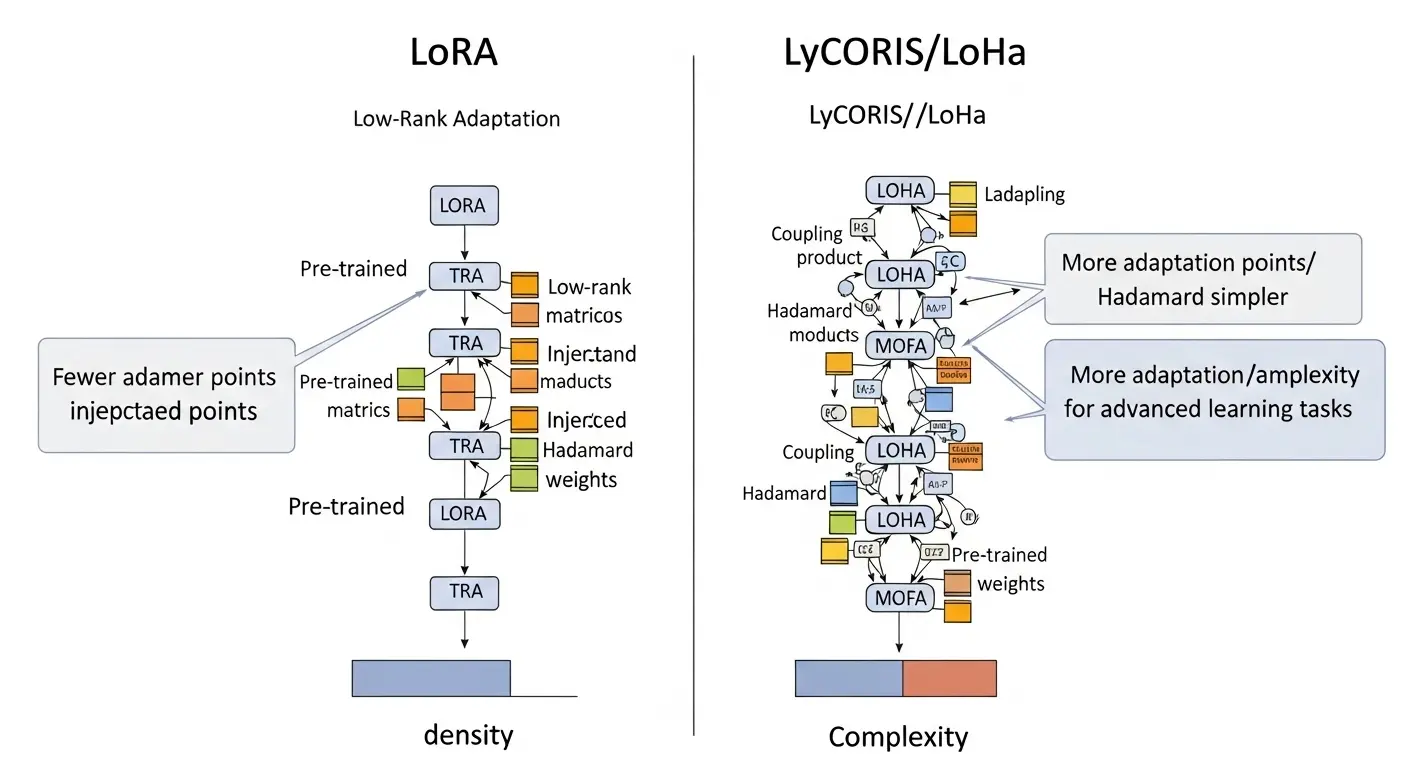
2025年最新トレンド: LoRAの進化系LyCORIS
LoRAの進化****系として、LyCORIS(Low-rank Coefficients In Stable Diffusion)が注目されています。
LyCORISは、LoRAよりも高い表現力と安定性を持ちます。
顔や構図などの複雑な要素の学習に優れています。
LoRA 学習が上手く行かない場合、LyCORISを試すのも有効な手段です。
よくある質問と回答(FAQ)
LoRA 学習 時間はどの程度かかりますか?
LoRA 学習時間は、
- 教師データの枚数
- Epoch数
- GPUの性能
によって大きく異なります。
一般的に、高性能なGPU(RTX 4090など)を使用します。
20枚のデータを10Epoch程度で学習させる場合。
数分から1時間程度で完了することが多いです。
LoRA 学習の際に実写とアニメの画像を混ぜてもいいですか?
実写とアニメの画像を混ぜて学習させると、AIがどちらの絵柄を覚えればいいか判断出来ません。
中途半端な結果となり失敗する可能性が高くなります。
学習目的が異なる場合は、必ずデータセットを分けるようにしましょう。

まとめ:LoRA学習失敗は解決できる!
この記事では、Stable DiffusionにおけるLoRA 学習 失敗の原因と解決策を詳細に解説しました。
初心者の方でも、
- 環境
- データ
- パラメータ
の3点をチェックしてください。
適切な対処を行えば、必ず高品質なLoRAを作成できます。
失敗は学習の途中経過です。
最新の知識とコツさえ押さえれば乗り越えることが出来ます。
さあ、本記事で得た知識を活かして、自分だけの理想のAIモデル制作に再挑戦しましょう。
サイト外リンク
: Kohya’s sd-scripts GitHub公式)
Hugging Face – Stable Diffusionモデル)
