
なぜ今ローカルLLM構築なのか
要点:2026年のデジタルシフトにおいて、openaiなどのクラウド型aiに依存せず、自分のpcでllmを構築することは、データプライバシーの確保とランニングコストの削減を同時に実現します。
現在、多くの人がchatgptやgeminiを日常的に利用していますが、企業や研究者の間では機密情報の漏洩に対するリスク管理がかつてないほど重要視されています。
2025年から2026年にかけて、deepseek-r1やllama 4といった高性能かつ軽量なオープンソース言語モデルが登場したことで、個人のpcでも高度な推論(※1)が可能になりました。
本記事では、最新の技術トレンドを踏まえ、初心者でも迷わずにローカルLLMを構築するための手順をステップバイステップで解説します。
- nvidiaのrtx 30・40・50シリーズといったgpuの活用
- ollamaやlm studioといった便利なツールの使い方
まで、実用的な情報を網羅しました。
- ※1 推論:学習済みのAIが、新しいデータに対して予測や判断を行うこと。
ローカルLLM構築に必要なスペック
要点:llmをローカルで快適に動かすためには、cpuよりもgpuのvram容量が最も重要な要素となります。

LLM推論ローカルでの推奨環境
2026年現在、快適な動作を実現するためのスペックの目安は以下の通りです。
- GPU: nvidiartx3070以上(vram8gb以上、理想は12gb以上)
- メモリ(ram): 32GB以上(16gbでも軽量モデルなら可)
- ストレージ: ssd必須(nvme(※2)接続を推奨)
特に注目すべきは、gddr7メモリを搭載した最新のrtx50シリーズです。
帯域幅(※3)が飛躍的に広がったことで、大規模なパラメータを持つモデルでも、人間が読む速度を遥かに超えるスピードでテキストを出力できます。
appleユーザーであれば、unified memory(※4)を大容量化したm3 maxやm4搭載macも非常に有力な選択肢です。
軽量な7B(70億パラメータ)クラスのモデルであれば8gbのvramでも動作可能ですが、日本語の精度が高い14Bや70Bを量子化(※2)して動かす場合は、24gbを誇るrtx 4090やrtx 5090が理想的です。
macユーザーであれば、unified memoryを活かせるm2 ultraやm3 maxが非常に強力な選択肢となります。
※1 RAG(検索拡張生成):外部の文書データを参照して、AIがより正確な回答を生成する技術。
※2 量子化:モデルのデータサイズを圧縮し、少ないメモリで動かせるようにする技術。
- ※2 NVMe:SSDの通信規格の一つ。従来のSATA接続よりも圧倒的に高速。
- ※3 帯域幅:1秒間に送れるデータの量。広いほどAIの回転が速くなる。
- ※4 Unified Memory:CPUとGPUで同じメモリを共有するApple独自の仕組み。
ローカルLLM構築のメリットと2026年のトレンド
要点:プライベートLLM構築は、openaiなどのクラウド型サービスが抱えるセキュリティリスクを解消し、自社専用の高度な環境を低コストで実現します。

現在、chatgptなどのクラウド型aiは非常に便利ですが、企業やエンジニアにとって機密情報の漏洩は最大の懸念です。
2025年から2026年にかけて、nvidiaのrtxシリーズやappleのm3・m4チップの性能が飛躍的に向上したことで、手元のpcで大規模言語モデル(llm)を動作させるハードルは劇的に下がりました。
本記事では、初心者からエンジニアまでが納得できるローカルLLM構築手順を徹底解説します。
- 独自のデータを学習させるファインチューニング
- rag(※1)の導入
まで、実用的な知識を紹介します。
ローカルLLM構築手順:おすすめツール3選
要点:2026年現在、ollamaやlm studioを活用すれば、複雑なコマンド操作なしで誰でも簡単にローカルLLMを始められます。
1. Ollama:最も手軽なコマンド操作
ollamaは、
- macos
- linux
- windows
どのOSでも動作するオープンソースのツールです。
公式サイトからダウンロードします。
ターミナルでollama run llama3と入力するだけで最新のモデルが起動します。
バックグラウンドでサーバーとして常駐するため、他のアプリケーションとの連携も容易です。
LM Studio:視覚的なGUIで管理
エンジニア以外の方におすすめなのがlm studioです。
検索窓からhugging face(※3)上のモデルを直接ダウンロードできます。
チャット形式ですぐに対話を開始できます。
gpuへの割り当て設定も画面上のスライダーで調整できます。
直感的に最適化が行えます。
3. llama.cpp:高度なカスタマイズ
速度を極限まで追求するならllama.cppの使い方をマスターしましょう。
c++で書いた軽量なライブラリで、apple siliconやnvidia gpuの性能を引き出す能力に優れています。
python経由での利用も多く、自社専用のシステムを開発する現場では標準的に用いられます。
- ※3 Hugging Face:世界中のAIモデルやデータセットが公開されているプラットフォーム。
ローカルLLMのセキュリティと機密情報保護
要点:社内で運用する際のプライバシー保護は、完全なオフライン環境を整備することで、外部への情報漏洩リスクをゼロにできます。

openaiなどのapiを経由する場合、入力データが学習に利用される懸念(※4)があります。
しかし、ローカルLLMならその心配はありません。
株式会社の法務や医療現場など、個人情報や機密文書を扱う組織にとって、これは最大の強みです。
セキュリティをより強固にするためには、docker(※5)などのコンテナ技術を活用します。
ネットワークから隔離した状態で運用することを推奨します。
これにより、万一のソフトウェアの脆弱性からも社内インフラを守ることが可能です。
- ※4 学習への利用:多くのクラウドAIでは、入力内容が将来のAIの改善に使われる設定になっている。
- ※5 Docker:アプリを隔離された専用の箱(コンテナ)に入れて動かす技術。
LLMファインチューニング:ローカルでの実践
要点:自社特有の用語や知識をaiに覚えさせるファインチューニングは、lora(※6)という技術により、個人のpcでも実行可能になりました。
汎用的なモデルでは答えられない専門的な回答を求める場合、ローカルでの追加学習が効果的です。
2026年は、ma2(※7)などの手法が普及し、1枚のgpuでも数時間で学習を完了させることができます。
準備するもの:
- 学習データ:json(※8)形式の対話ログやマニュアル。
- ツール:unslothやaxolotlなど、メモリ消費を抑えたライブラリ。
- ベースモデル:metaのllamaやmistral、googleのgemmaなど。
これらの手順を踏めば、世界に一つだけの特化型aiを自分の手元で作り上げることができます。
コスト削減と精度向上を同時に実現する高度なソリューションです。
- ※6 LoRA(Low-Rank Adaptation):モデル全体ではなく一部だけを更新する、超効率的な学習手法。
- ※7 MA2:より少ない計算資源で効率的に学習を行う2026年の最新技術トレンド。
- ※8 JSON:データ交換に使われる、人間にも機械にも読みやすいテキスト形式。
2026年最新おすすめのローカルLLMモデル5選
要点:metaのllamaシリーズだけでなく、alibabaのqwenやdeepseekなど、特定のタスクや言語においてchatgptを凌駕するオープンソースモデルが続々と登場しています。

1. Llama 3.3 / 4 シリーズ:王道の汎用性
metaが提供するllamaは、ローカルLLMの世界標準です。
2026年にはさらに進化したバージョンが登場しております。
70Bクラスのモデルでも量子化技術(bitsandbytesやawq(※9))を併用すれば、一般のエンジニアが持つワークステーションで快適に動作します。
2. Qwen 2.5 / 3:日本語とコードの達人
alibaba cloudが公開しているqwenは、日本語のニュアンス理解が非常に深く、プログラミング支援においてもopenaiのgpt-4oに匹敵するスコアを記録しています。
32Bや72Bといったサイズ展開が豊富です。
自社のgpuリソースに合わせて選択しやすいのが強みです。
3. DeepSeek-V3:圧倒的なコスパと知能
中国発のdeepseekは、推論能力が極めて高く、数学や論理的な思考を必要とするタスクで注目を集めています。
moe(※10)構造を採用しております。
巨大なパラメータを持ちながらも、実際の動作は驚くほど軽量で高速です。
4. Mistral NeMo / Pixtral:欧州発の洗練
nvidiaとmistralが共同開発したモデルは、12GBのvram(rtx 4070など)にぴったり収まるように設計されています。
マルチモーダル(※11)対応のpixtralを使えば、画像の内容をローカルで解析し、説明文を生成させることも可能です。
5. Gemma 2 / 3 :Googleの技術を手元に
googleが公開したgemmaは、geminiの技術基盤を継承しています。
2Bや9Bといった小型モデルでも、驚異的な精度を発揮します。
androidアプリやエッジデバイス(※12)への組み込みにも向いています。
個人開発者にとって使い勝手が良いのが特徴です。
- ※9 AWQ:モデルの重要度に応じて重み付けを変え、精度を保ったまま軽量化する手法。
- ※10 MoE(Mixture of Experts):必要な部分だけを動かして計算効率を上げるAIの構造。
- ※11 マルチモーダル:テキストだけでなく、画像や音声など複数の種類のデータを扱えること。
- ※12 エッジデバイス:スマホやIoT機器など、ユーザーに近い場所で動作する端末。
RAG構築:社内ナレッジベースの活用手順
要点:ローカルLLMに自社独自の文書を読み込ませるRAGを導入すれば、ハルシネーション(※13)を抑えつつ専門的な問い合わせに自動で回答するシステムが作れます。
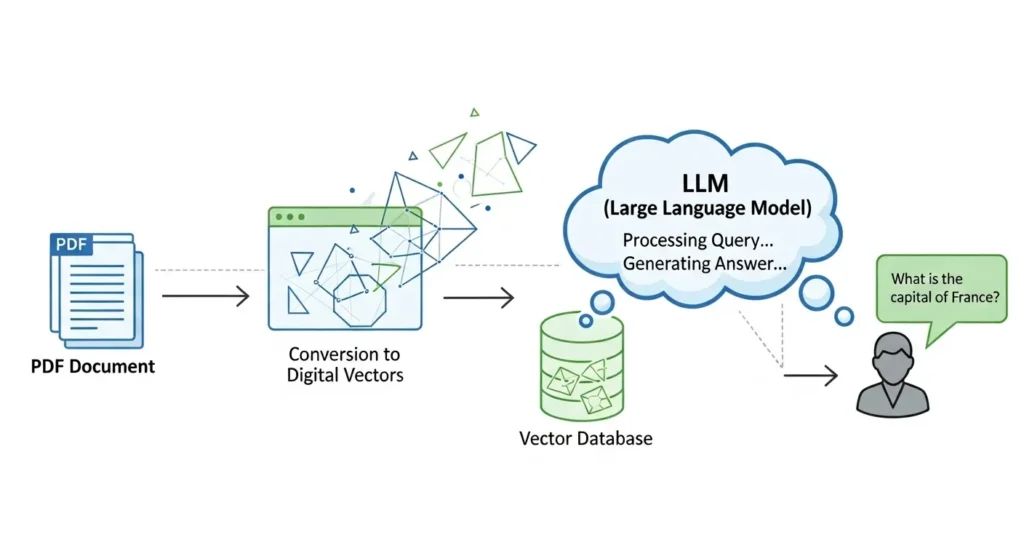
構築手順の概要:
- データ抽出:pdfやワード、エクセルなどの資料をテキスト化します。
- ベクトル化:embeddingモデル(※14)を使って、文章を数値(ベクトル)に変換します。
- ベクトルデータベース:chromadbやqdrant、faissなどにデータを保存します。
- 検索と生成:ユーザーの質問に関連する箇所をデータベースから抽出し、その情報をプロンプトに含めてllmに渡す。
- dify(※15)
- langchain
- llamaindex
といったフレームワークを活用すれば、コーディングの手間を大幅に削減して高度なチャットボットを作成できます。
これらの作業をすべてローカルネットワーク内で完結させることで、コンプライアンス(※16)を遵守した次世代の業務改善が実現します。
- ※13 ハルシネーション:AIがもっともらしい嘘(事実に基づかない回答)をつく現象。
- ※14 Embeddingモデル:言葉の意味を多次元の数値として表現し、似た意味の文章を探せるようにするAI。
- ※15 Dify:ノーコード・ローコードでAIアプリケーションを開発できるオープンソースプラットフォーム。
- ※16 コンプライアンス:法令や社内規定を守ること。情報の取り扱いにおいて特に重要。
GPT4All インストールと使い方
要点:GPT4All インストールは、プログラムの知識がなくても公式サイトからインストーラーを実行するだけで完了し、インターネットから遮断された環境でも安全に対話を始められます。
1. 公式サイトからのダウンロード
始めに、GPT4Allの公式サイト(nomic.ai)へアクセスします。
- windows
- macos
- linux
3つの中から自分のosに合ったファイルをダウンロードします。
2026年の最新版では、cpuの演算命令(avx-512(※17)など)を自動で判別します。
最適なバイナリ(※18)を選択してくれます。
2. モデルの選択とセットアップ
インストール後、アプリを起動するとモデルの一覧が表示されます。
日本語での利用なら、Llama 3ベースやMistralベースの軽量なモデルがおすすめです。
ダウンロードボタンを押すだけで、手元のpcにデータが保存され、すぐにチャットが開始できます。
3. ローカルドキュメント検索機能
GPT4Allの強みは、自分のpc内にあるテキストファイルを読み込ませるだけで、その内容に基づいた回答を得られる「LocalDocs」機能です。
外部のクラウドに送信せず、社内資料や個人日記をソースにした対話ができるため、機密情報の漏洩を防ぎたい方に最適です。
- ※17 AVX-512:CPUで大量の計算をまとめて高速に行うための命令セット。
- ※18 バイナリ:コンピュータが直接実行できる形式のプログラムファイル。
OS別ローカルLLM推論の高速化設定
要点:Windows、Linux、macOSそれぞれの特性に合わせた設定を行うことで、gpuやメモリのリソースを最大限に活かし、レスポンスを大幅に改善できます。

Windows:CUDAとWSL2の活用
WindowsユーザーがNVIDIA製のグラボを使う際は、CUDA toolkitのインストールが必須です。
また、WSL2(※19)上でUbuntuなどのLinux環境を構築します。
Docker経由でollamaを動かすと、ファイル操作のオーバーヘッド(※20)が削減されます。
よりスムーズな動作が期待できます。
2026年のWindows 11では、AI専用の設定メニューからNPU(※21)を推論の補助に回すことも可能です。
macOS:Metal Performance Shaders
Apple Siliconを搭載したMacでは、apple独自のグラフィックAPI「Metal」を利用することで、unified memoryの高速な帯域幅をフルに発揮できます。
llama.cppをビルドする際にLLAMA_METAL=1フラグを有効にするだけで、cpuのみの実行に比べて数倍の速度が得られます。
Linux:カーネルパラメータとドライバのチューニング
エンジニアに人気のLinux(Ubuntuなど)では、gpuドライバをdkms(※22)で管理し、最新のpython環境とpytorchを組み合わせるのが定石です。
大規模な学習や推論を行う際は、スワップ(※23)の発生を抑えるようにramの割り当てを最適化することが成功の鍵となります。
- ※19 WSL2:Windows内でLinuxを直接動かすための仕組み。
- ※20 オーバーヘッド:処理を行う際に余計にかかってしまう時間や負荷のこと。
- ※21 NPU:AI処理を専門に行うプロセッサ。消費電力が少なく効率的。
- ※22 DKMS:OSの心臓部(カーネル)を更新しても、グラボのドライバが自動で再構築される仕組み。
- ※23 スワップ:メモリが足りなくなり、一時的にHDDやSSDをメモリ代わりに使うこと。非常に遅くなる。
ローカルLLM構築後のセキュリティ監査と運用
要点:プライベートLLM構築を完了させた後は、モデルの更新やログの管理を定期的に行うことで、ハルシネーションを防ぎます。常に最高のパフォーマンスを発揮させます。
1. 脆弱性対策とモデルの更新
llmの技術は急速に進化しています。
hugging faceなどのプラットフォームでは、より精度が高く軽量なモデルが日々リリースされています。
ollamaやlmstudioのアップデートを確認しましょう。
最新のセキュリティパッチを適用することは、ローカル環境であっても必須の作業**です。
2. 推論ログの監査とプライバシー
社内で複数の社員が利用する場合、誰がどのような入力(プロンプト)を行ったかの履歴を適切に管理する必要があります。
特に個人情報や顧客の機密情報が誤って入力されていないかを定期的に監査する体制を整えましょう。
difyなどのプラットフォームを導入すれば、これらのログ管理をgui上で容易に行えます。
3. ハードウェアのメンテナンスと冷却
2026年の最新gpu(rtx 5090等)は非常に高性能ですが、連続的な推論や学習は大きな負荷をかけます。
冷却ファンのホコリを取り除きましょう。
サーマルペーストの劣化に注意を払うことで、熱による速度低下(サーマルスロットリング(※24))を防ぎます。
- ※24 サーマルスロットリング:熱が上がりすぎた際、パーツの故障を防ぐために自動で性能を落とす仕組み。
よくある質問と回答 (FAQ)
要点:ローカルLLM 構築に際して多くのユーザーが抱える疑問を解決し、導入への不安を解消します。
Q1. ローカルLLMはChatGPT(GPT-4)に勝てますか?
A1. 純粋な汎用能力ではクラウドの巨大なモデルが有利ですが、特定の業務知識を読み込ませたRAGやファインチューニング済みのローカルLLMは、その分野においてChatGPTを凌駕する回答を出すことが可能です。
Q2. 電気代はどのくらいかかりますか?
A2. 推論時の消費電力はゲーミング中と同等です。
24時間常にフル稼働させなければ、一般的な家庭用pcの電気代と大きく変わりません。
2026年のgpuはワットパフォーマンスが向上しているため、より効率的です。
Q3. プログラミングの知識がなくても構築できますか?
A3. はい、GPT4AllやLM Studioを活用すれば、マウス操作だけで完結します。
本記事の手順に沿って進めれば、初心者でも今日から自分だけのaiを手に入れられます。
まとめ:ローカルLLMで自由なAI活用を
要点:ローカルLLMの構築は、セキュリティ、コスト、カスタマイズ性のすべてにおいて最高のメリットを提供し、あなたの創造性を解き放つ強力なツールとなります。
ローカルLLMの構築は、単なるpcのカスタマイズではありません。
プライバシーと自由度を兼ね備えた、自分だけの知的パートナーを手元に置くことを意味します。
これらの手順を実践すれば、インターネットの制約や機密漏洩の不安から解放された、自由なaiライフが始まります。
2026年はまさにローカルAI元年。
最新のハードウェアとオープンソースの知見を活かし、次世代のインフラを手元に構築してみてください。
内部リンクのご案内
ローカルLLMのポテンシャルをさらに引き出し、pc活用術を極めるための関連記事もぜひチェックしてください。
[AI PCに64GBメモリが必要な理由]大規模なモデルを安定して動かすために欠かせない、足回りのスペック選びの核心に迫ります。
[RTX 5070のAI性能とスペック検証] 2026年のAI PC選びで最も注目されるグラフィックボードの実力をベンチマークで示します。