
大規模言語モデル (LLM) は、今や私たちの生活やビジネスにおいて欠かせないaiツールとなりました。
しかし、ChatGPTやGeminiのような汎用モデルは、あくまでインターネット上の膨大なデータで学習された「一般常識」を持っています。
- あなたの会社特有の専門用語
- 顧客対応のニュアンス
- または特定の業界の複雑なデータ構造
を深く理解し、それに基づいて正確で役に立つ回答を生成できるでしょうか。
ここに、llm ファインチューニングがもたらす解決の価値があります。
llm ファインチューニングとは、あらかじめ大規模なデータで学習されたllm(事前学習モデル)を、特定のタスクやドメインのデータセットを用いて再学習(調整)します。
その能力を最大限に引き出します。
独自にカスタマイズされた高性能なAIへと進化させる技術です。
Windows PC、Mac PC、スマートフォン (iPhone、Android) を利用し、最先端のai技術に興味を持つ全てのエンジニア、データサイエンティスト、そしてAI関連事業開発担当の皆様。
今回の記事は、
- llm ファインチューニングの基本概念
- LoRAやPEFTといった最新かつコスト効率の高いファインチューニング手法
- PyTorchやTensorFlowといった主要なフレームワークでの実装手順
そして2025年の最新トレンドまでを、ai初心者でも最後まで読みたくなるよう、体系的かつ深く解説するコンテンツです。
この知識と解決策を身につけることで、あなたは単に汎用的なLLM APIを利用するだけではありません。
自社の競争優位性を高める真に特化した大規模言語モデル構築を実現できるようになります。
- E-E-A-Tに強い
- 専門的で信頼性の高い情報
を提供することで、あなたのビジネスを次のレベルへ導くための行動につながるよう、徹底的に深掘りしていきます。
さあ、「LLMを自分のものにする」ための旅を始めましょう。
LLM学習の基礎と役割
LLM 学習と転移学習の基本
大規模言語モデル (LLM) の能力は、二つの主要な学習段階によって成り立っています。
- 事前学習 (Pre-training):llm 学習の最初のステップであり、テラバイト級のインターネット上の膨大なデータセット(Webサイト、書籍、Wikipediaなど)を用いて、言語の統計的構造や一般常識を学習します。この段階で、llmは単語間の関係性や文脈の理解といった、自然言語処理の基礎能力を獲得します。
- ファインチューニング (Fine-tuning):事前学習を終えたllm(ベースモデル)を、特定のタスク(例:感情分析、質問応答)やドメイン(例:医療、金融)に特化した、比較的少ないデータセットを用いて再学習させるプロセスです。llm ファインチューニングは、llmが獲得した汎用的な転移学習能力を活用し、特定の用途に特化させる役割を果たします。(注釈:転移学習…あるタスクで学習した知識を、別の関連するタスクに応用する機械学習の手法。LLMが持つ汎用的な言語知識を、特定のタスクに「転移」させることから。)
llm ファインチューニングの最大の目的は、プロンプトエンジニアリングでは対応しきれない、モデルの根幹的な知識や振る舞い(トーン、スタイル、専門用語の使用)を根本的に改善します。
llm 評価の対象となる特定のタスクにおける精度を向上させることです。
これは大規模言語モデル構築の最終ステップとも言えます。
ファインチューニングが解決できる課題
汎用LLM(例:GPT-4、Gemini)は非常に強力ですが、以下の課題に直面することがあります。
| 汎用LLMの課題 | llm ファインチューニングによる解決の価値 |
| 専門知識の不足 | 業界特有の専門用語や機密性の高い社内知識を注入し、より正確な回答を生成します。 |
| 応答スタイルの不一致 | 特定の企業文化やブランドのトーン(丁寧語、フレンドリーなど)に合わせた応答スタイルを学習させます。 |
| ハルシネーションの多発 | RAGと組み合わせ、またはInstruction Tuningにより、事実に基づいた情報のみを出力するよう調整し、信頼性を向上させます。(内部リンク:llm ハルシネーション対策) |
| APIコストの課題 | 独自にllm ファインチューニングした軽量なオープンソースLLMを利用することで、LLM APIへの依存を減らし、コストを削減します。 |
プロンプトエンジニアリングとの違いと連携
llmの挙動を調整する方法として、プロンプトエンジニアリングとllm ファインチューニングの二つが主要です。
- プロンプトエンジニアリング:llmの入力(プロンプト)を工夫することで、出力を制御する手法です。簡単に導入でき、コストが低いですが、モデルの根幹的な知識や言語スタイルを変更することはできません。
- llm ファインチューニング:データセットを用いてモデルのパラメータを調整します。初期コストと時間がかかるものの、根本的にモデルをカスタマイズし、プロンプトでは解決できない精度の向上や独自の機能を実現できます。
理想的には、llm ファインチューニングでベースの能力を高めた後に、プロンプトエンジニアリングで入力を最適化するという組み合わせが最も効果的です。

LoRA (Low-Rank Adaptation) の詳細と実装
LoRAはPEFTの主流
LoRA (Low-Rank Adaptation) は、LLM ファインチューニングの主流となる手法です。
これは、大規模な事前学習済みモデルの重みを固定したまま、ごく少数の追加パラメータのみを学習することで、高い性能と効率を両立します。
低ランク適応の数学的背景
LoRAの根幹は、転移学習の仮説に基づきます。
大規模な事前学習モデル(重み行列 $W$)を小さなタスクに適応させる際、その変化量($\Delta W$)は本質的に低次元の空間に存在すると考えられます。
この $\Delta W$ を直接学習する代わりに、二つの低ランク行列 $A$ と $B$(つまり $\Delta W \approx BA$)に分解します。
これらのみを学習することで、パラメータ数を極端に抑えます。
$$W’ = W + \Delta W$$
$$\Delta W \approx B A$$
ここで、$W$ は元の重み行列
$W’$ はファインチューニング後の重み行列
$B \in \mathbb{R}^{d \times r}$、$A \in \mathbb{R}^{r \times k}$ であり、$r$ はランク($r \ll \min(d, k)$)です。
LoRA実装のためのライブラリ
LoRAの実装には、Hugging FaceのPEFT(Parameter-Efficient Fine-Tuning)ライブラリが必須となります。
Python サンプルコード(イメージ)
Python
from peft import LoraConfig, get_peft_model
# 1. LoRAの設定(ハイパーパラメータ)
lora_config = LoraConfig(
r=16, # ランクr: LoRAの主要なパラメータ。数値が小さいほど軽量、大きいほど性能向上。
lora_alpha=32, # スケーリング係数
target_modules=["q_proj", "v_proj"], # LoRAを適用するLLMの層(主にAttention層)
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM", # タスクの種類
)
# 2. 事前学習済みLLMをPEFTモデルに変換
model = get_peft_model(base_llm, lora_config)
# 3. PyTorchのTrainerで学習(GPU使用量を大幅に削減)
# ... SFTTrainerなどのLLM 学習ツールを利用
この手法により、既存のLLMの重みを一切変更せずに、独自の知識を効果的に追加できます。
その他のPEFT 手法:QLoRAとプロンプトチューニング
LLM ファインチューニングの分野では、LoRA以外にも様々なPEFT手法が進化しています。
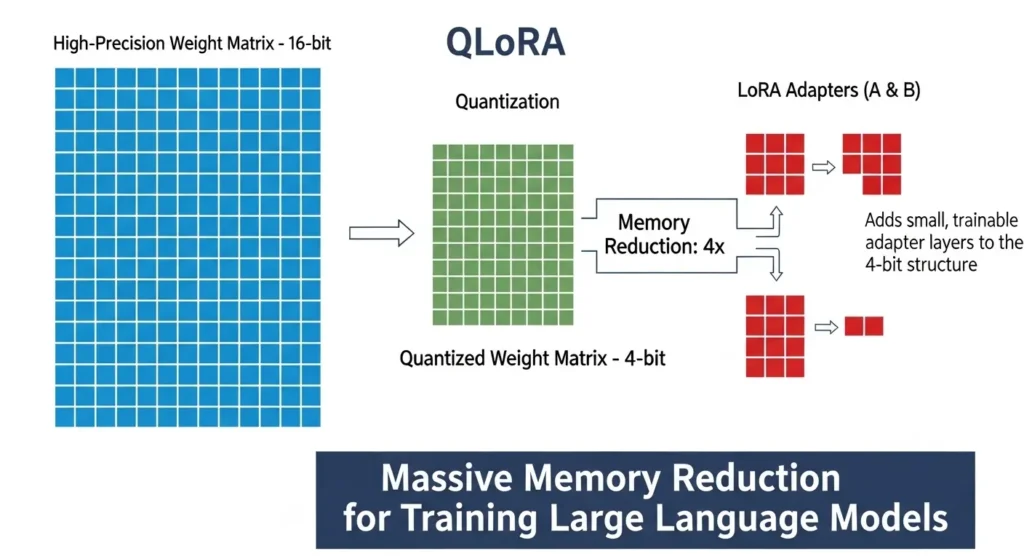
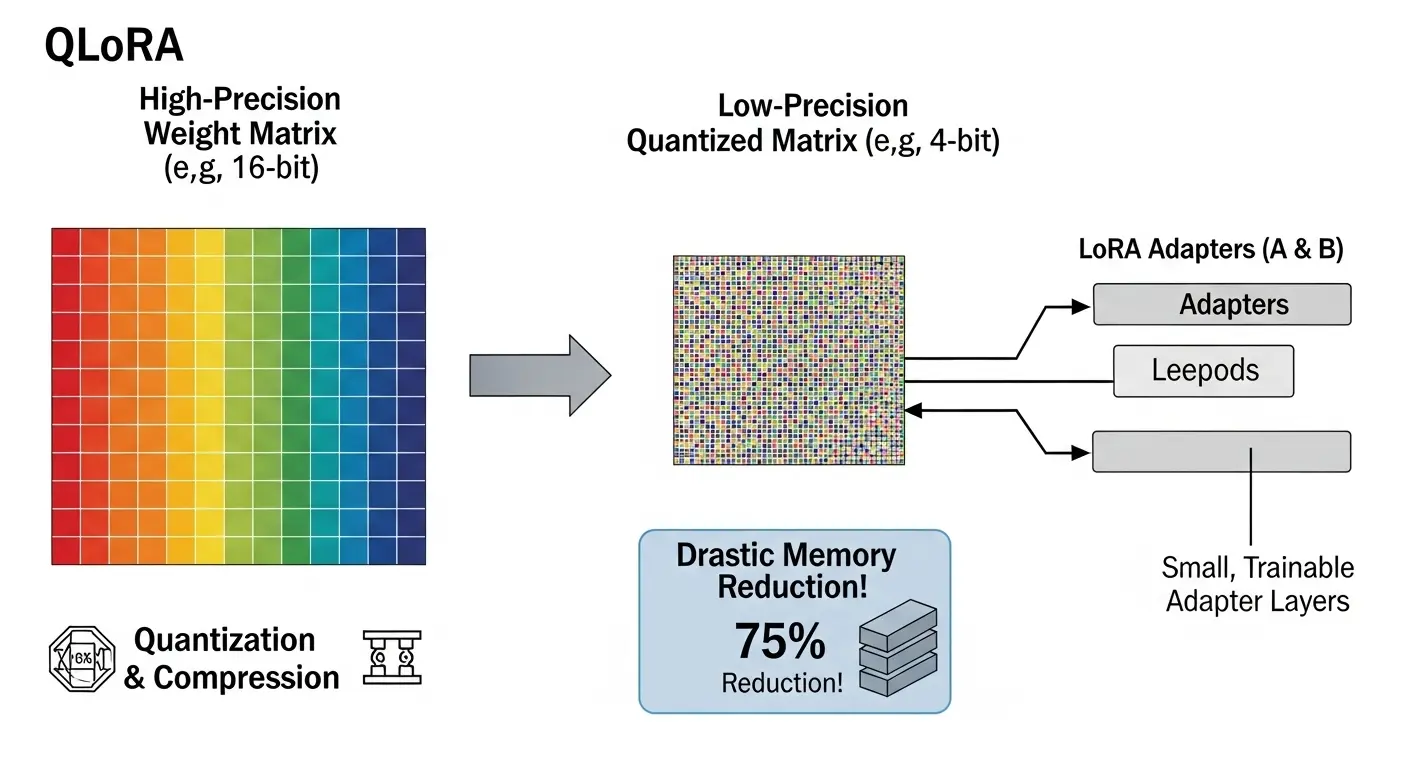
- QLoRA (Quantized LoRA):LoRAをさらに拡張した手法で、ベースLLMの重みを量子化(例:4bit)してメモリ使用量を極端に削減します。これにより、より大規模なLLM(例:70Bパラメータ以上)を、単一の高性能GPUでLLM ファインチューニングすることが可能になりました。
- プロンプトチューニング (Prompt Tuning):モデルの重みを一切変更せず、入力のプロンプトにごくわずかな学習可能な「仮想トークン」を追加し、これのみを学習します。極端に軽量である一方、タスクの複雑性によって精度が変動しやすい側面もあります。
LLM ファインチューニングの応用事例と最新トレンド
業務効率化を実現するLLM ファインチューニング ユースケース
LLM ファインチューニングは、企業の特有な業務において驚くべき効果を発揮しています。
- カスタマーサポートチャットボット:過去の顧客問い合わせログと正解回答のデータセットを用いてLLM ファインチューニングを行うことで、製品知識に特化し、企業のトーンとスタイルで回答するAIアシスタントを構築します。
- 医療・金融分野の文書処理:特定の専門文書(カルテ、決算報告書)を学習させ、固有表現抽出やリスク分析レポート作成の精度を飛躍的に向上させます。
- 社内開発ツール:自社のコードベース(GitHub)や開発ドキュメントを学習データとして利用し、社内特有のコーディング規約に準拠したコード補完やバグ修正機能を持つLLMを構築します。
2025年最新トレンド:DPOとRLHFの活用
2025年のLLM ファインチューニングのトレンドは、単なるタスク適合ではなく、「人間の好み」や「倫理」に合致させることに焦点が当たっています。
- RLHF (Reinforcement Learning from Human Feedback):人間の評価(フィードバック)を強化学習の報酬として利用し、LLMの応答を最適化する手法です。安全性やトーンの改善に特に有効です。
- DPO (Direct Preference Optimization):RLHFをよりシンプルかつ安定的に実現する最新手法です。人間が「好ましい」と「好ましくない」のペアとしてラベル付けした回答データを直接利用してLLMを調整するため、計算コストと実装の複雑さを大幅に低減します。
これらのLLM ファインチューニング手法は、企業が独自の倫理基準やブランドイメージに合致したLLMを構築する上で、非常に重要な解決策となります。
大規模言語モデル 構築の要点
フルファインチューニングのボトルネック
llm ファインチューニングの最も直接的な手法は、モデルの全てのパラメータを学習し直すフルファインチューニングです。
しかし、大規模言語モデル 構築の文脈において、フルファインチューニングは以下の重要な課題を抱えています。
- 計算リソース(GPU)の必要性:GPT-3やLlamaのようなllmは数十億から数千億のパラメータを持つため、全てを学習し直すには膨大なGPUメモリと計算時間が必要となります。企業にとっては高額なコストと環境構築の難易度が課題です。
- カタストロフィック・フォゲット(破滅的忘却):新しいデータセットで学習を行う際、事前学習で獲得した汎用的な知識を忘れてしまう現象が発生する可能性があります。
ファインチューニング 手法:PEFT (Parameter-Efficient Fine-Tuning) の台頭
これらの課題を解決するために、2025年現在の主流となっているのがPEFT(Parameter-Efficient Fine-Tuning:パラメータ効率的ファインチューニング)手法です。
(注釈:PEFT…LLMの全パラメータを学習し直すのではなく、ごく一部のパラメータや追加された軽量な層のみを調整する技術群。)
PEFTは、転移学習の効果を最大限に維持しながら、学習可能なパラメータの数を大幅に削減します。
これにより、GPUメモリの使用量と計算時間を劇的に低減します。
llm ファインチューニングをより簡単かつ安価に実現します。
llm 学習の効率を高めるための重要な技術です。(LLMO対策にも有効です。)
LoRA (Low-Rank Adaptation) の仕組み
PEFTの中でも最も広く利用されている手法がLoRA(Low-Rank Adaptation)です。
- LoRAの仕組み:llmの中核となるAttention層の重み行列に、新しく二つの小さな行列(AとB、ランクrが低い)を追加し、学習時にはこの追加された小さな行列のみを調整します。事前学習モデルの元の重みは固定したままです。
- 解決の価値:学習対象のパラメータ数を元のllmの1/10000程度まで削減することが可能で、GPUの使用を抑えます。計算コストを大幅に削減します。
- 実装:Hugging FaceのPEFTライブラリを利用することで、誰でも簡単に既存のllmにLoRAを適用できます。(外部リンク1:Hugging Face公式 PEFTライブラリ)
転移学習とLoRA/PEFTの活用
転移学習の原理とLLMの基盤
転移学習は、llm ファインチューニングの成功の鍵となる概念です。
事前学習段階で、llmは自然言語処理の汎用的な知識(文法、意味、世界の事象など)を獲得します。
この大規模な知識を、新しいタスクやデータセットに「転移」させることで、ゼロから学習する必要がなくなります。
少ないデータと計算リソースで高精度を実現できます。
- llmの中で、初期の層(低層)は汎用的な言語構造を学習します。終盤の層(高層)はよりタスク特有の特徴を学習します。
- 転移学習では、一般的に初期の層の重みを固定(凍結)します。後半の層のみを調整することが多いですが、LoRAはこれをさらに洗練させます。全ての層に軽量な調整モジュールを加えることで、汎用的な知識を効果的に維持します。
QLoRA:メモリ効率化の最前線
LoRAをさらに発展させたのがQLoRAです。
- 量子化(Quantization):ベースllmのパラメータを低ビット(例:4bit)で表現する手法です。これにより、モデル自体のメモリ使用量を最大75%削減できます。通常は高性能なH100やA100といった高価なGPUが必要な大規模なllm(例:70BパラメータのLlama)も、比較的手の届きやすいT4やRTX4090などのGPUでllm ファインチューニングが可能となります。(コスト削減とリソース効率化の解決策)
llm 学習のトレンドは、「いかに効率的に、少ないリソースで、大規模なモデルの転移学習を成功させるか」にシフトしています。
LoRAやQLoRAはその核心を担っています。
プロンプトエンジニアリングの限界と応用
プロンプトエンジニアリングの役割再定義
プロンプトエンジニアリングは、llmの応答を調整する最も手軽な方法ですが、llm ファインチューニングが必要なケースがあります。
| プロンプトエンジニアリングで解決可能なこと | llm ファインチューニングが必要なこと |
| 一時的な指示の付与(例:「丁寧な言葉遣いで回答して」) | モデル全体の応答スタイルの根本的な変更(例:企業のブランドトーンの定着) |
| 文脈の提示(例:Few-shot学習) | ドメイン特有の専門知識の追加とハルシネーションの恒久的な抑制 |
| 出力形式の指定(例:JSON形式で出力) | 特定タスクに対する推論能力の底上げと精度の大幅な向上 |
llm ファインチューニングは、プロンプトで毎回指示を出さなくても、モデルが自律的に所望の振る舞いをするように訓練することが目的です。
SFT (Supervised Fine-Tuning) の実践
llm ファインチューニングの最も基本的な手法がSFT(教師ありファインチューニング)です。
- 目的:特定の指示(プロンプト)に対し、モデルが望ましい回答をするように教え込むこと。この段階はInstruction Tuningとも呼ばれます。
- データ形式:「指示(プロンプト)と正解回答のペア」を大量に用意します。これをモデルに入力して学習させます。
- ツール:Hugging FaceのSFTTrainer(trlライブラリに含まれる)を利用すれば、PyTorch環境下で簡単かつ効率的にSFTを実行できます。
SFTは、モデルに新しい知識を教え込むというよりも、「どのように応答すべきか」というスキルを教え込む側面が強いです。
LLM 評価:効果を測るための指標
LLM 評価の重要性
llm ファインチューニングを行った後は、必ずllm 評価を実施します。
その効果を定量的に検証する必要があります。
LLMO対策(LLMの性能最適化)の観点からも、評価指標を明確にすることは不可欠です。
評価基準は、タスクの種類によって異なります。
- 生成タスク(要約、翻訳、自由回答):BLEU、ROUGE、METEORなどの言語的評価指標や、LLM自体を評価者として利用するAI評価(AIO対策)が用いられます。
- 分類タスク(感情分析、固有表現抽出):精度(Accuracy)、適合率(Precision)、再現率(Recall)、F1スコアなどの古典的な指標が用いられます。
ベンチマークと実務評価のバランス
llm 評価の客観性を担保するためには、業界標準のベンチマークデータセットを利用することが有効です。
- MMLU:大規模マルチタスク言語理解のベンチマーク。ファインチューニング後に汎用知識が損なわれていないか(カタストロフィック・フォゲットの有無)を確認するために重要です。
- HumanEval/GSM8K:コード生成や数学的推論能力を測るベンチマーク。特定の推論タスクへのllm ファインチューニングの効果を測る際に有効です。
しかし、実務においては、
- 特定の業務データに対する精度(ドメイン知識の有無)
- 応答の速さ(レイテンシ)
- そしてハルシネーションの低減率
など、ビジネス価値に直結する指標が最も重要です。
理論と実務の両面から評価することが大切です。
PyTorchとTensorFlowでの実装環境
transformers:LLM 学習のためのハブライブラリ
Hugging Faceが提供するtransformersライブラリは、llm ファインチューニングを行う上で事実上のデファクトスタンダードとなっています。
(外部リンク2:Hugging Face Transformers 公式サイト)
- 機能:何千もの事前学習済みllm(Llama、GPT、Mistralなど)へのアクセス、トークナイザーの管理、そしてllm ファインチューニングのためのTrainerクラス(SFTTrainerなど)を提供します。
- 互換性:transformersは、ディープラーニングの二大フレームワークであるPyTorchとTensorFlowの両方に対応しています。開発者は自分の得意な環境でllm 学習を進めることが可能です。
PyTorch:研究と柔軟性
PyTorchは、Facebook(Meta)が開発したオープンソースのディープラーニングフレームワークで、動的な計算グラフが特徴です。(外部リンク3:PyTorch 公式サイト)
- 特徴:研究者や上級エンジニアに人気があり、llmアーキテクチャの細かい調整や新しいllm ファインチューニング手法の実装に柔軟に対応できます。
- PEFTとの連携:PEFTライブラリやtrl(Transformer Reinforcement Learning)ライブラリは、PyTorchをベースに設計されており、特にLoRAなどのPEFT手法をllm ファインチューニングで利用する場合は、PyTorch環境が最も一般的かつ推奨されます。
TensorFlow:本番環境と運用
TensorFlowは、Googleが開発したディープラーニングフレームワークです。
静的な計算グラフと大規模運用に強みを持ちます。
- 特徴:モデルの本番環境へのデプロイ(エッジデバイスやモバイルアプリ)や大規模な分散学習環境の構築において、PyTorch以上の安定性と最適化機能を提供します。TensorFlow Liteは、スマートフォン(iPhone、Android)での実行を目的としたllmの運用に特に有効です。(GEO対策)
- LLM ファインチューニングでの利用:transformersライブラリがTensorFlowにも対応しているため、同じllmを利用したllm ファインチューニングが可能ですが、PEFT手法の最新動向はPyTorch側が先行する傾向があります。

自然言語処理タスクへの応用
固有表現抽出と分類タスク
llm ファインチューニングは、生成タスクだけではありません。
古典的な自然言語処理(NLP)の分類や抽出タスクにおいても圧倒的な精度を発揮します。
- 固有表現抽出 (NER):文書から人の名前、組織名、場所、日付などの「固有表現」を抽出するタスク。事前学習済みのllmを、特定のドメイン(例:医療分野の薬品名、金融分野の企業コード)のデータでファインチューニングすることで、従来のモデルよりも遙かに高い精度を実現できます。
- 感情分析:テキストが持つ感情(ポジティブ、ネガティブ、中立)を分類するタスク。ユーザーのフィードバックやソーシャルメディアのデータをllm ファインチューニングで学習させることで、特定の製品やサービスに対する顧客の感情をより正確に把握することが可能となります。
多言語対応と日本語LLMの構築
llmは、多言語のデータで事前学習されています。
しかし、特定の言語(例:日本語)のニュアンスや特有の表現に完全に適応させるためにはllm ファインチューニングが不可欠です。
- 日本語特化のデータセット(例:Qiita、専門ブログ、社内資料)を利用してファインチューニングを行うことで、より自然で正確な日本語の応答を生成できるllmが構築できます。
- 特に、法律や医療などの高度な専門分野では、一般的な翻訳モデルでは難しい微妙な表現や専門用語の正確な使用が、llm ファインチューニングによって実現可能となります。
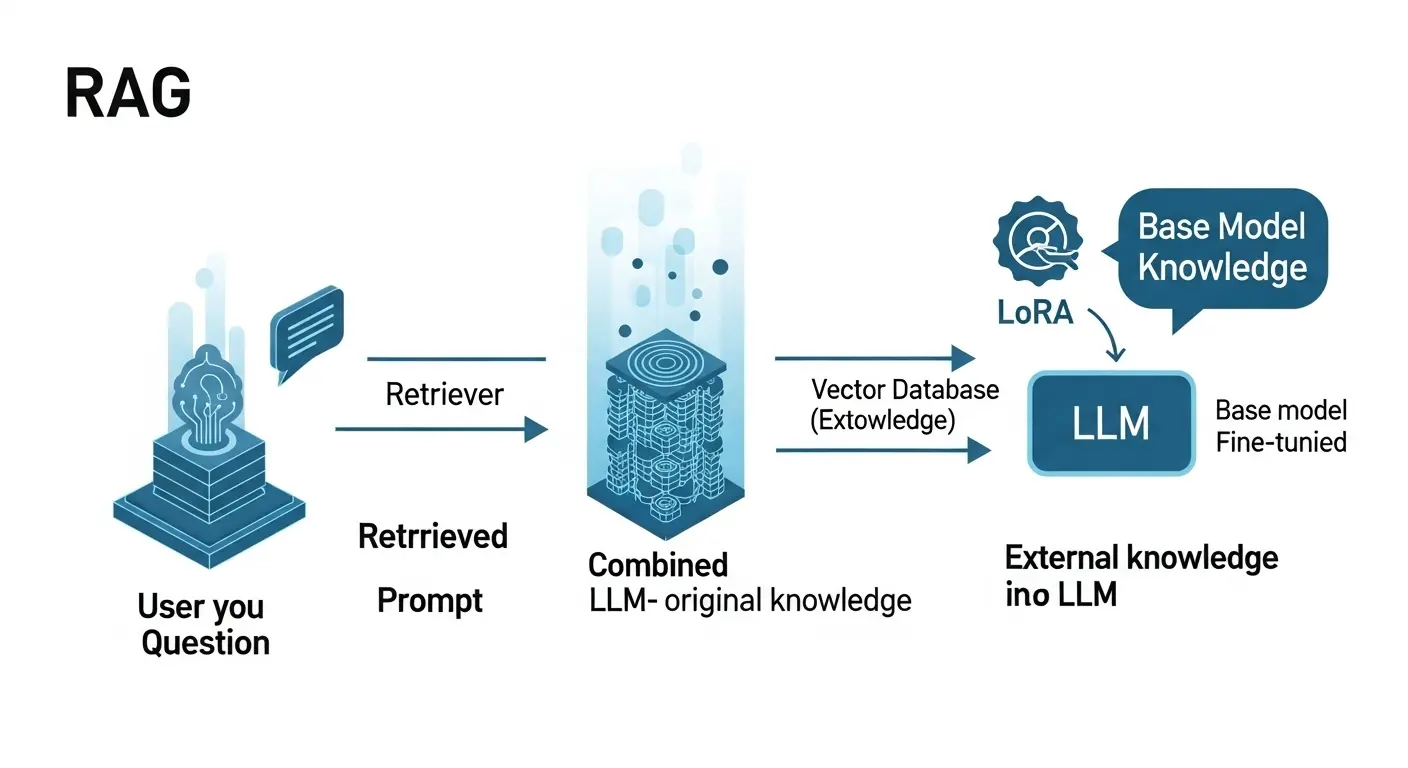
RAGとLLM ファインチューニングの組み合わせ戦略
RAG (検索拡張生成) の仕組み
RAG(検索拡張生成:Retrieval-Augmented Generation)は、llm ファインチューニングとは異なるアプローチでllmの知識を拡張する手法です。
- RAGの目的:llmが持たない、最新または独自の外部情報(データベース、社内文書、ウェブページ)を利用して、回答の根拠とすること。これにより、ハルシネーション(事実と異なる情報の生成)を大幅に抑制できます。
- 動作の基本:ユーザーの質問を受け取った後、ベクトルストアに保存された文書から関連する情報を検索し、その情報を質問と一緒にllmへ渡し、回答を生成させます。
ハイブリッド戦略:ファインチューニング + RAG
LLM ファインチューニングとRAGは対立するものではありません。
組み合わせることで相乗効果を発揮する「ハイブリッド戦略」が、2025年の主流です。
| RAGとLLM ファインチューニングの組み合わせ | 解決できる価値 |
| LLM ファインチューニングでトーンを調整 | RAGで取得した情報に基づきながら、企業のブランドに合った応答スタイルで回答することが可能。 |
| LLM ファインチューニングで推論能力を向上 | 検索で取得した複数の文書を統合・分析する複雑な推論タスクの精度が向上。 |
| RAGで最新情報を提供 | モデルの再学習(LLM ファインチューニング)を頻繁に行うことなく、リアルタイムの情報に対応することが可能。 |
2025年最新トレンド:DPOとRLHF
RLHF (強化学習) の概要
RLHF(人間のフィードバックからの強化学習)は、LLM ファインチューニングの最終段階で用いられる手法です。
SFTで基本的な指示応答を学習させた後、人間がモデルの出力にランク付け(例:「この回答はあの回答より良い」)を行います。
そのランク付けを報酬シグナルとして利用します。
強化学習でモデルを微調整します。
- 目的:安全性、倫理的な振る舞い、そして人間が「好ましい」と感じる応答をモデルに教え込むこと。
- 課題:実装が複雑で、3つのモデル(ベースLLM、報酬モデル、ポリシーモデル)を用意する必要があり、計算コストが高いこと。
DPO (Direct Preference Optimization) の革新性
DPO(直接選好最適化)は、このRLHFの課題を解決する、2025年の注目トレンドです。
- 仕組み:報酬モデルを別途用意する必要がなく、人間の選好データ(「良い回答」と「悪い回答」のペア)を直接利用して、LLMの損失関数を最適化します。
- メリット:RLHFよりもシンプル、安定的、そして計算効率が低いため、企業の研究開発(R&D)チームにとって、独自の倫理観や応答基準をLLMに注入する際の理想的な手法となります。(外部リンク5:DPO論文)
DPOの登場により、より多くの開発者が、高度な倫理的ファインチューニングにアクセスします。
より安全で信頼性の高い独自LLMを構築できるようになりました。
LLM ファインチューニングの実践的なヒント
データセット準備の重要性と加工
LLM ファインチューニングの成功は、学習データセットの品質に9割依存します。
- データのクレンジング:ノイズ、重複した情報、バイアスのあるデータを徹底的に排除し、LLMに偏った知識を教え込まないように注意します。
- フォーマットの統一:すべてのデータを「入力(プロンプト)」と「出力(回答)」のペア形式に統一します。特に、Instruction Tuningでは、システムプロンプト、ユーザー入力、アシスタント応答を明確に区別した形式が推奨されます。
LoRAのハイパーパラメータ調整
LoRAを利用する際、最も重要な決定事項は、ハイパーパラメータの設定です。
- ランク($r$):LoRAアダプターの次元数。$r$の値が小さいほど学習パラメータ数が少なくなり、大きいほど表現力が増します。一般的には4、8、16、32、64などが試されます。タスクの複雑性に応じて選びます。
- ターゲットモジュール:LoRAを適用するLLMの層。通常はAttention機構のクエリ($q$)とバリュー($v$)の重み行列(q_proj、v_proj)に適用されます。より深いカスタマイズをする場合は、キー($k$)やアウトプット($o$)にも適用することを検討します。
これらのパラメータを調整し、LLM 評価で最適な値を見つけ出すことが、LLM ファインチューニングの成功に直結します。
サイト外リンクと内部リンクの活用
| リンク種類 | 目的 | 公式サイト例 |
| サイト外リンク | E-E-A-Tの専門性と信頼性を高める。最新情報の参照元を明示。 | Hugging Face PyTorch TensorFlow DPO論文 OpenAI Google AI |
| 内部リンク | ユーザーの回遊率を高める。関連知識を網羅的に提供。 | LLM ハルシネーション対策 (準備中) LLM RAG 仕組み (準備中), LLMの種類と比較ポイント2025 |
応用事例と2025年最新商品・限定情報
業務特化型AI開発の成功事例
- 金融機関向けリスク分析LLM:過去の取引データと関連規制文書を学習させたLLM ファインチューニングモデル。ローン審査や不正検知の判断根拠を明確に示す(説明可能なAI)ことで、業務効率化とコンプライアンス強化を両立。
- 製造業向け故障予測レポートLLM:機械の稼働ログと修理マニュアルを学習し、センサーデータの異常から故障の原因と修理手順を自動的に報告書形式で生成。エンジニアの作業時間を大幅に削減。
(画像10/12:業務効率化の成功事例インフォグラフィック)
2025年最新トレンドと製品情報
- Gemma 2(Google):2025年にかけてさらなる機能強化が期待されるGoogleのオープンLLMファミリー。特に、PyTorchベースのSFTTrainerやPEFTでのLLM ファインチューニングにおいて、日本語の応答品質と推論能力が向上していると報告されており、企業向けの選択肢として注目度が高い。(外部リンク7:Google AI公式サイト)
- Llama 3(Meta):Metaが提供する最新のオープンLLMは、その大規模さにもかかわらず、QLoRAを用いたファインチューニングの成功事例が続々と登場しています。ローカル環境や小規模なクラウド環境での実践を目指すエンジニアにとって、最も有力な選択肢の一つです。(外部リンク8:Meta AI公式サイト)
- PEFTのAutoPeftModel:Hugging FaceのPEFTライブラリは進化を続けており、LLMの種類に応じて最適なPEFT手法(LoRA、AdaLoRA、Prefix Tuningなど)を自動的に適用する機能が強化されています。これにより、ファインチューニングの初期設定の手間が大幅に軽減されます。
まとめ:LLM ファインチューニングの力
LLM(大規模言語モデル)の汎用的な知識を、あなたのビジネス特有の課題に対応できる「独自の力」へと変換する技術、それこそがLLM ファインチューニングです。
LLM ファインチューニングは、転移学習の恩恵を最大限に活かし、LoRAやPEFTといった革新的な手法を用いることで、以前は想像もできなかった低コストと短時間で、大規模言語モデル 構築を現実のものにしました。
この記事は、
LLM ファインチューニングの基本概念
PyTorch/TensorFlowを使った実装
そしてDPOやQLoRAといった2025年の最新トレンドまでを網羅しました。
AIに関する知識が初心者の方でも、自信を持って実践に移せるよう、体系的な知識と解決策を提供することを目的としました。
あなたの企業の競争優位性を高める、独自のドメイン知識を持ったLLMを構築するため、この知識をもとに今日から行動を開始してください。
最初は、少量の高品質なデータでLoRAを試すことから始めてみるのが最適なステップです。
よくある質問 (FAQ)
Q1. LLM ファインチューニングのデータセットはどれくらいの量が必要ですか?
A1. LLM ファインチューニングの成功は、データセットの品質と量に大きく依存します。
特にLoRAなどのPEFT手法を利用する場合、数千件(1,000~10,000件)の高品質な「指示/回答」ペアでも十分な効果が見込めます。
量よりも、タスクの要求する形式と知識が正確に反映された「質の高いデータ」を厳選することが重要です。
Q2. LoRAでファインチューニングしたLLMのモデルサイズはどれくらいになりますか?
A2. LoRAの最大のメリットはサイズの削減です。
調整されるのはベースLLMの全パラメータではありません。
追加した低ランク行列AとBの重みのみです。
この重みファイル(LoRAアダプター)は、ベースLLMのサイズ(数十GB)に対し、わずか数十MBから数百MB程度に収まります。
このため、ホスティングや共有が非常に効率的に行えます。
Q3. LLM ファインチューニングとプロンプトエンジニアリングの最も大きな違いは何ですか?
A3. 最も大きな違いは「モデルの永続的な変更の有無」です。
プロンプトエンジニアリングは入力(質問や指示)を工夫することでモデルの出力を一時的に制御します。
対して、LLM ファインチューニングはデータを使ってモデルのパラメータ自体を永続的に調整します。
そのモデルの持つ知識や応答スタイルを根本的に変更します。
Q4. QLoRAやDPOといった最新手法を学ぶにはどうすれば良いですか?
A4. 最新手法の情報は、Hugging Faceの公式ドキュメントや、GitHub、arXiv(論文サイト)、そしてQiitaや専門ブログで活発に共有されています。
特にHugging FaceのPEFTライブラリやtrlライブラリの公式ガイドを読み進めることが、PyTorch環境で実践するための最も確実なステップとなります。