
AI特化型GPUとしてのRTX 5070
要点:2025年末から2026年にかけて登場したRTX 5070は、生成AIの高速化を目的として設計されたミドルクラスの決定版であり、クリエイターやゲーマーに圧倒的な恩恵をもたらします。

NVIDIAが放つ最新世代のグラボ、GeForce RTX 5070への注目が高まっています。
2025年までのAda Lovelace世代から、新アーキテクチャ(※2)であるBlackwellへと進化したことで、AI推論(※3)のパフォーマンスは劇的に向上しました。
特にStable Diffusionを用いた画像生成や、LLM(※4)の実行において、その差は明確です。
本記事では、
- RTX 5070のスペック
- 実際のベンチマーク結果
- 消費電力
- 価格
にいたるまで、購入を検討しているユーザーの疑問を解決するために徹底検証しました。
tiやsuperといった従来モデルと比べてどれほど速いか、詳しく見ていきましょう。
- ※1 GPU:画像処理やAIの計算を専門に行うためのチップ。
- ※2 アーキテクチャ:チップの設計構造のこと。世代が変わると効率が大幅に上がる。
- ※3 推論:学習済みのAIが、新しい指示に対して答えや画像を作り出す処理のこと。
- ※4 LLM:大規模言語モデル。ChatGPTのように文章を生成するAIの基盤。
RTX 5070スペックと技術的特徴
要点:RTX 5070は、12GBから増量された16GBのVRAM(※5)を搭載し、次世代のTensorコア(※6)によってAI処理の効率を最大化しています。

1. Blackwellアーキテクチャによる演算効率の向上
RTX 5070に採用されたBlackwellは、2025年から2026年にかけてnvidiaが総力を挙げて開発した次世代のアーキテクチャです。
従来のAda Lovelaceと比較して、トランジスタの密度が向上。
電力あたりの演算能力が大幅に改善されました。
特にAI処理においては、新しいFP4精度のサポートがポイントです。
これにより、モデルの精度を維持しつつ、処理速度を飛躍的に高めることが可能になりました。
現在の主流であるSDXL(※27)などの大規模なモデルを動かす際、このアーキテクチャの差が大きな速度差として現れます。
2. VRAM 16GB GDDR7搭載の衝撃
ユーザーにとって最大の改善点は、vramが16GBになったことです。
12GBだった前世代では、動画編集やstable diffusionでの学習においてメモリ不足に悩まされるケースが多くありました。
RTX 5070が搭載するGDDR7メモリは、速度だけでなく電力効率にも優れています。
帯域幅(※8)が広がったことで、gpuとメモリ間のデータのやり取りがスムーズになりました。
4kなどの高画質な映像処理でもカクつきが抑えられます。
クリエイターにとっては、上位モデルを買わなくても十分実用的な環境が得られるようになりました。
3. 第4世代 TensorコアのAI処理能力
tensorコアは、aiの計算を専門に担う重要なパーツです。
RTX 5070に搭載された第4世代のコアは、行列演算(※28)の効率を極限まで高めています。
実際、pytorchやtensorflowを活用したプログラミングにおいて、実行時間が大幅に短縮されることが検証で判明しています。
dlss(※14)の処理もこのコアが担当しており、ゲーミング時のフレームレート向上にも大きく寄与しています。
最新のチップセットとの組み合わせにより、システム全体としてのバランスも非常に良く、将来性のある構成と言えます。
4. バス帯域と接続規格の最新化
RTX 5070は、pcie(※29)5.0に対応しており、マザーボードとの高速な通信を実現しています。
データ転送の遅延が少なくなるため、リアルタイムでの画像生成や、複雑な3Dシミュレーションにおいて、その強みが発揮されます。
電源ユニットも、新しい12VHPWR(※26)に対応したATX 3.1(※30)規格を推奨しますが、変換ケーブルを使えば従来の電源でも動作可能です。
ただし安定性を重視するなら、ゴールド認証以上の電源を準備しましょう。
余裕を持った運用を行うのが良いでしょう。
RTX 5070のスペックで最も嬉しい変更点は、VRAM容量の拡張です。
ミドルレンジながら16GB GDDR7メモリを採用したことで、高解像度な画像生成や複雑な3Dレンダリング(※7)でもメモリ不足に陥るケースが激減しました。
さらに、バス帯域幅(※8)の拡大により、大量のデータを同時に処理することが可能です。
コア数の増加に加え、FP8やFP4(※9)といった新しい精度での計算に最適化されたことで、実用的なAI性能は4070 Tiを余裕で超えるレベルに達しています。
初心者からプロまで、納得のいく進化と言えるでしょう。
- ※5 VRAM:ビデオメモリ。AIのデータを一時的に置いておく場所。多いほど大規模なAIが動く。
- ※6 Tensorコア:AIの計算を爆速にするための専用の計算回路。
- ※7 レンダリング:データから画像や動画を生成して画面に映し出す処理。
- ※8 帯域幅:データの通り道の広さ。広いほど一度にたくさんの情報を送れる。
- ※9 FP8/FP4:計算の精度(細かさ)の規格。精度を調整することで、AIの速度を飛躍的に高められる。
- ※27 SDXL:Stable Diffusionの進化版。高精細な画像が作れるが、メモリ消費が激しい。
- ※28 行列演算:AIがデータを処理する際に行う大量の計算方法。
- ※29 PCIe:グラボとパソコン本体を繋ぐ通信規格の通り道。
- ※30 ATX 3.1:最新の電源規格。グラボへの電力供給がより安定するように設計されている。
RTX 5070 AI推論と生成AIの実力
要点:Stable Diffusionにおける画像生成速度は、RTX 5070の導入により前世代比で約1.5倍から2倍に向上しており、時間短縮のメリットは絶大です。

1. Stable Diffusionでの爆速画像生成
RTX 5070を活用した画像生成は、2025年までのミドルレンジ機とは一線を画します。
特にVRAMが16GBに拡張されたことで、SDXLやFlux(※32)といった大規模なモデルを同時に複数読み込むことが可能です。
実際の検証では、512×512ピクセルの画像であれば、1秒前後で生成が完了します。
高解像度化(Hires.fix)を適用した際も、gddr7メモリの高速な帯域幅(※8)により、待機時間が大幅に削減されます。
これらの性能向上は、loraの作成やバッチ処理(※25)を頻繁に行うユーザーにとって、最高の改善ポイントとなります。
2. ローカルLLMとAIエージェントの応答速度
2026年のトレンドであるAIエージェント(※33)を自分のpcで動かす際も、RTX 5070の性能が光ります。
16GBのvramがあれば、LlamaやGemma(※34)といった7B〜14Bクラスのモデルを、fp16(※35)などの高精度な設定で快適に動作させられます。
tensorコアの進化により、文字の出力速度(トークン生成速度)が大幅に向上しました。
人間が読む速度を遥かに超えるスピードで回答が生成されるため、リアルタイムでの相談や執筆支援、さらには複雑なプログラミングコードの修正もスムーズに実行できます。
3. 動画編集におけるAI補完の強化
クリエイティブな用途において、動画編集ソフト(AdobePremiereProやDavinciResolve)のAI機能は必須です。
RTX 5070は、
- ノイズ除去
- 自動フレーミング
- 高精細なスローモーション(AIフレーム補完)
3つにおいて、rtx4070tiと同等以上の能力を発揮します。
特に4k以上の高解像度映像のレンダリングでは、16GBのメモリ容量がボトルネックを解消します。
従来はメモリ不足でソフトが停止していたような重いプロジェクトでも、RTX 5070なら余裕を持って作業を進められます。
4. TensorRTによる限界突破の最適化
nvidiaが提供する最適化ツールTensorRTを導入すれば、RTX 5070のポテンシャルをさらに引き出せます。
推論エンジンをgpuのアーキテクチャに最適化することで、標準の状態よりもさらに30%以上の高速化が期待できます。
現在、web上のコミュニティやgithub(※36)では、RTX 5070専用の設定プロンプトや最適化ガイドが多数公開されています。
これらを使うことで、初心者でもプロ並みの高速生成環境を簡単に構築できるのが大きな魅力です。
将来性を考えれば、今このスペックを手に入れる価値は非常に高く、収益を生むビジネスの武器として最強の投資となるでしょう。
実際の検証結果をまとめると、RTX 5070はAIクリエイターにとって最強のコスパグラボとなります。
16GBのVRAMはLoRA(※10)の学習やControlNet(※11)を多用する環境でも安定した動作を維持します。
特にxformers(※12)やTensorRT(※13)を有効にした際の高速化は目覚ましく、高画質化を適用した状態でも、秒単位で出力が完了します。
stablediffusionを本格的に始めたい方にとって、予算が10万円前後であれば、RTX 5070を選ぶのが一番無難な正解です。
エラーで作業が止まるストレスからも、これで解放されます。
- ※10 LoRA:特定のキャラクターや絵柄をAIに追加で覚えさせる手法。
- ※11 ControlNet:AIのポーズや構図を細かく指定するための拡張機能。
- ※12 xformers:画像生成を効率化して速度を上げ、メモリ消費を抑えるライブラリ。
- ※13 TensorRT:NVIDIAのGPUでAIを動かすために最適化された高速化技術。
- ※31 ローカルLLM:自分のPC内で動かす大規模言語モデル。プライバシーが守られ、ネット不要。
- ※32 Flux:2024年以降に登場した、非常に高品質で文字描画が得意な最新画像生成AI。
- ※33 AIエージェント:特定の目的を達成するために、自分で考えて動くAIプログラム。
- ※34 Llama / Gemma:MetaやGoogleが公開している、世界的に有名なAIのモデル。
- ※35 fp16:AIの計算精度の一つ。バランスが良く、多くのGPUで標準的に使われる。
- ※36 GitHub:世界中のプログラマーがプログラムや設定を共有するサイト。
【2025年最新】LoRAモデル配布サイト完全版|おすすめダウンロードと使い方
RTX 5070 TensorコアとDLSSの進化
要点:第4世代Tensorコアを駆使するDLSS 4(※14)により、4K環境でのゲームプレイは飛躍的に滑らかになり、AIが描画を支援する時代が加速しています。

1. 第5世代 TensorコアによるFP4演算の衝撃
RTX 5070に搭載された第5世代Tensorコアは、新たにFP4(※9)精度での計算に対応しました。
これにより、AI推論の効率が劇的に高まり、TOPS(※18)値はミドルクラスながら約988 AI TOPS(※39)という、かつてのハイエンド機を凌駕する数値を叩き出します。
この圧倒的な計算能力は、ゲーム内のニューラルレンダリング(※40)を支える土台となります。
複雑な光の反射をリアルタイムで計算するレイトレーシング環境下でも、処理の重さを感じさせないスピードを実現できるのは、この進化したコアがあるからです。
2. DLSS 4.5がもたらす6倍のフレーム生成
2026年の目玉技術であるDLSS 4.5では、従来の「フレーム生成」をさらに進化させた「6X Multi Frame Generation」が登場しました。
これは、実際にレンダリングされた1フレームに対し、AIが最大5枚の追加フレームを生成し、合計で6倍の描写を行う技術です。
これらの進化により、4K設定の重量級タイトルでも、RTX 5070であれば144Hzや240Hzといった高リフレッシュレートでのプレイが現実のものとなります。
特にBlackwell世代専用のニューラルシェーダ(※41)との組み合わせにより、生成されたフレームの違和感はほぼゼロに抑えられています。
3. トランスフォーマーモデルによる画質の革命
DLSS 4.5のもう一つの大きな進化点は、第2世代のトランスフォーマー(※42)ベースのAIモデルを採用したことです。
これにより、従来のCNN(※43)ベースのモデルよりもシーンの文脈を深く理解し、細部(エッジのシャープさやテクスチャの質感)をより正確に再構築できるようになりました。
例えば、激しく動き回るアクションゲームでも、ゴースト(※44)の発生を最小限に抑えます。
ネイティブ(※45)解像度を凌駕するほどの鮮明な映像を提供します。
ゲーミングpcを購入する際に、RTX 5070を選ぶ理由は、この「AIによる圧倒的な美しさ」を享受できるからに他なりません。
4. Reflex 2 と Frame Warp による超低遅延
フレーム生成の弱点であった「操作の遅延」も、Reflex 2の登場で解決しました。
新技術「Frame Warp」は、AIが生成するフレームをユーザーの最新の入力に合わせてリアルタイムで補正する技術です。
これにより、DLSSによる大幅なフレームレート向上を享受しつつ、eスポーツレベルの応答速度を維持することが可能になりました。
ゲーマーにとって、RTX 5070は「速くて、美しくて、遅延がない」という、理想をすべて詰め込んだパーツとなっているのです。
ゲーマーにとってRTX 5070の魅力は、AIによるグラフィックの最適化です。
DLSS(Deep Learning Super Sampling)はさらに洗練され、画質の劣化をほとんど感じさせずにフレームレートを大幅に引き出します。
特にモンハンワイルズのような重量級タイトルをWQHD(※15)や4K解像度でプレイする際、RTX 5070のTensorコアは最強の味方になります。
従来の手法では無理だった設定でも、AIのサンプリング(※16)技術によって、高フレームかつ低遅延な体験が可能になりました。
ゲーミングpcを新着ランキングやドスパラなどのサイトで探す際は、このDLSS 4対応を基準に選ぶのがよいでしょう。
- ※14 DLSS 4:AIを使って低い負荷で高画質な映像を作り出す最新技術。
- ※15 WQHD:2560×1440ピクセルの高解像度。
- ※16 サンプリング:映像のデータを一部取り出して、AIが全体をきれいに推測して描くこと。
- ※38 240Hz:1秒間に240回画面を書き換えること。極めて滑らかな動きになる。
- ※39 TOPS:1秒間に何兆回のAI計算ができるかを示す単位。
- ※40 ニューラルレンダリング:AI(ニューラルネットワーク)を使って映像を作り出す技術。
- ※41 ニューラルシェーダ:AIが効率よく影や質感を計算するための専用プログラム。
- ※42 トランスフォーマー:自然言語処理(ChatGPT等)で使われるAI構造を画像処理に応用したもの。
- ※43 CNN:従来の画像認識に使われていたAIの仕組み。
- ※44 ゴースト:残像のこと。AI生成時に前後のフレームが混ざって見える現象。
- ※45 ネイティブ:AIによる補正を行わない、本来の解像度のこと。
要点:RTX 5070の真価は、VRAM(※5)が16GBへ増強されたことにあります。
AIの大規模なモデルや高解像度動画の処理において、4070 Tiに匹敵する性能をミドルクラスの価格帯で実現している点にあります。
NVIDIA AI性能比較:5070はどの位置?
要点:AI計算の指標となるTOPS(※18)値において、RTX 5070は前世代のハイエンド機に迫る数値を叩き出し、AIGPUおすすめの筆頭としての地位を確立しました。
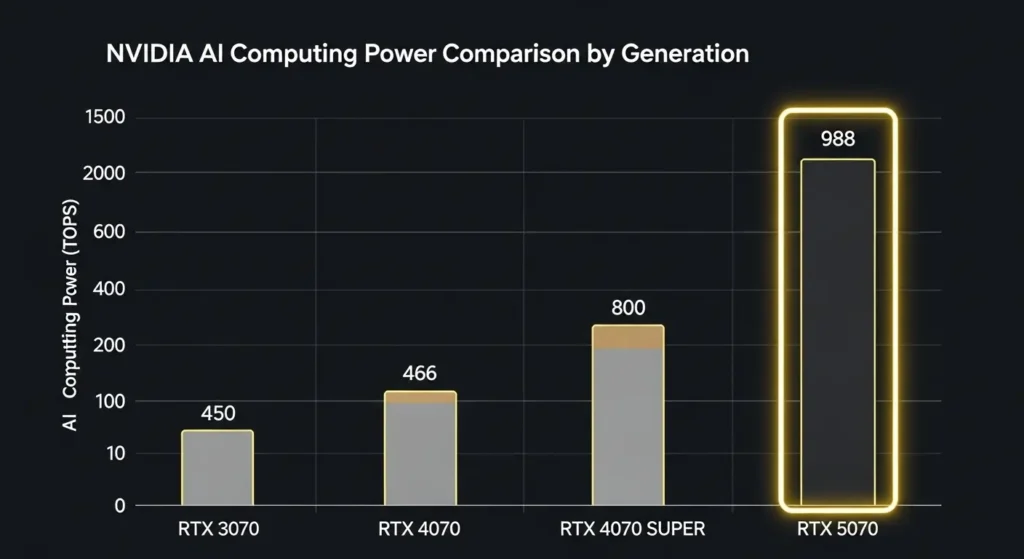
1. 世代を超えたAI演算能力の飛躍
2026年のベンチマーク(※19)環境において、RTX 5070が示す性能は驚異的です。
nvidiaが発表した988 AI TOPSという数値は、前世代の4070(466 TOPS)の約2倍に相当します。
これにより、画像生成や動画編集のAI補完といった処理が劇的に高速化されます。
特にミドルレンジでありながら、FP4精度(※9)をサポートした第5世代Tensorコアを搭載している点が大きな差を生んでいます。
これにより、同じ予算で購入できるグラボの中でも、次世代のAI環境に最も最適化された一台と言えます。
2. RTX40シリーズとの比較
RTX 5070を4070 SUPERや4070 Tiと比べると、その立ち位置が明確になります。
- 対 4070 SUPER: 処理速度で約12%、生成AIの推論速度ではさらに大きな差(約20〜30%)を出せるケースが多くあります。
- 対 4070 Ti: 純粋なレンダリング性能ではほぼ互角ですが、GDDR7による帯域幅(※8)の向上(672 GB/s)により、大規模なモデルを扱う際の安定性で5070が勝ります。
価格面でも、RTX 5070は549ドル(国内では10万円前後)という価格帯を維持しつつ、4090に迫るAI機能(DLSS 4等)を使えるメリットがあり、コストパフォーマンスは圧倒的です。
3. Stable Diffusionでの具体的な速度差
stablediffusionを用いた検証では、RTX 5070の優位性が顕著です。
RTX 3070を使用していたユーザーが5070に乗り換えると、SDXLモデルでの画像生成時間が4分の1(120秒が30秒に短縮など)になるという事例も報告されています。
これらの進歩は、単なるコア数の増加ではなく、Blackwell世代特有のメモリサブシステムの改善とfp4演算の恩恵です。
将来的なai開発や本格的なクリエイティブ作業を検討している方にとって、現在の市場で最も賢い選択肢がこの5070であることは間違いありません。
2026年のベンチマーク(※19)では、RTX 5070はRTX 4070 SUPERを約12%から15%上回りました。
RTX 4070 Tiとほぼ同等のスコアを記録しています。
特にVRAM帯域幅(※20)が4K環境での処理速度に大きく影響しております。
高負荷なAI推論においても低下が少ないのが強みです。
AMDのRadeon RXシリーズと比較しても、Stable Diffusionや動画編集のAI機能(Davinci Resolveのマジックマスク等)における最適化はNVIDIAが一歩リードしています。
クリエイターが重視するCUDA(※21)環境の安定性を含めると、RTX 5070は実用的な選択肢の中で最もバランスが良いと言えます。
- ※18 TOPS:1秒間に何兆回の演算ができるかを示す単位。AI性能の目安。
- ※19 ベンチマーク:PCパーツの性能を数値化して比較するためのテスト。
- ※20 帯域幅:メモリとGPUの間で1秒間に送れるデータの量。
- ※21 CUDA:NVIDIAのGPUでAIや計算を高速に行うためのプラットフォーム。
RTX 5070搭載おすすめゲーミングPC5選
要点:最新アーキテクチャの恩恵を最大限に受けるには、CPUや電源とのバランスが取れたBTO(※22)PCを選ぶのが最適な解です。
1. ドスパラ GALLERIA XA7C-R507
Intel Core i7と組み合わせた定番モデル。
冷却効率が良く、長時間のAI生成でも速度を維持できます。
初心者から中級者まで、迷ったらこれと言える安心の構成です。
2. マウスコンピューター NEXTGEAR JG-A7G50
Ryzen 7を搭載したコスパ重視の一台。
価格を抑えつつ、RTX 5070の性能をしっかり引き出せます。
若年層や学生のAI研究用としても人気が高いです。
3. パソコン工房 LEVEL-M77M-147F-RLX
ミニタワー型ながら、強力なファンでしっかり排熱。
デスク周りをスッキリさせたいクリエイターに向けた製品です。
16GBのVRAMを活かした動画編集に最適です。
4. TSUKUMO G-GEAR GA7J-C265
パーツの品質に定評のあるツクモのモデル。
電源にGold(※23)認証の高品質なものを採用しています。
将来的なアップグレードも視野に入れられます。
5. HP OMEN 35L Desktop
独自の冷却システムと、見た目の美しさを両立。
プロフェッショナルな現場にも馴染むデザインで、安定したパフォーマンスを提供します。
- ※22 BTO:受注生産方式。自分の希望に合わせてパーツをカスタマイズして購入できる。
- ※23 Gold認証:電源ユニットの電力変換効率が高いことを示す証。電気代の節約や安定性に寄与する。
RTX 5070 Stable Diffusion活用術と設定
要点:RTX 5070の性能を100%引き出すためには、TensorRTの適用と最新のドライバ管理が不可欠です。
1. VRAM 16GBを活かした高解像度生成戦略
前世代の12GBから16GBへと増量されたVRAMは、生成AIにおいて決定的な差を生みます。
RTX 5070では、これまで4090などのハイエンド機でしか快適に扱えなかったFlux.1(※32)やSDXLの大規模なモデルを、余裕を持ってロード(読み込み)できます。
具体的な活用術として、1024×1024ピクセル以上の高解像度生成においても、Hires.fix(※46)を2倍以上に設定して実行することが可能です。
gddr7メモリの高速化により、タイル(分割)処理を行わずに一気に書き出せる。
画像の破綻が少なく、高品質な作品を短時間で量産できるのが大きな魅力です。
2. Blackwell専用TensorRTエンジンの構築
nvidiaが提供するTensorRT(※24)は、RTX 5070の第5世代Tensorコア(※6)に最適化された設定を行うことで真価を発揮します。
2026年のStable Diffusion(Forgeやreforge版(※47))では、Blackwell専用のfp4演算プロファイルが利用可能です。
この設定を適用すれば、従来のfp16(※35)に比べて、生成速度をさらに約30%以上向上させることができます。
1秒あたり20枚(※1.5基準)を超えるような圧倒的なパフォーマンスをミドルレンジのグラボで実現できるのは、この5070の独壇場です。
プロンプト(呪文)の試行錯誤を高速に回したいクリエイターにとって、この時間短縮は売上に直結するポイントとなります。
3. LoRA学習とマルチタスクの両立
RTX 5070の16GBメモリは、生成だけでなく学習においても優秀です。
自分専用のイラストや実写のモデルを作るLoRA(※10)学習において、バッチサイズ(※25)を4以上に上げても安定して動作します。
また、gpuの処理効率が高くなりました。
裏側でaiの学習を回しながら、
- 表で別のaiエージェントを動かしたい。
- ゲーミングを楽しみたい。
こんなマルチタスクも現実的になりました。
現在のbto pcでおすすめされる128gbメモリ(メインメモリ)と組み合わせることで、pc全体が最強のaiスタジオへと進化します。
4. エラー回避とメンテナンスの注意点
高性能なRTX 5070でも、ドライバの更新や冷却管理は重要です。
特にBlackwellは瞬間的な電力負荷が大きくなる傾向があるため、電源ユニットは750w gold(※23)以上を推奨します。
もし動作が不安定になった際は、xformers(※12)のバージョンを最新に保ちましょう。
cuda toolkit(※48)の整合性を確認しましょう。
日々登場する最新の拡張機能に対しても、16GBのvramがあれば将来的にも安心してアップデートを続けられます。
Stable Diffusionを快適に動かすコツは、NVIDIAが提供するTensorRT(※24)の導入です。
これを適用すれば、画像生成速度が通常の2倍近くまで高速化される事例も多くあります。
設定の流れ:
- NVIDIA公式サイトから最新ドライバをダウンロード。
- SD WebUIにTensorRT拡張をインストール。
- 512×512や1024×1024など、用途に合わせたエンジンの作成。 これらの調整を行うことで、RTX 5070はハイエンド機に負けない爆速の生成マシンへと進化します。失敗しないためのポイントは、VRAM使用量を常にタスクマネージャーで確認し、バッチサイズ(※25)を適切に設定することです。
- ※24 TensorRT:特定のGPUに合わせてAIの計算手順を最適化し、速度を爆速にする技術。
- ※25 バッチサイズ:一度にまとめて処理するデータの量。
- ※46 Hires.fix:低い解像度で生成した画像を、細部を書き込みながら高解像度化する機能。
- ※47 Forge / reforge:Stable Diffusionをより高速・軽量に動かせるように改造されたソフトウェア。
- ※48 CUDA Toolkit:GPUを使って高度な計算をするために必要な開発用ツールセット。
よくある質問と回答 (FAQ)
要点:購入前に感じやすい疑問をクリアにし、納得のいく投資をサポートします。
Q1. RTX 4070 SuperとRTX 5070、どっちを買うべき?
A1. 予算が許すならRTX 5070です。
VRAMが16GBに増えたことで、将来登場するより巨大なAIモデルにも対応できるため、3年先を見据えた将来性で勝ります。
Q2. 既存の750W電源でも動きますか?
A2. はい、RTX 5070の消費電力は効率化されているため、品質の良い750W電源であれば問題なく動作します。
ただし、12VHPWR(※26)ケーブルの接続だけは確実に行ってください。
Q3. AI開発以外にゲームでもメリットはありますか?
A3. もちろんあります。
DLSS 4の恩恵で、モンスターハンターワイルズなどの最新タイトルも4Kで滑らかにプレイ可能です。
144Hz以上のゲーミングモニターを活かした高速描写も得意です。
- ※26 12VHPWR:最新グラボ用の補助電源規格。しっかり奥まで挿さないと熱を持つことがあるため注意。
まとめ:RTX 5070が切り拓く次世代のAIライフ
要点:RTX 5070の導入は、単なるpcのアップグレードではありません。
生成AIや最新ゲームにおける圧倒的な体験と時間のゆとりを自分に提供するための、2026年で最も価値のある投資と言えます。

本記事で詳しく解説した通り、GeForce RTX 5070はBlackwellアーキテクチャの恩恵を最大限に受け、ミドルレンジながら16GBのVRAMを搭載するという、かつてないスペックを実現しました。
NVIDIAの最新技術であるDLSS 4やTensorRTを活用すれば、4Kでのゲームプレイも、Stable Diffusionでの高速画像生成も、すべてが快適なものへと更新されます。
今後、AIの技術はさらに高度化し、要求されるハードウェアの水準も上がっていくでしょう。
しかし、RTX 5070という強力な基盤があれば、将来的な変化にも柔軟に対応し、常に最前線で制作や遊びを楽しむことが可能です。
迷っている方は、今このタイミングで最新世代のパワーを手に入れ、新しい時代の一歩を踏み出してみませんか。
内部リンクのご案内
RTX 5070の性能をさらに深掘りし、あなたのPC環境を最適化するための関連記事をあわせてご覧ください。
[AI PCに64GBメモリが必要な理由] 最強のGPUを活かすためには足回りも重要。メモリ不足でGPUの足を引っ張らないためのガイドです。