
要点:2026年のローカルLLMは、クラウド不要でGPT-4クラスの推論を可能にしました。
プライバシーとコストの両面で圧倒的なメリットを提供します。
AI技術の進化は止まることを知らず、2026年現在、多くの開発者や企業がクラウドサービスへの依存を減らします。
ローカル環境でのAI生成を模索しています。
かつては膨大な計算リソースが必要だった大規模言語モデルも、今では一般的なPCスペックで十分に動作するよう整理されました。
本記事では、エンジニアや研究者が今すぐ導入すべきローカルLLMのおすすめモデルを厳選しました。
- 具体的なインストール方法
- RAG(検索拡張生成)の活用事例
まで徹底的に解説します。
外部へのデータ流出を気にせず、自分だけの高度なAI基盤を構築する第一歩をここから始めましょう。

ローカルLLM比較と選び方の基本
要点:モデル選びの成功は、
- VRAM容量
- 量子化ビット数
そして「MoE」などの最新アーキテクチャへの理解を基にした最適なスペック配分にあります。
2026年のローカルLLMシーンにおいて、モデル選びはかつての「パラメータ数至上主義」から、より効率的で実用的な「アーキテクチャ重視」へと進化しました。
自身のPC環境で最大限のパフォーマンスを引き出すための比較基準を整理して解説します。
VRAM容量とパラメータ数の黄金比
推論速度(トークン/秒)を維持するためには、モデルの全データをGPUのビデオメモリ(VRAM)に乗せきることが大前提となります。
2026年現在の主流スペックに基づく目安は以下の通りです。
- 12GB〜16GB(ミドルクラス): 8Bから14Bクラスのモデルが最適です。4bit量子化(Q4_K_Mなど)を施すことで、文脈維持に必要なコンテキスト領域も十分に確保できます。
- 24GB(ハイエンド:RTX 3090/4090): 30Bクラス、またはMoE(Mixture of Experts)アーキテクチャを採用した35Bクラスのモデルを高速に動作させることが可能です。
- 32GB〜48GB(超ハイエンド:RTX 5090単体またはマルチGPU): 70Bクラスの巨大モデルや、推論に特化した「リーズニングモデル」を実用レベルで実行できる、エンジニアにとっての理想的な環境です。
量子化形式(GGUF / EXL2)の選択
同じモデルでも、どのような技術で圧縮(量子化)されているかによって、動作の軽快さが変わります。
- GGUF: llama.cppで採用されている最も汎用的な形式です。VRAMが不足してもCPU(メインメモリ)に処理を逃がせるため、導入時の安定性が極めて高いのが特徴です。
- EXL2 / AWQ: GPU性能をフルに発揮させることに特化した形式です。特にEXL2は、VRAM容量に合わせてビット数を細かく調整できるため、限界まで精度を高めたいエンジニアリングの現場で多用されています。
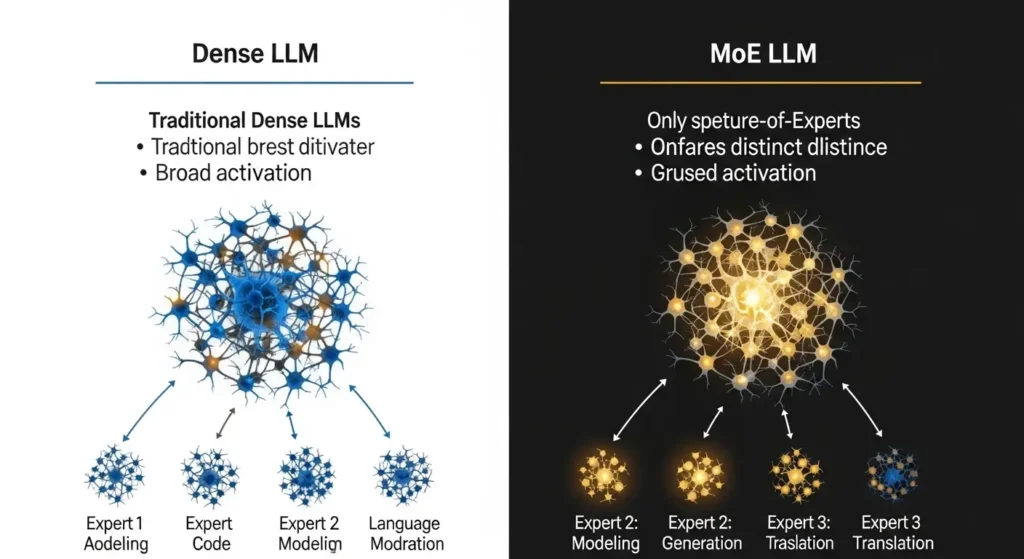
MoE(混合専門家)アーキテクチャのメリット
2026年のトレンドとして、全てのパラメータを常に動かすのではありません。
入力に応じて必要な部分(エキスパート)だけを起動する「MoE」モデルが普及しています。
これにより、例えば「35Bクラスの知能を持ちながら、推論時は8Bクラスの軽さで動く」といった効率的な運用が可能になります。
推論速度のベンチマーク指標
導入後に「使いやすい」と感じるための具体的な数値目標を基に評価しましょう。
- 10 token/s: 読むスピードとほぼ同じ。最低限の実用レベル。
- 30 token/s: 非常に快適。ストレスなく対話が可能。
- 60 token/s以上: 瞬時に回答が表示される。RAGなどの複雑な処理を挟んでも余裕がある。
注釈:MoE(Mixture of Experts) 複数の小規模なネットワーク(専門家)を組み合わせ、タスクに応じて最適なネットワークだけを選択して使用する手法。計算コストを抑えつつ高い性能を実現します。
おすすめローカルLLMモデル紹介
要点:2026年のおすすめモデルは、
- 日本語能力に長けた「Qwen」
- コーディングと推論の王者「DeepSeek」
そして盤石な汎用性を誇る「Llama」の3強時代に突入しています。
2026年現在、ローカルLLMの選択肢は「軽量かつ高知能」なモデルの爆発的普及により、実務レベルでの運用が当たり前となりました。
用途やPCスペックに合わせて選ぶべき、最新のおすすめモデルを詳しく紹介します。
日本語対応と多言語能力の最高峰:Qwen 2.5 / 3.0
Alibaba Cloudが開発したQwenシリーズは、2026年のローカルLLMシーンにおいて、日本語の自然さで圧倒的な支持を得ています。
- 特徴: 119言語に対応し、特に日本語の敬語表現や文脈理解が極めて正確です。Nejumi LLM Leaderboard等のベンチマークでも、商用モデル(GPT-4クラス)に匹敵するスコアを記録しています。
- おすすめの層: ビジネスメールの自動作成、社内ドキュメントの要約、日本の文化的背景を考慮した対話システムを構築したいエンジニア。
- 推奨サイズ: 7Bまたは14B(VRAM 12GB〜16GBで快適に動作)。
コーディングと論理推論の革命児:DeepSeek-V3 / R1
中国発のDeepSeekは、2025年から2026年にかけて「最もコストパフォーマンスに優れた知能」として世界中に衝撃を与えました。
- 特徴: 特にPythonやTypeScriptなどのプログラミング能力が非常に高く、GitHub Copilotと遜色ないレベルのコード生成が可能です。推論特化型の「R1」シリーズは、数学的課題や論理パズルにおいて、自己反省(Thinking)プロセスを経て正解を導き出す能力を持っています。
- おすすめの層: ローカル環境でセキュアに開発支援を受けたいエンジニア、複雑なロジック設計を行うデータサイエンティスト。
世界標準の汎用性と安定性:Llama 3.3 / 3.4
Metaが提供するLlamaシリーズは、ローカルLLMのエコシステムにおいて「OS」のような立ち位置を確立しています。
- 特徴: どのようなプロンプトに対しても安定した回答を返し、指示に従う能力(Instruction Following)が極めて高いのが強みです。世界中の開発者がLlamaを基準にツールを作成しているため、トラブル時の解決策が見つかりやすいという安心感があります。
- おすすめの層: 初めてローカルLLMを導入する方、特定のツール(GPT4Allやollama)で確実に動作させたい方。
軽量・省電力エッジデバイス向け:Phi-4
Microsoftが開発したPhiシリーズは、5B〜14Bという小規模なパラメータ数ながら、70Bクラスの大型モデルに匹敵する知能を実現しています。
- 特徴: スパースアテンション機構により、計算効率が従来より50%向上しています。128,000トークンの長文脈処理にも対応しており、マニュアルの全文読み込みなどに適しています。
- おすすめの層: MacBookのM1/M2チップや、メモリの限られたノートPCで高度なAIを動かしたい個人開発者。

モデルスペック比較早見表(2026年版)
| モデル名 | 得意分野 | 推奨VRAM | 日本語精度 | 特徴 |
| Qwen 2.5-14B | 日本語・多言語 | 12GB | 極めて高い | 実務メールや文書作成に最適 |
| DeepSeek-R1 | 推論・コード | 16GB〜 | 高い | 思考プロセスを出力する推論特化型 |
| Llama 3.3-8B | 汎用・安定性 | 8GB | 標準的 | ツール連携やRAGのベースに最適 |
| Phi-4-14B | 軽量・教育 | 10GB | 良好 | 小型ながら数学・論理に強い |
注釈:GGUF形式
llama.cppなどで使われるモデルファイル形式。
単一のファイルにモデルデータがまとめられております。
量子化ビット数(圧縮率)の選択肢が豊富なため、ローカル環境での標準となっています。

ローカルLLMインストールの全手順
要点:2026年のインストール手順は、複雑なビルド作業が不要な「Ollama」や「LM Studio」の台頭により、初心者でも最短3分で完了するほど簡略化されました。
ローカルLLMを自分のPCで動かすための具体的な導入手順を解説します。
かつてはPython環境の構築や依存ライブラリの解決に数時間を要していました。
現在はパッケージ化されたツールを利用するのが最も賢い選択です。
Ollama:コマンド一つで即戦力
Ollamaは、2026年現在で最も普及しているローカルLLM実行エンジンです。
軽量でありながら、APIサーバーとしても機能するため、他のアプリケーションとの連携も容易です。
- インストール: 公式サイト(https://ollama.com/)から各OS用のインストーラーをダウンロードし、実行するだけです。
- モデルの取得: ターミナル(またはコマンドプロンプト)を開き、
ollama run llama3.3やollama run qwen2.5と入力すれば、モデルのダウンロードと対話が自動的に開始されます。 - 日本語モデルの利用: Llama 3やGemma 2、Qwen 2.5などの日本語対応が進んだ最新(最新)モデルを指定することで、即座に高精度な回答を得られます。
LM Studio:視覚的なGUIでモデル管理
コマンド操作が苦手な方や、複数の量子化モデルを比較(比較)したいエンジニアにはLM Studioがおすすめです。
- 導入手順: 公式サイトからアプリをダウンロードし、起動します。
- 検索とダウンロード: 画面内の検索バーに「Gemma 2」や「Llama 4」などのキーワードを入力すると、Hugging Face上のモデルが一覧表示されます。
- スペック確認: 自分のPCのVRAM容量に合わせて、動作可能(可能)な量子化サイズ(Q4_K_Mなど)をAIが自動で判定してくれるため、導入(導入)の失敗を防げます。
llama.cppとText generation web UI
より高度(高度)なカスタマイズやエンジニアリングを楽しみたい中上級者向けの選択肢です。
- llama.cpp: C++で書かれた推論エンジンの本体です。ビルドが必要ですが、最新のハードウェア機能を極限まで引き出すことができます。
- Oobabooga (Text generation web UI): ブラウザ上で動作する多機能なインターフェースです。LoRA(ローラ)による追加学習や、プロンプトの細かなテンプレート管理、拡張機能の追加(追加)が可能です。
動作(動作)確認と初期設定のポイント
インストールが完了したら、必ず以下の項目を確認しましょう。
- GPUオフロードの設定: モデルのレイヤーをどれだけGPU(VRAM)に割り当てるか調整します。これを忘れるとCPU処理になり、応答速度が極端に低下します。
- システムプロンプトの設定: AIに「あなたは優秀なエンジニアです。日本語で回答してください」といった指示を事前(事前)に与えておくことで、回答の質を安定させます。
注釈:量子化(Quantization) モデルのデータ精度を落としてファイルサイズを小さくする技術。
4bit量子化などが一般的で、メモリ消費を大幅に抑えつつ性能低下を最小限に留めます。
RAG活用でAIの知識を外部拡張する
要点:2026年のRAGは、単純な検索から意味の構造化へと進化しております。
ローカルLLMに最新の専門知識を安全かつ正確に同期させるための最強の武器です。
どれほど優れた大規模言語モデルでも、トレーニングが終了した後の最新ニュースや、あなただけが持つ機密情報については答えられません。
これを解決し、AIの知能を特定の業務に最適化させる技術がRAG(Retrieval-Augmented Generation / 検索拡張生成)です。
2026年最新のRAGプロセスと構成
RAGは、質問に関連する情報を外部のデータベースから検索し、その結果をプロンプトに付け加えてAIに渡す仕組みです。
2026年現在、ローカル環境での構築には以下の構成がおすすめです。
- 埋め込みモデル: テキストを数値化するモデルです。2026年には、名古屋大学のruri-v3などの日本語特化型がローカルでも非常に高い精度を発揮し、検索のヒット率を劇的に向上させています。
- ベクトルデータベース: 検索可能な状態で情報を登録する場所です。ChromaやQdrantを使えば、数万件のドキュメントからミリ秒単位で関連箇所を抽出できます。
ローカルRAGがもたらす圧倒的な信頼性
クラウド型AIとの最大の違いは、情報の鮮度と安全性です。
- 情報のアップデートが容易: LLM本体を再学習させるには膨大なコストがかかりますが、RAGなら新しいPDFやテキストをデータベースに追加するだけで、即座にAIの回答内容を更新できます。
- ハルシネーションの抑制: AIは提示された資料に基づいて答えてくださいという指示に従うため、知らないことを知ったかぶりして答える嘘を大幅に減らすことが可能です。

GraphRAGと長文脈処理の使い分け
2026年のトレンドとして、単なるベクトル検索だけでなく、情報のつながりをグラフ化して検索するGraphRAGが登場しています。
- GraphRAGの強み: このプロジェクトの全体像は?といった、複数の文書にまたがる複雑な質問に対しても、情報の相関関係を理解して要約できます。
- 長文脈モデルとの併用: 最近のLlama 3.3やPhi-4は、一度に読み込める文字数が飛躍的に増えています。短いマニュアルならRAGを使わずとも、プロンプトに丸ごと流し込むだけで正確な回答が得られるケースも増えています。
注釈:Embedding(埋め込み) 文章の意味を多次元のベクトル(数値の羅列)に変換すること。
これにより、AIは言葉の表面的な一致ではなく意味の近さで情報を探せるようになります。
ローカル環境でのAI構築において、最終的な目標は自分たちにしか出せない価値を作ることです。
これらを実現するために必要な、より高度なアプローチと具体的な知識を整理します。
ファインチューニングとRAGの使い分け
AIの回答精度を高めるための手法として、ファインチューニングとRAGはそれぞれ異なります。
- ファインチューニング: 特定の業界用語や独自の文体をモデルに深く学習させ、AIの基礎体力を底上げするアプローチです。機械学習の知識が必要ですが、タスクに対する応答の向上に大きな効果を発揮します。
- RAGの優位性: リアルタイムにデータソースへアクセスし、最新の製品情報を参照できるため、情報の正確性と信頼性が期待できます。2026年現在は、LangChainなどのフレームワークを用いて、これらを統合する運用が主流です。
独自データの統合と品質管理
ビジネスの状況において、AIを実際レベルに引き上げるためには、データの整理が不可欠です。
- 高品質なデータソース: 社内ブログやマニュアル、過去の質問回答集など、元となる情報の品質がそのままAIの力に直結します。不要な情報が含まれないよう注意し、関連性の高い内容だけを抽出することが重要です。
- 検索の最適化: ユーザーが知っている言葉で検索しやすくするために、メタデータを付与するなどの工夫が次のステップとなります。
世界と繋がるオープンソースの力
2026年現在、Hugging Faceなどのプラットフォームを通じて、世界中の開発者が済みのモデルやガイドを無料で公開しています。
- 主要モデルの活用: LlamaやGemmaといった主要なモデルをベースに、特定の固有タスク向けに調整されたLoRAなどの軽量な変更ファイルを適用するだけで、驚くほど簡単に高性能な環境を構築できます。
- シンプルかつ強力: 以前の複雑なプロセスとは異なり、今ではブラウザ上での操作やシンプルなコードだけで、全体の仕組みを構築することが可能です。
注釈:Chain LangChainなどで呼ばれる概念で、複数のAI処理やツールを鎖(chain)のようにつなぎ、一つの複雑なタスクを完了させる仕組みのことです。
プロンプトエンジニアリングの極意
要点:ローカルLLMの性能を限界まで引き出すには、明確な構造を持ったプロンプトと、2026年の最新手法である「思考プロセス(Reasoning)」の制御技術が不可欠です。
同じモデルを使っていても、与える指示一つで回答の質は大きく変わります。
2026年現在のプロンプトエンジニアリングは、単なる「文章の工夫」から、AIの思考回路を設計する「エンジニアリング」へと進化しました。
思考特化型モデル(DeepSeek-R1等)の制御
2026年のトレンドであるDeepSeek-R1やLlama-3.3の蒸留モデルは、回答前に自ら思考する「Reasoning」機能を備えています。
- 思考タグの活用: これらのモデルは
<think>タグ内で論理を組み立てます。プロンプトで「まず思考プロセスを詳細に書き出し、その後に結論を述べてください」と明示することで、複雑な数式やコード生成の正答率が飛躍的に向上します。 - 冗長性の回避: 内部で思考ステップを持つ「推論モデル」に対し、従来の「ステップバイステップで考えて」という指示は2026年時点では冗長となるケースもあります。モデルの特性に合わせ、結果の正確性やフォーマットの遵守にリソースを割かせる指示が重要です。
コンテキスト・エンジニアリングの実践
優れたプロンプトは、AIに与える「背景情報(コンテキスト)」の質で決まります。
- Few-shotプロンプティング: AIにゼロから説明するのではなく、2〜3個の具体的な「入力と出力の例」をプロンプトに含めます。これにより、出力のトーンやフォーマット(JSON形式など)を100%制御することが可能になります。
- 役割の定義(Role Prompting): 「あなたはシニアソフトウェアエンジニアです」「あなたは法務の専門家です」といった役割付与は、使用する専門用語や回答の視点を固定するために現在も非常に有効な手法です。

生成AIの出力を安定させる構造化指示
大規模言語モデルが業務システムの一部として機能するためには、出力の「型」を安定させることが必須です。
- デリミタ(区切り文字)の使用:
### 指示 ###や--- コンテキスト ---のように、情報の種類を記号で区切ることで、AIはどこが命令でどこが参照データかを正確に理解します。 - ネガティブプロンプト: 「〜については言及しないでください」「推測を含めず、事実のみを述べてください」といった禁止事項を設けることで、回答のブレ(ハルシネーション)を抑制し、的確な出力を得られます。
注釈:Few-shotプロンプティング AIに少数の例示を与えることで、新しいタスクや特定のフォーマットを即座に学習させる手法。
2026年のローカルLLM運用においても、最も確実な精度向上策の一つです。

ローカルLLM導入に必要なスペック
要点:2026年の推奨環境は、最低でも12GB以上のVRAMを搭載したGPUです。
これが快適な推論を支える基盤となります。
モデルを動かす前に、自分のPCスペックが要件を満たしているか整理しましょう。
2026年現在は、RTX 50シリーズの登場やApple M4チップの普及により、ローカルLLM実行のハードルは劇的に変化しています。
GPUとVRAM:推論の生命線
LLMの推論において最も重要なのはGPUのメモリ(VRAM)容量です。
モデルの重みと会話の文脈(KVキャッシュ)をすべてVRAMに収めることが、高速なレスポンスを得る絶対条件です。
- エントリー(8Bクラス): RTX 3060 (12GB) / RTX 4060 Ti (16GB) Llama 3.3やGemma 2の軽量版を4bit量子化で動かすのに最適です。
- ミドル(14B〜32Bクラス): RTX 4070 Ti Super (16GB) / RTX 5080 (16GB) Qwen 2.5の14BモデルやDeepSeek-R1の蒸留版をフルスピード(40〜60 token/s)で実行可能です。
- ハイエンド(70B〜クラス): RTX 4090 (24GB) / RTX 5090 (32GB) 32GBのVRAMを持つRTX 5090であれば、70Bクラスの巨大モデルを量子化して1枚のカードで実用的な速度(15〜20 token/s)で動かせます。
Apple Silicon(Mac)という選択肢
Macユーザーの場合、CPUとGPUが同じメモリを共有する「ユニファイドメモリ」が最大の武器になります。
- M3 / M4 Max (128GB以上): Windows機では数十万円のマルチGPU構成が必要な70B〜400Bクラスの超巨大モデルも、1台のMac Studio等で(速度は控えめながら)動作させることが可能です。
- メモリ帯域の重要性: M4 Pro/Maxはメモリ帯域幅が大幅に向上しており、2026年時点では「省電力で静かなAIワークステーション」としてエンジニアに選ばれています。
CPUとシステムRAMの補完役割
GPUのVRAMが不足していても、システムメモリ(RAM)が十分にあれば「共有GPUメモリ」として利用できますが、速度はVRAM直接処理の10分の1以下に低下します。
- 最低16GB、推奨32GB以上: モデルを実行しながらブラウザや開発ツールを動かすには、32GB以上のシステムRAMが2026年の標準です。
- SSDの速度: 数GB〜数十GBあるモデルファイルを一瞬で読み込むため、NVMe Gen4/Gen5対応の高速ストレージが推奨されます。
注釈:KVキャッシュ 会話の文脈を一時的に保存しておくメモリ領域。
長い文章を読み込ませる(コンテキストを増やす)ほど、モデル本体とは別に多くのVRAMを消費します。

オフラインLLMのセキュリティメリット
要点:情報を完全に内部に留めるオフライン運用は、機密情報を扱う企業や個人にとって、クラウドAIにはない唯一無二の価値です。
なぜ、手間をかけてまでローカル環境を構築するのでしょうか。その最大の答えはセキュリティにあります。
機密データの漏洩リスクをゼロに
クラウドAIを利用する際、入力したデータがモデルの再トレーニングに使用される可能性は常に否定できません。
社外秘のプロジェクト資料や個人情報を入力することは、大きなリスクを伴います。
完全にオフラインで動作するローカルLLMであれば、物理的に情報が外部へ漏れることはありません。
ランニングコストの削減と自由度
APIの利用料金を気にせず、大量の文章を処理させることができるのも大きな魅力です。
一度環境を構築してしまえば、電気代以外の追加コストは発生しません。
また、フィルター(検閲)に縛られず、自由な表現や特定の業界用語を多用したカスタマイズも自由自在です。

2026年の最新AIエージェントトレンド
要点:次世代のローカルLLMは、自律的にツールを使いこなし、ユーザーの指示を待たずに問題を解決する「エージェント型」へとシフトしています。
今、AI界隈で最も熱いトピックがAIエージェントです。
自律的なタスク遂行能力
2026年のAIエージェントは、ブラウザを操作して最新のニュースを収集したり、ローカルのファイルを分析して報告書を作成したりする能力を持っています。
これまで人間が手動で行っていた「検索→理解→作業」のプロセスを、LLMが司令塔となって自動化します。
ツール接続(Tool Use)の進化
最新のモデル(Qwen 2.5やLlama 3.x)は、Pythonコードを生成して実行したり、外部APIと接続したりする「Tool Use(関数の呼び出し)」機能が強化されています。
これにより、ローカルLLMは単なる相談役から、実務をこなす実質的な「部下」へと進化を遂げています。

専門家が教えるLLM推論の最適化
要点:コンテキストウィンドウの管理とキャッシュ技術の利用により、長文の入力に対しても高速で正確な応答を得ることが可能です。
システムを構築した後、さらに快適に使うための高度な調整方法について紹介します。
コンテキストウィンドウの拡大と管理
一度に扱える情報の長さ(コンテキスト)は、モデルごとに限界があります。
2026年のモデルは128kトークン以上を扱えるものも多いですが、長くなるほど推論の時間は増え、精度は低下する傾向があります。
必要な情報だけを適切に整理して与える戦略が必要です。
KVキャッシュと推論の高速化
KVキャッシュという技術を利用すると、以前の会話の文脈を再利用することで、2回目以降の応答時間を大幅に短縮できます。
これは、大規模なドキュメントをベースにした対話システムでは必須の機能です。
初心者が陥りやすい問題と解決策
要点:動作しない原因の多くはドライバーのバージョンやパスの設定ミスにあります。
これらを一つずつ検証することで解決が得られます。
初めて導入する際、うまく動かないことは珍しくありません。
CUDAエラーとライブラリの不整合
NVIDIA製GPUを使っている場合、CUDAツールキットのバージョンが古いとエラーが出ることが多いです。
常に最新のドライバーをインストールしましょう。
環境変数(Path)が正しく設定されているか確認しましょう。
モデルのダウンロード失敗と破損
Hugging Faceからモデルをダウンロード(取得)する際、インターネット回線の瞬断でファイルが壊れることがあります。
SHA256ハッシュ値を確認し、ファイルが正常であることを確かめてから読み込ませることが大切です。

ローカルLLMに関するよくある質問
要点:疑問を解消し、安心して導入を進めるためのQ&Aをまとめました。
Q:ローカルLLMはスマホでも動かせますか?
A:はい、可能です。
2026年現在は、AndroidやiOS向けに最適化された軽量モデル(Phi-4 MiniやGemma 2Bなど)が存在します。
専用のアプリケーション(例:MLC LLM)を使えばオフラインでの実行が可能です。
Q:クラウドAIと比べて賢さはどうですか?
A:最新の100Bを超えるクラウドモデルに比べれば、小さなローカルモデルは知識量で劣ります。
しかし、RAGを活用して「特定の知識」を与えることで、特定の業務領域ではクラウドAIと同等以上の精度を発揮します。
Q:電気代はどのくらいかかりますか?
A:ハイエンドGPUをフル回転させると、1時間あたり数十円程度の電力を消費します。
しかし、推論(回答出力)時以外はアイドリング状態になるため、常時稼働させても一般家庭の電気代に占める割合はそれほど大きくありません。

まとめ:自分だけのAI環境を手に入れよう
要点:ローカルLLMの構築は、未来の働き方を変えるための自己投資であり、今始めることが大きな競争優位性を生みます。
本記事では、
- 2026年最新のローカルLLMおすすめモデル
- 導入手順
- RAG活用
そしてスペック選びまでを徹底的に解説しました。
技術的なハードルはかつてないほど低くなっております。
誰でも今すぐ自分専用のAIを手に入れることができます。
プライバシーを守り、コストを抑え、そして自分の好みに合わせてカスタマイズできるローカル環境は、一度体験するとクラウドサービスには戻れないほどの魅力があります。
まずは小さなモデルから試し、AIと共に進化する新しい体験を楽しんでください。
