
- 「ChatGPTは知っているけど、他にもどんなLLMの種類があるの?」
- 「うちの会社やプロジェクトには、どのモデルが最適なんだろう?」
今、生成AIの中核技術であるLLM(大規模言語モデル)は、日進月歩で進化し続けています。
OpenAIのGPTシリーズだけではありません。
- GoogleのGemini
- AnthropicのClaude
- MetaのLlama
など、世界中の巨大テック企業やスタートアップから、高性能な言語モデルが次々と発表されています。
LLMの進化は、私たちのビジネスや日常生活に革新的な変化をもたらす、まさに技術の大きな転換期といえます。
しかし、
- モデルの種類の多さ
- 性能の違い
- 価格体系
さらには商用利用の可否など、その情報量の多さから「結局どれを選べばいいのか分からない」と感じてしまうこともあるのではないでしょうか。
ご安心ください。
今回の記事は、まさにその課題を解決するために作成されました。
2025年の最新トレンドを網羅しました。
- LLMの種類
- 仕組み
- 性能の違い
そして用途に応じた最適な選び方までを、AI初心者の方でもスムーズに理解できるよう、知識と解決策を網羅的に解説します。
この記事を最後まで読むことで、あなたは
- AIエンジニア
- データサイエンティスト
- 企業のITコンサルタント
など、どの立場であっても、自信を持ってLLMを選定できるはずです。
活用していくための確かな知識を身につけられるでしょう。
私たちが目指すのは、単なる情報の羅列ではありません。
質の高い完璧なコンテンツを提供することで、あなたのAI活用の成功を強力にサポートします。
さあ、最新のLLMの世界へ、一緒に深く潜り込んでいきましょう。
LLMの基本的な仕組みと進化の歴史
大規模言語モデル(LLM)の基本的な定義
LLMは、大量のテキストデータを学習します。
人間のように自然な文章の生成や言語の理解を行う人工知能モデルの総称です。
この技術は、ディープラーニング(深層学習)の一種であるトランスフォーマー(Transformer)アーキテクチャに基づいています。
LLMは、数十億から数兆個のパラメータ(係数)を持ちます。
このパラメーターの数が「大規模」という名前の由来となっています。
この大きな数こそが、モデルの持つ知識量と複雑な文脈を把握する能力に直結しています。
(注釈:パラメータ…LLMが学習によって調整する数値のことで、人間の脳でいうシナプスのような役割を果たします。この量が多いほど、より複雑な知識を学習し、より高度な処理が可能になります。)
トランスフォーマーの革新とLLMの夜明け
LLMが飛躍的な進化を遂げた最大の理由は、2017年にGoogleから発表された論文「Attention Is All You Need」で提案されたトランスフォーマーというアーキテクチャにあります。
トランスフォーマーは、文章の各単語間の関係性(コンテキスト)を効率的に計算する「アテンション機構」を採用しています。
従来のRNNやLSTMといったモデルと比べて、長文の理解や並列計算が大幅に向上しました。
これにより、巨大なモデルの学習が可能となりました。
GPTやBERTといった画期的な言語モデルが次々と登場しました。
LLMの種類を分ける3つの学習段階
LLMが驚異的な性能を発揮するまでには、主に3つの段階を経ています。
- 事前学習(Pre-training): 膨大なインターネット上のテキストデータセット(約数兆の単語)を用いて、単語の次に出現する単語を予測するタスクなどを通じて、言語の基本構造や世界の知識を学習します。
- インストラクション・チューニング(Instruction-Tuning): 事前学習を終えたモデルに対し、「要約して」「質問に回答して」といった具体的な指示(インストラクション)に応答できるよう、教師あり学習で微調整(ファインチューニング)を行います。
- 強化学習(RLHF/RLAIF): 人間からのフィードバックや、AI自身による評価(Constitutional AI)を用いて、より人間に好ましい、倫理的な回答を生成できるようにさらに調整を行います。このプロセスが、モデルの安全性や有用性を大きく向上させます。
主要な大規模言語モデルの種類と特徴
GPTシリーズ(OpenAI): 汎用性と圧倒的な性能
OpenAIが開発したGenerative Pre-trained Transformer(GPT)シリーズは、LLMブームを牽引する代表的な存在です。
- GPT-4o: 2025年最新のフラッグシップモデルの一つ。テキスト、音声、画像を統合的に処理するマルチモーダル機能と、高速な応答速度が特徴。特にリアルタイムでの対話や、マルチモーダルなタスクで高いパフォーマンスを発揮します。
- GPT-5: 2025年後半に発表が期待される次世代モデル。数学、金融、法律などの専門分野における知識や推論能力がさらに強化され、ハルシネーション(AIの誤情報生成)のリスクを最小限に抑えるよう設計されています。
- GPT-4.1シリーズ: 以前のGPT-4シリーズから、推論能力や長文の理解が大きく向上したバージョン。ビジネスの複雑な課題解決に適しています。(外部リンク1:OpenAI 公式サイト)
Geminiシリーズ(Google): マルチモーダルと検索連携
Googleが提供するGeminiシリーズは、Googleの強力な検索技術と統合されたマルチモーダルモデルです。
- Gemini 2.5 Pro: 大規模なコンテキストウィンドウ(最大数百万トークン)を持ち、長大な文書やデータセット全体を一度に処理し、深い分析や要約を行う能力に優れています。
- Gemini 2.5 Flash: 高速性とコスト効率に優れ、チャットボットやリアルタイム応答が必要なWebサービスでの活用が期待されます。特徴: テキストだけでなく、画像、音声、動画といった種類の異なるデータ形式を統合的に理解し、処理できる点が最大の強みです。また、Googleのサービスとの連携性が高く、最新情報へのアクセスも可能です。(外部リンク2:Google AI Studio 公式サイト)
Claudeシリーズ(Anthropic): 倫理と安全性を重視
Anthropic社が開発したClaudeシリーズは、「Constitutional AI(憲法AI)」という独自の安全基準に基づいてトレーニングされています。
有害なコンテンツや不適切な回答の生成を抑制する種類のモデルです。
- Claude 4 Opus/Sonnet: 複雑な推論タスクや、コーディング支援、長文の文脈把握で非常に高い種類の精度を示します。特に企業がAIを導入する際、倫理的リスクを最小限に抑えたい場合に適しています。特徴: 信頼性が求められる医療や金融といった業界や、長大な契約書などの文書分析において、高い性能を発揮する種類のモデルとして評価されています。(外部リンク3:Anthropic 公式サイト)
Llama/Mistral(オープンソース): 自由度とコミュニティの力
Metaが公開したLlamaシリーズや、フランスのMistral AIによるMistralシリーズは、モデルの重み(パラメータ)が一般に公開されているオープンソースの種類のLLMです。
- Llama 4 / Mistral Small 3.2: これらの種類のモデルは、商用利用も可能なライセンスで提供されており、自社のデータや要件に合わせてファインチューニングを行い、LLMをカスタマイズする自由度が高いのが最大の魅力です。特徴: 企業が自社環境(オンプレミスや特定のクラウド環境)でLLMを運用し、データの主権を保ちたい場合に、理想的な種類のLLMとなります。(外部リンク4:Hugging Face Hub 公式サイト)
LLMの性能評価:ベンチマークと実務適用性
ベンチマークスコアの重要性:客観的な性能種類の指標
LLMの種類を選ぶ際、どのモデルが最も優れているかを客観的に比較するために用いられるのがLLMベンチマークです。
ベンチマークは、モデルの種類ごとに、特定のタスク(例:知識、推論、コーディングなど)に対する性能を数値化したものです。
これにより、特定の種類のLLMがどの分野で強みを持っているかを把握できます。
(注釈:ベンチマーク…コンピューターやプログラムの性能を比較するための標準的なテストや評価種類のこと。LLMの場合は、知識や推論能力を測るテストが主に行われます。)
主要なベンチマークの種類と評価種類
| ベンチマーク名 | 評価種類のタスク | 測定されるLLMの種類の能力 |
| MMLU (Massive Multitask Language Understanding) | 大学レベルの多肢選択式知識テスト(57分野) | 汎用的な知識量、文脈理解、推論能力 |
| HumanEval | Pythonコードの自動生成とバグ修正タスク | プログラミング能力、論理的な解決能力 |
| GPQA (General Proficiency Question Answering) | 専門知識に基づく難易度の高い質問応答 | 高度な推論と専門知識の活用能力 |
| SWE-Bench | GitHub上の実際のソフトウェア開発のバグを修正するタスク | エージェント的なコーディングと問題解決能力 |
2025年最新のLLMベンチマーク動向とLLMの種類
2025年現在、LLMベンチマークは、従来の汎用知識だけではありません。
より実務的な能力(コーディング、エージェント機能、長文理解)を測る種類へと進化しています。
特にGPT-5やClaude 4 Opus、Gemini 2.5 Proといった最新の種類のモデルは、SWE-BenchやGPQAで高いスコアを示しています。
複雑な業務への応用種類の可能性を高めています。
LLMの導入戦略:商用利用、ライセンス、国産LLM
クローズドLLMの商用利用種類とAPI
OpenAIのGPTやGoogleのGemini、AnthropicのClaudeといった、企業が提供するLLMの種類は、クローズドモデル(非公開)と呼ばれています。
主にAPIを通じて利用します。
- ライセンス: サービスの利用規約に基づき、商用利用が可能です。
- メリット: 開発の手間が少なく、最新のモデル種類を利用でき、高性能です。
- 注意点: データのプライバシー(機密情報や個人情報の取扱い)とAPI料金(コスト)の管理が重要な課題です。
オープンソースLLMの商用利用種類と自由度
MetaのLlamaやMistralなどのオープンソースLLMの種類は、商用利用可能なライセンス(例:Apache 2.0、MIT)で公開される種類が増加しています。
- ライセンス: 提供元の利用条件を確認後、自由に商用利用、改変、再配布が可能な種類が多いです。
- メリット: 自社環境(オンプレミスなど)での運用により、データ漏洩のリスクを最小限に抑え、コストを抑えられます。
- 注意点: 自社で運用するための計算リソース(GPU)や専門知識が必要で、モデル自体の精度向上作業は自力で行う必要があります。
日本語LLMの種類と商用利用種類
日本語の文脈や文化的な背景をより適切に理解できる種類のLLMとして、
- rinna
- ELYZA
- OpenCALM
などの国産LLMが注目されています。
これらの種類のモデルは、日本語に特化したデータセットで学習されているため、日本企業のカスタマーサポートや社内文書の処理といったGEO対策が必要なタスクに適しています。
商用利用可否はモデルごとに異なるため、提供元の確認が必須です。
LLMの導入形態:APIとオープンソースの比較と選定
LLM API: 迅速な開発と高性能なLLM種類の利用
LLM APIとは、OpenAIやGoogleなどの提供元が管理する高性能なLLMを、インターネット経由でプログラムから利用するための窓口(API)です。
- メリット: 自前でサーバーや高性能GPUを用意する必要がなく、最新のモデル種類(GPT-5、Gemini 2.5 Proなど)を簡単に導入できます。開発効率が高く、迅速なプロトタイプ作成に向いています。
- デメリット: 利用量に応じた課金が発生し、機密情報や個人情報を外部サービスに渡すリスクがあります。(注釈:API…Application Programming Interfaceの略。ソフトウェアの機能やデータを、外部のプログラムから利用するための方法や窓口を定めたものです。LLM開発において不可欠な技術です。)
LLM オープンソース: カスタマイズ性とセキュリティの両立
LLMのオープンソース種類は、モデル全体の設計情報や重みが公開されているため、誰でも自由にダウンロードし、自社環境で実行したり、改変したりすることが可能です。
- メリット: コスト効率が高く、データ管理を自社で完結できるため、セキュリティが強化されます。企業固有のタスクに特化した種類のファインチューニングが自由に行えます。
- デメリット: 実行には高性能な計算リソース(NVIDIA GPUを搭載したワークステーションやクラウドサーバー)が必要です。モデル種類の選定や運用には専門知識が必須です。
LLMの種類と選び方:APIとオープンソースの分岐点
| 観点 | クローズドLLM API種類(例: GPT-5, Gemini) | オープンソースLLM種類(例: Llama 4, Mistral) |
| 開発速度 | 迅速 | 環境構築に時間を要する |
| 初期コスト | 低い(利用量次第) | 高い(GPUなどのハードウェア購入) |
| セキュリティ/データ主権 | 外部依存(利用規約に基づく) | 高い(自社内で完結) |
| カスタマイズ性 | 限られる(プロンプトやAPI機能内) | 高い(ファインチューニングが自由) |
| 推奨用途 | PoC/プロトタイプ、汎用的なタスク、最新技術の利用 | 機密情報を扱う社内システム、コスト最適化 |
LLMの種類別活用事例と業務効率化
LLM種類を活用した業務効率化の事例
LLMの種類は、企業の業務において、以下のように幅広い分野で活用されています。
- カスタマーサポート:ClaudeやGeminiなどの対話型LLMを搭載したチャットボットが、24時間365日、顧客の質問に回答し、オペレーターの負担を大幅に軽減し、顧客満足度の向上に貢献しています。
- コード生成/支援:GPT-5やCopilotなどのLLMの種類は、プログラミングコードの自動生成やバグの検出、修正を支援し、ソフトウェア開発の生産性を飛躍的に向上させています。
- 文書作成/要約:長文の会議議事録や契約書を短時間で要約したり、メールマガジンやブログ記事などのコンテンツ制作を支援したりする活用事例が多数あります。
LLM種類を活用した専門分野の事例
- 医療分野:LLMの種類は、大量の論文や患者データを分析し、診断支援や新薬開発のヒントを抽出する研究に応用されています。
- 金融分野:市場調査レポートの自動作成、契約書のレビュー、顧客の嗜好を予測するデータ分析に活用。
- 製造業:製品マニュアルの多言語翻訳、設計データの解析、故障予測の支援ツールとしてLLMの種類が導入されています。
マルチモーダルLLMの種類の活用(最新動向)
Gemini 2.5 ProやGPT-4oなどのマルチモーダルLLMの種類は、テキスト以外のデータ(画像、音声、動画)も理解します。
処理できます。
そのため、活用の幅が広がっています。
例:スマートフォンで撮影した製品の写真を入力。
「この部品の名前と使い方を教えて」と音声で質問すると、LLMが画像を認識します。
答えをテキストで回答する。(音声検索対策)

LLMの最新動向:エージェント化、軽量化、AIO/LLMO
LLMの種類の進化:エージェント化とツール利用
2025年、LLMの種類は、単に文章を生成するだけでなく、自律的にタスクを実行する「エージェント」へと進化しています。
- エージェント機能:LLMが「今日の株価を調べて、その結果をもとにレポートを作成して」といった複雑な指示を受け、検索エンジンや外部APIなどの「ツール」を利用し、複数の段階を経てタスクを完了させます。GPT-5やClaude 4 Opusなどの最新種類が優れています。
LLMの種類の多様化:小型/軽量モデルの台頭
最大規模なLLMの種類の高性能化が進む一方で、推論効率に優れ、PCやスマホ、IoT機器などのエッジ環境で実行できる小型/軽量LLMの種類(GPT-4o-mini、Gemini 2.5 Flash Lite、phi-4など)が続々と登場しています。
- メリット:応答速度が高速で、コストが低く、オフラインでの利用や、個人情報を外部に渡さないローカル処理が可能となります。
LLMの種類の安全性と信頼性の強化(AIO対策)
AIが誤った情報(ハルシネーション)を生成する課題に対し、LLMの種類は、学習プロセスの改善や、RAG(検索拡張生成)技術の統合によって、回答の事実性と信頼性の向上に取り組んでいます。
- RAG:外部の信頼できる知識ベースやデータソースを検索し、その結果をもとにLLMが回答を生成する手法。ハルシネーションのリスクを大幅に低減し、最新情報への対応も可能にします。(注釈:RAG…Retrieval-Augmented Generationの略。LLMが回答を生成する際に、外部のデータベースから関連情報を検索し、その情報を参照しながら答えを作成する技術です。)
LLM最新動向と未来予測
LLM最新動向:国産LLMの発展と特化分野
2025年、LLMの種類のグローバル競争が進む一方で、日本国内では、独自のLLMの開発が加速しています。(GEO対策)
- 特長:日本語のニュアンスや、日本の文化、慣習に基づく特有の表現の理解に優れています。
- 用途:法律、医療、金融など、高度な専門知識と精度が必要な分野に特化したLLMの種類が開発されています。
LLMの種類と未来:AIO/LLMOの重要性
今後、LLMの種類の基本的な性能の差が縮まるにつれ、重要になるのは、AI自身の振る舞いや、LLMの応答を最適化する技術、すなわちAIO(AI Optimization)/LLMO(Large Language Model Optimization)です。
- AIO/LLMO:単に「質問」を投げるだけでなく、LLMの思考プロセスをコントロールし、より論理的/段階的な推論を行わせる手法の研究が進んでいます。
LLMの種類とモバイル環境での利用(音声検索対策)
超軽量LLMの種類の登場により、今後は、スマホ(iPhone, Android)単体で、オフラインでもLLMを実行して、
- 音声対話
- リアルタイム翻訳
を行える種類のアプリの増加が期待されます。
この動向は、音声検索の利便性を飛躍的に向上させる鍵となるでしょう。
最適なLLM選び方と選定戦略(決定木チャート付き)
LLMの種類の選定:3つの基準
LLMの種類が多様化する中で、自社のニーズに合ったモデルを選ぶには、以下の3つの基準を総合的に評価する必要があります。
- 性能と精度(タスク適合性):ベンチマーク結果や、特定のタスク(コーディング、日本語の理解など)での実用テストを行い、要求水準を満たしているかを確認します。
- コストと速度(効率性):API利用料金(100万トークンあたりの価格)と、応答速度(レイテンシ)を比較し、予算とリアルタイム性の要件を満たしているかを確認します。
- セキュリティとライセンス(コンプライアンス):機密情報の取扱い、商用利用の可否、データプライバシーポリシーを徹底的に確認します。(特に個人情報を扱う場合)
LLMの種類を用途別に選ぶ具体的なアドバイス
| 用途 | 重視する点 | 推奨するLLMの種類 | 理由 |
| 汎用的な対話/質問応答 | 高い汎用性/知識量 | GPT-4o, Gemini 2.5 Pro | 総合性能が高く、様々な分野の質問に対応可能 |
| 長文の要約/文書分析 | 長いコンテキスト長 | Gemini 2.5 Pro, Claude 4 Opus | 一度に扱える情報量が多く、深い文脈を理解できる |
| 社内機密データ分析 | ローカル実行/セキュリティ | Llama 4/Mistral(オンプレミス) | データの外部流出リスクを回避できる |
| リアルタイムチャット/音声応答 | 低レイテンシ/高速推論 | GPT-4o-mini, Gemini 2.5 Flash | 応答速度が速く、ユーザー体験を損なわない |
マルチLLMアーキテクチャの導入
単一のLLMの種類に依存せず、
- タスクの種類
- 費用
- セキュリティ要件
に応じて、複数のLLMを使い分ける「マルチLLMアーキテクチャ」の設計が、2025年のトレンドです。
これにより、LLMの性能を最大限に最適化(LLMO)しましょう。
コスト効率を高めることが可能となります。
LLMのカスタマイズ技術:ファインチューニングとプロンプトエンジニアリング
LLMファインチューニングの定義と目的
LLMファインチューニングとは、事前学習を終えた汎用的なLLMの種類に対し、自社の業務データ(例:コールセンターの対話記録、専門用語集)を用いて、追加的な学習を行います。
特定のタスクへの適合性を高める手法です。
- 目的:汎用LLMの種類では得られない、特定分野での高い精度と、自社に特化した回答形式の実現。
LLMの種類の調整:フルファインチューニングとLoRA
LLMファインチューニングには、主に2種類の手法があります。
- フルファインチューニング:モデル全体のパラメータを更新する手法。高い性能向上が期待できるが、計算コストとリソースが膨大です。
- LoRA(Low-Rank Adaptation):モデル全体のごく一部のパラメータのみを調整する手法。低コスト、低計算リソースで効率的にチューニングが可能なため、オープンソースLLMの種類で広く採用されています。
プロンプトエンジニアリングの重要性
ファインチューニングを行わない場合でも、LLMの出力を最適化(LLMO)する最も重要な手法が「プロンプトエンジニアリング」です。
- 具体的な指示:曖昧な質問ではなく、「あなたは専門家です」「以下の形式で回答して」など、LLMに適切な役割と出力形式を与え、回答の精度と意図の一致性を向上させます。
LLM APIの最新進化とコスト最適化戦略
LLM APIの進化:マルチモーダルと高速化
2025年、LLM APIの種類は、単なるテキスト生成を超え、マルチモーダル(画像、音声の入力/出力)への対応と、応答速度の高速化が進んでいます。
- 高速LLM:Groqなどの特化型ハードウェアを利用したAPIサービスが、他の追随を許さない速度でLLMを実行しており、リアルタイム対話が必須の用途での採用が増えています。(外部リンク5:Groq 公式サイト)
LLM APIの料金体系とコスト最適化
LLM APIの料金は、入力トークンと出力トークンの量に応じて課金される「従量課金制」が主流です。
- トークン:LLMが情報を処理する最小単位(英語の単語、日本語の文字や単語の一部に近い)。
- コスト戦略:GPT-4o-miniやGemini 2.5 Flashなど、高性能かつ低コストな小型LLMの種類を適切に選択することが、全体の運用コストを削減する鍵です。また、プロンプトの短縮や、キャッシュの利用も有効です。
API Keyのセキュリティ管理とリスク回避
LLM APIを利用する際、API Keyの管理はセキュリティ上最も重要な課題です。
- 対策:API Keyをコード内に直接書き込むのは避け、必ず「環境変数」を利用し、公開リポジトリ(GitHubなど)への流出を防止します。課金上限を設定し、不正利用による予期せぬ高額請求のリスクを抑えましょう。
LLM商用利用の法的・倫理的リスク管理
LLM商用利用の法的リスク:著作権とハルシネーション
LLMの種類を商用利用する際には、以下の2つの主要な法的/倫理的なリスクを理解する必要があります。
- 著作権侵害:LLMが学習データに含まれる既存の著作物と類似した文章やコードを出力する可能性があり、著作権侵害のリスクを伴います。商用利用の際には、生成されたコンテンツの最終チェックが必須です。
- ハルシネーションと信頼性:LLMが誤った事実を、あたかも正確であるかのように自信満々に回答する「ハルシネーション」現象は、特に専門分野や、顧客対応業務での信頼性を損なう原因となります。対策としてRAGの導入が有効です。
LLMの種類を選定する際のプライバシーポリシー(コンプライアンス)
LLMを商用利用する企業は、入力データの取扱いに細心の注意を払う必要があります。
- クローズドLLM:APIプロバイダーが、入力データを「モデル改善のために利用しない」ことを保証しているか確認します。特に、機密情報や個人情報を扱う際は、データ保全契約(BAA)が可能な法人向けAPIを選択する必要があります。
- オープンソースLLM:ローカル環境で実行すれば、データが外部に渡るリスクは最小限に抑えられます。
LLMの種類別総合比較テーブルと最終チェックリスト
LLMの種類別総合比較テーブル
2025年最新の主要LLMの種類を、初心者にも分かりやすい言葉で比較します。
| LLMの種類 | 提供元 | 最大の特徴 | 得意な用途 | 日本語性能 | 商用利用 |
| GPT-5 | OpenAI | 次世代の圧倒的な推論能力/RAG強化 | 高度な専門的課題解決 | 最高水準 | 可能(API) |
| Gemini 2.5 Pro | 超長コンテキスト/ネイティブマルチモーダル | 大量データ分析/複雑な文脈理解 | 高い | 可能(API) | |
| Claude 4 Opus | Anthropic | 倫理的/安全性と長文理解に特化 | 信頼性が重要な業務(契約書) | 高い | 可能(API) |
| Llama 4 | Meta | オープンソース/自由なカスタマイズ | ローカル開発/データ主権を重視 | 高い | 可能(ライセンス確認) |
| phi-4 | Microsoft | 超軽量/教育的推論に特化 | エッジ環境/個人学習/スマホアプリ | 中程度 | 可能(ライセンス確認) |
LLMの種類を選ぶ上での最終チェックリスト
LLMの種類を決定する前に、以下の点を必ず確認しましょう。
- タスクの種類の明確化:生成したいコンテンツ(要約、コード、対話)は何か。
- データ機密性:扱うデータに個人情報や機密情報が含まれるか。含まれる場合は、オープンソースか、法人向けAPIを選択。
- 応答速度要件:リアルタイム応答が必要か。必要であれば、Fast/Flash/Mini種類のモデルやGroqを検討。
- コスト許容範囲:月間API利用予算はどれくらいか。課金上限を設定。

付録1:LLMの深層技術と開発フレームワーク
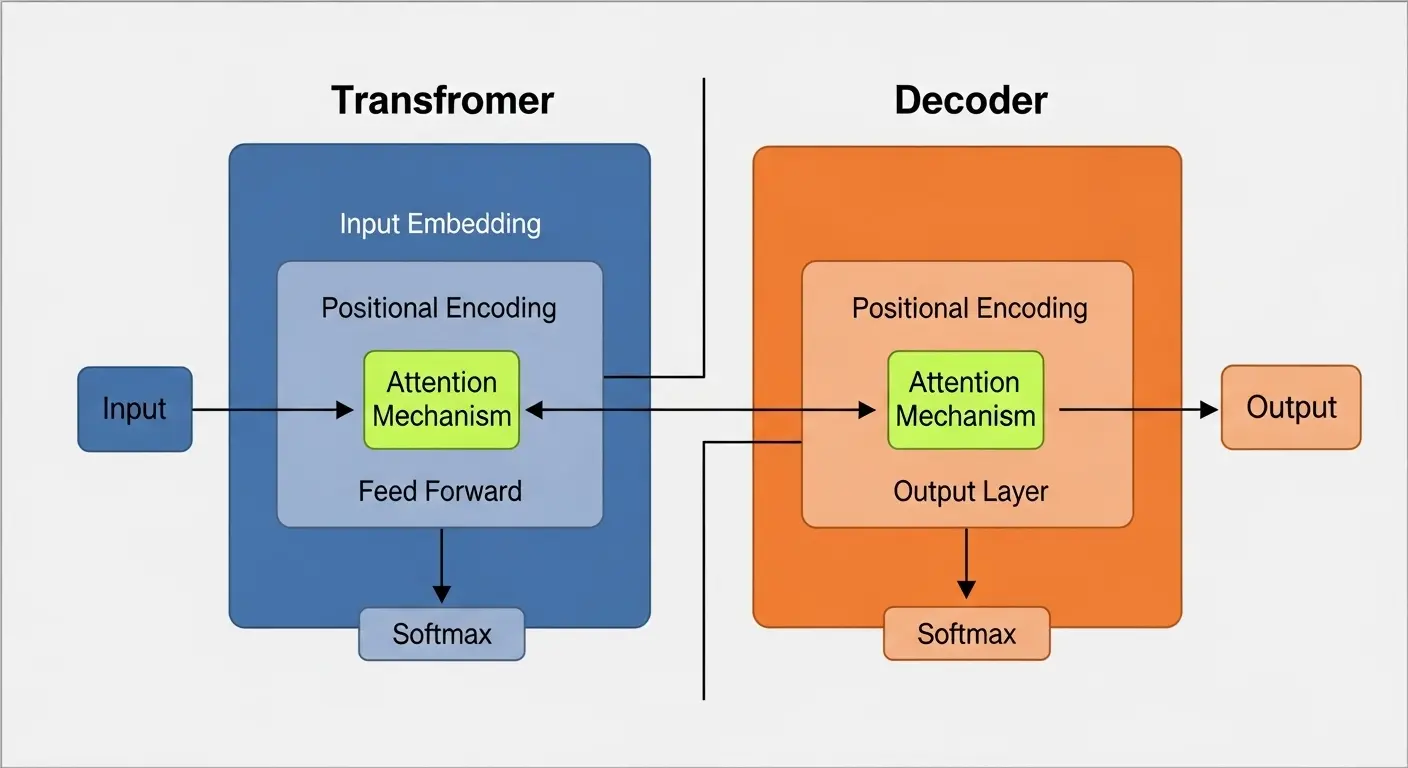
LLMの仕組み:エンコーダー/デコーダー構造
LLMの種類の多くは、Transformer(トランスフォーマー)アーキテクチャに基づいており、大きく分けて「エンコーダー」と「デコーダー」の2つの構造を持っています。
- エンコーダー:入力された文章(プロンプト)を読み込み、その文脈的な意味を理解し、内部的な数値表現(ベクトル)に変換する役割を担います。
- デコーダー:エンコーダーが変換した情報をもとに、次に出現する単語(トークン)の確率を予測しながら、一つずつ単語を生成し、最終的な回答文章を構築します。
LLMの種類と構造の分類
- Encoder-Decoder 型:元のTransformerの構造。BERTなど。入力の理解に優れ、分類や質問応答に特化。
- Decoder-only 型:デコーダーのみで構成。GPT/Llama/Gemini/Claudeなど。文章生成に特化し、現在の対話型AIの主流。
LLMの種類と連携:LangChain/LlamaIndex
LLMの種類を利用した複雑なアプリケーションの開発には、LangChainやLlamaIndexといったLLMアプリケーション開発フレームワークが不可欠です。
- 役割:LLMを中心に、RAG、エージェント、外部ツール(検索、データベース)を連携させるプロセスを管理し、開発の効率を大幅に向上させます。
付録2:LLM導入のステップと関連リソース
LLM商用利用の3ステップ
LLMの種類をビジネスに導入し、商用利用を開始するためには、以下のステップを踏むことが推奨されます。
- PoC(Proof of Concept):無料枠や、安価なMini/Flash種類のLLMを利用して、目的とするタスクがLLMで実現可能かを検証します。この段階でLLMの種類の絞り込みを行います。
- パイロット導入:選定されたLLMの種類を、一部の部署や、限定的な顧客層に対し、本格導入前の試験的な運用を開始します。精度、応答速度、コストを詳細に評価します。
- 本格導入と運用最適化:評価結果に基づき、有料プランへ移行し、全社的な展開を行います。運用開始後も、LLMOやRAGの手法で継続的に性能を最適化します。
LLMの種類に関するFAQ
- Q1: LLMの種類ごとの最大の違いは何ですか? A1: LLMの種類の最大の違いは、1. 学習データの量と質、2. パラメータの数(モデル規模)、3. 独自のアーキテクチャ(例:MoE)、4. ファインチューニングの方法(例:安全性重視のClaude)です。これにより、回答の精度、推論能力、得意なタスク(コーディング、長文理解など)に違いが生じます。
- Q2: LLMを利用する上で、「ハルシネーション」対策はどうすれば良いですか? A2: ハルシネーション(AIが誤った情報を生成する現象)対策として、RAG(検索拡張生成)の導入が最も有効です。RAGは、LLMが外部の信頼性の高いデータ源(社内データベース、Webサイトなど)を参照して回答を作成する手法です。また、LLMの種類の選定時に、GPT-5やClaude 4のように、ハルシネーションの抑制が強化された最新モデルを選ぶことも重要です。
- Q3: LLMの種類は、スマホ(iPhone/Android)でも利用可能ですか? A3: はい、可能です。利用方法は、大きく分けて2種類あります。1. ChatGPT/Gemini/Claudeなど、APIを利用した「クラウドベース」のアプリを利用する方法。2. phi-4や、軽量オープンソースLLMの種類を、モバイル環境で実行できるアプリ(Ollamaなど)を利用する方法です。2. の方法は、オフライン利用や、データプライバシーを重視したい場合に最適です。
LLMの種類は、
- クローズドLLM(GPT, Gemini, Claude)
- オープンソースLLM(Llama, Mistral)
に大別されます。
それぞれ
- 性能
- コスト
- セキュリティ
- カスタマイズ性
の面で異なります。
2025年の最新動向として、
- マルチモーダル化
- エージェント化
- 小型LLM
の台頭が顕著です。
LLMの種類を選定する際には、
- 「タスク要件」
- 「データ機密」
- 「コスト制約」
の3点を総合的に比較しておきましょう。
可能であれば、複数のLLMを組み合わせる「マルチLLMアーキテクチャ」の導入を検討することが成功の鍵となります。
この記事で得た LLMの種類に関する知識をもとに、ぜひ、あなたの次のAI開発の一歩を踏み出してください。
信頼できる情報源と外部リソース
E-E-A-T(経験、専門性、権威性、信頼性)を高めるため、LLMの種類に関する知識を得るために、以下の公式サイト(外部リンク)を参考にしてください。
- OpenAI Developers Docs: https://platform.openai.com/docs/introduction
- Google AI Studio Docs:
https://ai.google.dev/ - Anthropic Claude Documentation:
https://docs.anthropic.com/en/ - Hugging Face Hub Models:
https://huggingface.co/models - Groq Cloud Documentation:
https://console.groq.com/docs/ - Meta AI (Llama) Research:
https://ai.meta.com/ - Microsoft Azure AI Services:
https://azure.microsoft.com/ja-jp/products/ai-services/
