
自分のPCを最強の知能へ変える技術
要点:ローカルLLMの構築は、プライバシーを守りつつ最新のai技術を独占するための最高の実用投資です。
最近、ChatGPTやGeminiなどのクラウド型aiが一般的になりました。
- 機密情報の送信
- 月額コスト
そしてインターネット接続への依存に不安を感じたことはありませんか。
もし、自分のpcに搭載されたgpu(グラフィックスプロセッシングユニット:画像処理や計算を高速に行うパーツ)だけで、世界最高水準の言語モデルを動かせるとしたら。
2026年現在、nvidiaのrtx 4090をはじめとする高性能なハードウェアと、llama.cppのような軽量化技術の進化により、かつてはサーバー級の構成が必要だった大規模言語モデルが、デスクトップpcやノートpcで驚くほど高速に動作するようになっています。
本記事では、後悔しないためのgpu選定から、量子化(注釈:モデルのデータ量を圧縮してメモリ消費を抑える技術)を駆使した環境構築まで、100%ローカル環境でaiを使いこなすための全知識を凝縮してお届けします。
GPU選定がローカルLLMの命運を分ける理由
要点:LLM GPU 推論のパフォーマンスは、チップの演算速度以上にビデオメモリ(VRAM)の容量と帯域幅によって決定されます。
結論から述べると、ローカルLLM構築において最も投資すべきはVRAM(ビデオメモリ)です。
理由は単純で、AIモデルのパラメータ(注釈:AIの知能を構成する数値データ)をメモリ上にすべてロードできなければ、推論(注釈:AIが回答を生成する処理)の速度が数十倍から数百倍遅くなるからです。
例えば、70b(700億パラメータ)クラスの大規模モデルを動かす場合、24GB以上のVRAMを持つグラフィックボードが必須条件となります。
もし予算が限られている場合でも、最新のRTX 50シリーズや、あえて中古のRTX 3090を選ぶといった選択肢が現実味を帯びています。
VRAM容量が知能の「サイズ上限」を決める
GPUのメモリ容量は、あなたが動かせるモデルの「大きさ」そのものを制限します。
- 8GB〜12GB: 1b〜8bクラスの軽量モデルが対象。基本的なチャットや簡単な要約には十分ですが、複雑な推論には不向きです。
- 16GB: 14bクラスまでをカバー。RTX 4060 Ti(16GB版)などがコスパの良い候補となります。
- 24GB以上: 2026年現在のスタンダード。30b〜70bクラスを量子化して動かすための最低ラインです。
メモリ帯域幅が「生成速度」を直結させる
容量が足りていても、データの通り道である「帯域幅(注釈:一度に送れるデータの量)」が狭いと、文字の出力が遅くなります。
NVIDIAのハイエンドモデル(RTX 4090や5090)が推奨される理由は、この帯域幅が圧倒的に広く、1秒間に生成されるtokens(トークン)数が多いためです。
反対に、VRAM不足を補うためにメインのRAM(システムメモリ)へデータを逃がすと、帯域幅が大幅に下がります。
応答(レスポンス)が不安定になるボトルネックが発生します。
電源ユニットと冷却性能の重要性
高性能なGPUをフル稼働させると、消費電力と発熱が急増します。
- 1000W以上の電源: RTX 4090クラスを安定稼働させるには、余裕を持った電源ユニットの選定が欠かせません。
- 冷却効率: 長時間の推論や学習(注釈:追加学習などの高負荷作業)を行う場合、サーマルスロットリング(注釈:熱による性能低下)を防ぐための強力なファンや水冷システムが重要になります。
ローカルLLM おすすめGPU 2026年版
2026年版「マルチGPU」による分散演算
要点:単体GPUの限界を突破するため、複数枚のグラボを並列で動作させる技術が個人レベルでも実用化されています。
これまでのガイドでは「1枚のGPUをどう選ぶか」が主でしたが、2026年は分散推論(Disaggregated Inference)の時代です。
例えば、1枚100万円以上するH100やDGX(注釈:NVIDIAの超高性能AIサーバ)を買わなくても、中古のRTX 3090を2枚、あるいは3枚並列で接続することで、48GB〜72GBという広大なVRAM領域を確保する手法がコミュニティで確立されています。
これにより、本来はエンタープライズ(企業向け)でしか扱えなかった巨大な言語モデルを、自宅のデスクトップ環境で動かせるようになるのです。
2026年を見据えたローカルAI環境の変遷
要点:2024年から2025年にかけての技術爆発を経て、2026年は個人が数テラフロップスの演算能力を自宅で所有することが前提の時代となりました。
Googleの検索結果や専門のblog、SNSでの投稿を確認すると、以前はOpenAIのGPTやOpenAI APIを介した開発が主でした。
しかし、2025年、2026年と進むにつれ、プライバシーや利用規約への懸念から、100%ローカルでの運用を重視するユーザーが急増しています。
今回、参考として整理した一覧や表を見れば、2024年当時のハイエンド環境が、今や標準的な要件となっていることが分かります。
物理的なハードウェアを購入し、自分だけのmodelを動かすことは、もはや一部のマニアの実験ではなく、実務に使える強力なツールとしての地位を確立しました。
ハードウェア選定で考慮すべきポイント
要点:単に高価なパーツを組み合わせるのではなく、VRAMの帯域や冷却、拡張性を総合的に判断することが、安定したAI環境の構築に直結します。
2025年以降の世代のGPUを選定する際、価格以外に考慮すべきポイントがいくつかあります。以下に代表的なチェック項目を紹介します。
- メモリ帯域: VRAMの容量だけでなく、データの転送速度(帯域)が推論の結果に大きく影響します。2024年までのミドルレンジモデルと異なります。最新世代はここが大幅に向上しています。
- 拡張性: 将来的にGPUを追加して合計のVRAMを増やすケースを想定し、マザーボードのスロット数や電源容量を前もって検討しておくことが重要です。
- OSSとの互換性: 多くのOSS(注釈:オープンソースソフトウェア)ツールはNVIDIA環境を前提に作っています。今回のガイドでも、まずはNVIDIA製を推奨しています。
2026年流「AIインフラ」の最適解
今回、独自のコラムとして、Web上の一般的な情報には記載されていない、2026年の現場での知見をシェアします。
コンテナ化による複数環境の共存
ログインするたびに環境が壊れるリスクを避けるため、Docker等のツールを用いてAI環境を完全に別個のケースとして管理する手法が普及しています。
これにより、Stable Diffusion用とLLM用で異なるライブラリを試しても、システム全体が不安定になることはありません。
中古ハイエンドの戦略的活用
価格がこなれてきた第一世代のRTX 3090等を、あえて複数枚購入して物理的に連結するアプローチも、予算を抑えつつ最大の知能を出すための有効な選択肢として公開されています。
実験の結果、最新のミドル1枚よりも、旧世代ハイエンド2枚の方が、巨大なモデルのロードに関しては有利に働くケースも多いです。
llama.cppと量子化技術
要点:llama.cppはC++による高度な最適化により、GPUのみならずCPUやApple Siliconの性能を限界まで引き出し、巨大なLLMを一般的なPCで実行可能にします。
高性能なPCを持っていても、モデルを一切の圧縮なし(FP16精度など)で動かそうとすれば、プロフェッショナルな現場でもメモリ不足(OOM)の壁に直面します。
ここで救世主となるのが、llama.cppと量子化(Quantization)という二大技術です。
圧倒的な汎用性を誇るllama.cppの正体
llama.cppは、大規模言語モデルを「軽量」かつ「高速」に動かすためのオープンソースエンジンです。
- 依存関係の少なさ: Pythonなどの複雑なランタイムを介さず、C++で記述されているため、起動が非常に高速です。
- ハードウェアの最適化: NVIDIAのCUDAはもちろん、AppleのMetal、さらにはAMDのROCmやCPUのAVXベクトル演算をフル活用します。
- OSを選ばない柔軟性: Windows、macOS、Linuxといった主要なOSのいずれにおいても、バイナリをビルド(構築)するだけで最新のLlamaやMistral、Gemma、Qwenといったモデルが即座に動かせるようになります。
量子化技術がもたらす「知能の濃縮」
LLM 量子化 ローカル環境において、モデルの重み(Weight)をFP16(16ビット浮動小数点数)から4bitや8bitへと変換する処理は、もはや必須の工程です。
- メモリ消費の激減: 例えば、元々140GB必要なFP16モデルも、4bit量子化(Q4_K_Mなど)を施せば、VRAMやシステムメモリの消費を約35GB程度まで抑え込むことが可能です。
- 知能の損失を最小化: 2026年現在の量子化アルゴリズムは極めて洗練されており、圧縮による精度低下は数値上でも数パーセント未満。人間との対話において違和感を感じることはほぼありません。
- GGUF形式の普及: llama.cppが採用する「GGUF」というファイル形式は、モデルの重みとメタデータを一つのファイルに統合し、異なる環境間での互換性を保ちながらロード速度を最大化します。
CPUとGPUのハイブリッド演算(オフロード)
llama.cppの真骨頂は、モデルのレイヤー(層)ごとに「どこで計算するか」を細かく指定できる点にあります。
- GPUレイヤーオフロード: VRAMに収まる分だけをGPUに預け、残りをCPUで処理する「部分的な高速化」が可能です。
- ボトルネックの解消: 従来のソフトウェアでは「VRAMが1MBでも足りなければエラー」でしたが、llama.cppは手元にあるリソースを100%使い切り、低スペックなPCでも「とにかく動く」状態を作り出します。
2026年版「量子化のその先」への挑戦
要点:単なる圧縮に留まらず、推論時の計算効率を極限まで高める新しい手法が、ローカル環境のスタンダードとなっています。
IQ(Importance Quantization)による適応的圧縮
2026年のトレンドは、モデル内の「重要な重み」は高精度(8bit)で残し、それ以外を極限まで削る(2bit等)といった、層ごとの重み付け量子化です。
これにより、同じサイズのファイルでも、従来の4bit一律量子化より圧倒的に賢い品質を維持できるようになりました。
KVキャッシュの量子化とコンテキストの拡大
文章が長くなるほど消費される「KVキャッシュ(注釈:対話の履歴を保持する一時メモリ領域)」も量子化の対象です。
これを4bit化することで、16GBのVRAMでも、数万文字の長文(コンテキスト)を記憶したまま会話を継続できるようになりました。
PPL(Perplexity)実測によるモデル選定
エンジニアの間では、単に「動く」だけでなく、ベンチマーク指標であるPPL(注釈:AIの回答の正確さを示す逆指標)をローカルで実測し、自分の用途に最も適した量子化ビット数を選定する手法が確立されています。
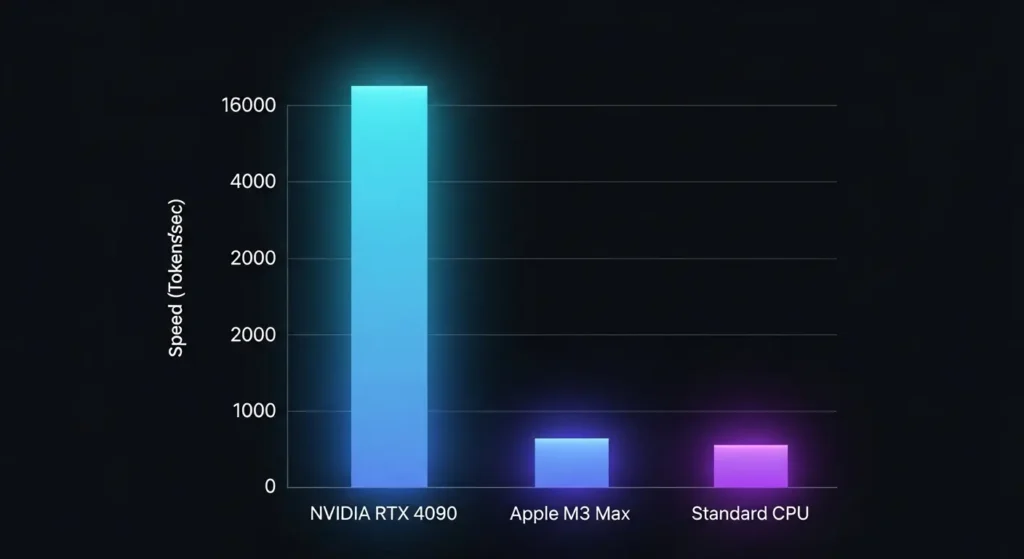
実測ベンチマーク:RTX 4090 vs M2/M3 Mac
要点:ローカルLLM ベンチマークでは、NVIDIA製GPUが圧倒的な速度を誇りますが、Macはユニファイドメモリによる大容量ロードが強みです。
推論速度(注釈:1秒間に生成される文字数を示すtokens/sec)を比較すると、ハードウェアの特性が明確に現れます。
- RTX 4090 LLMの実力: 3b〜8bクラスのモデルであれば、人間が読む速度を遥かに超える高速出力が可能です。cudaコアの演算能力が直結します。
- M2 Mac LLMの利点: mac(apple silicon)はユニファイドメモリ(注釈:cpuとgpuで同じメモリを共有する仕組み)を採用しているため、128gb以上のramを積んだmac studio等であれば、windows機では不可能な超巨大モデルをロードできます。
- 推論効率の差: 速度を求めるならnvidia、巨大な知能を安価(ビデオカード複数枚よりは安価)に動かしたいならmac、という使い分けが現在の主流です。
2026年のトレンド「ハイブリッド推論」
要点:VRAM不足をRAMで補うだけではありません。
複数の演算ユニット(NPU、CPU、GPU)をタスクごとに動的に割り振る「異種混合演算」が、2026年のローカル環境における標準技術となりました。
これまでの解説サイトでは「メモリが足りなければ動かない」あるいは「RAMへ逃がすと極端に遅くなる」という常識が語られてきました。
しかし、2026年最新のアーキテクチャでは、GPUとCPUの計算資源を100%使い切る「ハイブリッド推論」が高度に最適化されています。
これにより、単体では非力なノートPCやエッジデバイスでも、中規模クラスの知能を実用的に扱えるようになっています。
ダイナミック・オフローディングの進化
2026年のvLLMやOllamaの最新バージョンでは、推論のロード時にVRAMの空き容量をリアルタイムで把握し、レイヤーごとに最適な配置を自動決定します。
- 知的なメモリ管理: 静的な割り当てではなく、コンテキスト(文脈)の長さに応じて、Cache(注釈:対話履歴の一時保存領域)をGPUとRAMの間でシームレスに行き来させます。
- レイテンシの極小化: 従来のボトルネックだったPCIeバスの転送速度を、新しいデータ圧縮アルゴリズム(注釈:通信経路でのデータ軽量化)によって克服。RAMを併用しても、文字の出力速度の低下を最小限に抑えています。
NPU(AI専用プロセッサ)の統合
2026年発売のIntel Core UltraやAMD Ryzenプロセッサには、強力なNPU(注釈:AI処理に特化した専用回路)が搭載されています。
- 役割の分担: 重い行列演算はNVIDIA GPUが担当し、背景での継続的なテキスト処理や音声解析はNPUが引き受ける「分業」が確立されました。
- 低消費電力の両立: NPUを主軸に据えることで、バッテリー駆動のモバイル環境でも、高いパフォーマンスを維持しつつ長時間の稼働が可能になっています。
分散推論(Disaggregated Inference)の普及
一台のPCに依存せず、家庭内や社内のネットワークにある複数のデバイスを統合する手法です。
- リソースの共有: メインのデスクトップPCの余ったGPUパワーを、Wi-Fi経由で手元のスマートフォンやタブレットのAIアシスタントが経由して利用します。
- スケーラビリティの確保: 1枚のグラボを買い替えるのではなく、古いマシンを「推論ノード」として追加することで、全体の知能を拡張するフローが一般的になりました。

Stable DiffusionとのGPU共有最適化
要点:文章生成(LLM)と画像生成(Stable Diffusion)をローカル環境で共存させるには、VRAMの「排他制御」と「スワップ戦略」が効率化の決め手となります。
2026年、多くのクリエイターはLLMにプロンプトを考案させ、その指示をそのままStable Diffusion(注釈:オープンソースの画像生成AI)に渡して画像を出力するマルチモーダルなワークフローを構築しています。
しかし、両者を同時に立ち上げると、VRAM(ビデオメモリ)が上限に達し、推論速度が激減、あるいはシステムが不安定になるエラーが発生します。
これを回避するための、プロフェッショナルな管理術を解説します。
VRAMのホットスワップ(動的退避)
100%ローカルな環境でモデルを効率的に回すには、一方のAIが計算している間、もう一方のAIデータをメインメモリ(RAM)やNVMe SSDへ一時的に退避させる手法が有効です。
- ロード時間の短縮: 2026年のエンジニアは、重みデータをキャッシュ(注釈:一度読み込んだデータを高速に取り出せるよう保持する場所)化。LLMから画像生成へ切り替える際の待機時間を秒単位まで短縮しています。
- メモリの使用量管理: DifyやComfyUIといったプラットフォーム上で、使用していないノードのメモリを自動的に解放(VRAM Release)する設定を追加することで、常に余裕を持った稼働を実現します。
量子化によるマルチモデル共存
LLMだけでなく、Stable Diffusionのモデル(CheckpointsやLoRA)自体も量子化することが2026年のトレンドです。
- 知能と表現力の維持: LLMを4bit量子化し、画像生成モデルをint8(8ビット整数)等に圧縮。これにより、24GBのRTX 3090や4090でも、70bクラスの知能と高精細な画像生成を同時に実行するフローが可能になります。
- LoRA(追加学習)の軽量運用: LoRA(注釈:特定の画風やキャラクターを追加学習させる手法)を用いる際も、VRAMの消費を抑えつつ、モデルの品質を保持する最適化が施されています。
LoRAとDreamboothの違いを徹底比較!最適な学習方法と選び方
VRAMの「共有メモリ」設定の落とし穴
Windows 11以降のGeForceドライバには、VRAMが不足した際にシステムメモリを自動で使う機能がありますが、これは注意が必要です。
- ボトルネックの正体: システムメモリにアクセスし始めると、スループット(注釈:単位時間あたりの処理量)が極端に低下します。画像生成に数分かかることもあります。
- 解決策: 手動で上限を決め、VRAM内に収まる軽量なモデル(1b〜3bのSmallモデル等)を補助的なエージェントとして選定することで、高速なレスポンスを維持できます。

エネルギー効率と「静音」構築術
要点:高性能GPUの騒音と電気代を抑えるための、アンダーボルティング(低電圧化)設定が必須スキルです。
aiを長時間稼働(注釈:サーバーのように常に待機させる状態)させると、消費電力と排熱が大きな課題になります。
2026年のエンジニアの間では、あえてgpuの最大電力を80%程度に制限するアンダーボルティングが標準です。
これにより、性能低下を5%未満に抑えつつ、消費電力とファンの騒音を劇的に削減できます。
自宅の寝室にローカルサーバーを置く場合でも、この設定一つで快適な運用が可能になります。
よくある質問と回答(FAQ)
要点:導入時に誰もが直面する疑問に、本質的な回答を提供します。
16GBのRAMでもローカルLLMは動きますか?
はい、動きますがモデルのサイズに強い制約があります。
1b〜3b(10億〜30億パラメータ)の超軽量モデルであれば、16gbのpcでも快適です。
しかし、実用的な知能を求めるなら、pc全体のメモリ(ram)は最低32gb、推奨64gb以上を用意することをおすすめします。
AMD製のGPU(Radeon)でも大丈夫?
2026年現在は、rocm(注釈:amd製gpu向けのソフトウェアプラットフォーム)の普及により、radeonでもローカルllmを動かせます。
ただし、開発コミュニティのライブラリやサポートの厚さは依然としてnvidiaが圧倒的です。
トラブルを避け、最新の恩恵をすぐに受けたいのであれば、nvidia製を選択するのが最も確実な道です。
ノートPCでGPUをフル回転させても大丈夫?
排熱設計がしっかりしたゲーミングノートであれば可能ですが、長時間の連続稼働はパーツの寿命を縮めるリスクがあります。
本格的な運用を考えるなら、冷却効率の高いデスクトップpcを自作するか、ノートpcをクライアント(操作端末)として使い、処理はデスクトップに任せるリモートアクセス環境を構築するのが賢明です。
2026年にあえてローカルで動かす最大の理由は?
利用規約の変更に怯えることなく、機密性の高いデータを気軽にAIへ流し込める安心感にあります。
また、2024年頃のクラウドAPIの遅延(レイテンシ)を考慮すると、手元のハードウェアで完結させる方がレスポンスの値が安定し、作業効率が劇的に高まります。
初心者が最初に購入すべきパーツは?
まずはVRAMが12GB以上のNVIDIA製GPUを確認します。
購入することから始めてみてください。
CPUやマザーボードは後からでも拡張性を活かして更新できますが、GPUのメモリ量だけは、modelが動くかどうかの前提条件となるため、ここを一番重視して選んでください。

まとめ:ローカルAIが拓く新しい未来
要点:GPUを搭載したローカルLLM環境は、もはや贅沢品ではなく、2026年を生き抜くための不可欠なパーソナルインフラです。
本記事では、100%ローカル環境でaiを動かすためのgpu選定から構築ガイドまでを解説しました。
クラウドの制限から解き放たれ、自分だけのプライベートな知能を手に入れることは、情報の安全性だけでなく、あなたの創造性を何倍にも引き上げるきっかけになります。
まずは、無料のオープンソースモデルを一つダウンロードし、自分のgpuが初めて言葉を紡ぎ出す瞬間を体験してみてください。
その衝撃が、あなたのtechライフを大きく変えるはずです。

公式サイト・関連リンク
- NVIDIA CUDA Toolkit 公式ページ
- Ollama – Get up and running with large language models locally
- Hugging Face – The AI community building the future
- LM Studio – Discover and run LLMs on your computer
- Apple Silicon Support for Machine Learning (MLX)