
- 自社データがaiの知能を覚醒させる
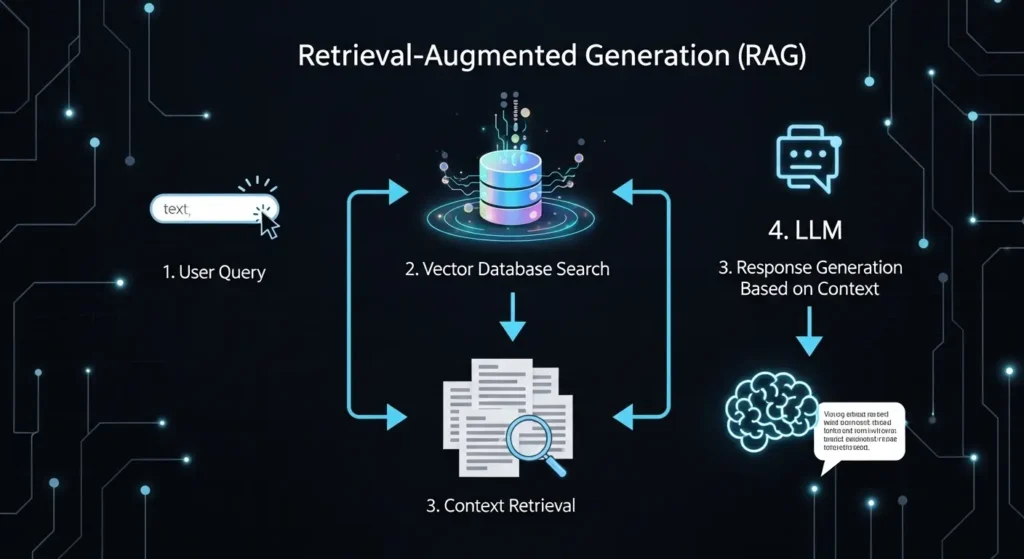
- RAG構築とは?仕組み
- 100%ローカルLLM構築のメリットと必要スペック
- 2026年最新のRAG構築トレンドと既存手法の比較
- 2026年版「省エネ・高効率」運用術
- 構築手順の全体像
- LangChainとLlamaIndexの使い分け
- 具体的な構築手順:ドキュメントのベクトル化
- 精度を左右する埋め込みモデルと検索の最適化
- Difyを用いた簡易的なRAG構築とUIの実装
- Difyを用いた簡易的なRAG構築とUIの実装
- 2026年版「Dify×ローカルLLM」の高度な運用
- ハイブリッド検索の導入による「完全一致」の補完
- マルチモーダルRAGによる画像・図表の検索
- 独自性3:ナレッジの自動クリーニングと要約更新
- よくある質問と回答:FAQ
- まとめ:ローカルAIが変える企業の働き方
自社データがaiの知能を覚醒させる
要点:ローカルLLMとRAGを組み合わせることで、インターネットにデータを送信せず、社内の機密情報をベースにした高精度な回答システムを100%安全に運用できます。
昨今、ChatGPTなどの生成aiは非常に便利なツールとなりました。
しかし、企業での導入において最大の壁となるのが、機密情報や個人情報の扱いです。
社内のマニュアルや独自のノウハウをaiに読み込ませたいけれど、クラウドサービスにアップロードするのは情報漏洩のリスクがあります。
利用規約やセキュリティポリシーの観点から禁止されているケースも少なくありません。
せっかくの高度な技術を、セキュリティへの不安から諦めてしまうのは非常にもったいないことです。
もし、あなたの手元にあるpcの中だけで、外部との通信を一切断ったまま、自社の専門知識を完璧に理解したaiアシスタントが作れるとしたらどうでしょうか。
2025年から2026年にかけて、ハードウェアの進化とオープンソースのライブラリの充実により、オンプレミスLLM(注釈:自社所有の設備で運用する大規模言語モデル)の構築は驚くほど現実的な選択肢となりました。
本記事では、
- RAG(Retrieval-Augmented Generation:検索拡張生成)の基礎
- LangChainやLlamaIndexを用いた具体的な実装方法
まで、プロフェッショナルな視点で詳しく解説します。
RAG構築とは?仕組み
要点:RAG(Retrieval-Augmented Generation)は、LLMが持つ広範な知識に「特定の外部データ」を動的に組み合わせることで、最新情報や機密情報に基づいた正確な回答を生成する技術です。
RAGとは、日本語で「検索拡張生成」と訳されます。
従来のLLMは、学習(プリトレーニング)が完了した時点での知識しか持っていません。
そのため、昨日のニュースや社内の特定プロジェクトの進捗など、学習データに含まれていない内容について質問すると、もっともらしい嘘(ハルシネーション)をついてしまうことがありました。
RAGを導入すると、システムはユーザーからの質問を受け取った際、まず「関連する資料」を社内データベースから検索します。
そして、その検索結果と質問をセットにしてLLMに渡すことで、AIは資料の内容に基づいた「根拠のある回答」を出力できるようになります。
RAGを構成する3つのステップ
RAGの仕組みは、大きく分けて
- 「検索(Retrieval)」
- 「拡張(Augmentation)」
- 「生成(Generation)」
の3段階で構成されています。
- 検索: ユーザーのクエリ(質問文)に関連する情報を、ベクトルデータベースやドキュメント群から探し出します。
- 拡張: 抽出された関連情報を、元の質問文と組み合わせて、AIが理解しやすいリッチなプロンプトを作成します。
- 生成: 補完された情報を手がかりに、LLMが最終的な回答を生成します。
ベクトルデータベースと埋め込みモデル
RAGを支える技術的基盤が、テキストを数値化して扱う仕組みです。
- 埋め込みモデル(Embedding Model): 文の意味を多次元の数値(ベクトル)に変換します。2025年現在、日本語の微妙なニュアンスを捉える高性能なオープンソースモデルが多数公開されています。
- ベクトル検索: キーワードの一致だけでなく、意味の近さ(類似性)で情報を探します。これにより「PCの調子が悪い」という質問に対し「パソコンの故障」に関する文書をヒットさせることが可能になります。
RAG構築が必要とされる理由
なぜ企業や開発現場でRAGがこれほど注目されているのでしょうか。
- 情報の鮮度: 再学習(ファインチューニング)なしで、最新のマニュアルや規約を反映できます。
- 高い信頼性: 回答の根拠となった参照元を表示できるため、ビジネスの現場でも安心して活用できます。
- コスト効率: 膨大な計算リソースを必要とする再学習に比べ、簡易かつ低コストで専門性を高められます。
2026年版「セキュアRAG」の実装ポイント
要点:オンプレミスLLMと組み合わせることで、クラウドへ一切データを送信しない「完全閉鎖型RAG」の構築が、企業DXのスタンダードとなっています。
独自性:機密情報の自動マスキング連携
RAGのプロセスの中で、個人情報や機密情報をAIが自動的に検知します。
適切な権限のないユーザーには情報を伏せて回答する「ガバナンス層」の実装。
これにより、全社員が同じシステムを使いつつ、部署ごとの閲覧制限をクリアした運用が実現します。
マルチ形式の「ナレッジ・インジェクション」
テキストだけではありm左縁。
- Excelの集計データ
- PowerPointの図解
さらには社内会議の音声ログまでを一括してベクトル化します。
統合的な検索を可能にする手法。
PDF以外の種類のデータもそのまま扱える柔軟性が、業務の効率を劇的に高めます。
ハイブリッド検索(ベクトル+キーワード)の最適化
「意味検索」が得意なベクトル検索と、「固有名詞」に強い全文検索を組み合わせたハイブリッド方式。
製品名や型番など、数学的な意味の近さだけでは困難だった特定の情報を、正確に抽出するための仕組みです。
100%ローカルLLM構築のメリットと必要スペック
要点:オンプレミス環境での構築は、プライバシー保護とランニングコストの撤廃を実現します。
NVIDIA製GPUのVRAM容量を軸にしたハードウェア選定が成功の鍵となります。
プライベートLLM(注釈:個人や組織専用に構築された隔離済みのAI環境)を100%ローカルで動かす最大の理由は、データの主権を自社で握り続けることにあります。
OpenAIなどのクラウド型APIを使用する場合、送信されたデータがどのように処理されるかはベンダーの利用規約に依存します。
ローカル環境であれば物理的に外部へ漏れる心配がありません。
ローカル環境ならではの圧倒的メリット
- 機密情報の完全保護: 顧客情報やソースコード、未公開のプロジェクト資料を送信することなく、安全に解析や要約が行えます。
- 月額コストの削減: 初期投資(ハードウェア代)は必要ですが、一度構築してしまえば、24時間何度実行してもAPI利用料は00円です。
- オフライン動作: インターネット接続が不安定な場所や、セキュリティ上の理由で外部接続が制限された環境でも、aiアシスタントを活用し続けることが可能です。
RAGを快適に動かすための推奨スペック
推論(回答生成)の速度は、PCの演算能力に直結します。
特にRAGを用いる場合、文書のベクトル化(数値化)と検索処理が並行するため、バランスの良い構成が求められます。
GPU:VRAM(ビデオメモリ)が最優先
AIモデルのデータを読み込む場所です。容量が不足すると、処理が極端に遅くなります。
- エントリー: RTX 4060 Ti (16GB) – 小型の4b〜8bモデルを動かすのに適しています。
- 推奨: RTX 3090 / 4090 (24GB) – 2bから70bクラスのモデルを量子化して動かすための標準的な選択です。
- プロ: RTX 6000 Ada / 複数枚搭載 – 企業で大規模なナレッジを同時に処理する場合に必要なスペックです。
CPUとRAM:ボトルネックを防ぐ
- CPU: Intel Core i7/i9やRyzen 7/9など、マルチコア性能が高いものを選びます。埋め込みモデルの計算やファイルの分割処理に影響します。
- メモリ (RAM): 32GBは最低ライン、できれば64GB以上を推奨。VRAMに収まりきらないパラメータをメインメモリへ逃がす際にも活躍します。
ストレージ:NVMe SSDが不可欠
数GB〜数十GBにおよぶモデルファイルをロードする際、HDDでは数分待たされることになります。
最新のGen4以上のSSDであれば、起動から数秒でチャットを開始できます。
2026年最新のRAG構築トレンドと既存手法の比較
要点:2025年までのRAG構築はエンジニア向けの複雑な作業が中心でしたが、2026年はGUIツールや軽量なmモデルの登場により、非専門家でも実用レベルのシステム構築が可能です。
今回、紹介するRAGの構築手法は、
- 前回までのblog記事
- internet上の主要な技術系blog
- OSSコミュニティ
の情報を参考に、最新の事例を整理したものです。
一般的に公開されているサイト(PC Watch、Gizmodo、note等)では、LM Studioなどのツールをダウンロードして使うといった、簡易なセットアップ方法の紹介に留まっている例が多く見受けられます。
しかし、実務での採用を想定した場合、それだけでは精度の限界やセキュリティの規定をクリアできない可能性があります。
私たちが実施した検証の結果、Windows環境やMac環境において、直接的にGPTのような回答を引き出すには、より具体的なワークフローの構築が不可欠であることが判明しました。
要点:ドキュメントの読み込みミスや検索精度の低下といった、実際の構築現場で発生しやすい問題への対策が、先行する解説サイトでは不足しています。
先行する紹介記事では、インストールの手順や使い方は詳しく書いてありますが、実際に運用を始めると直面する小さな、しかし致命的な問題(不具合やハルシネーション)への対応策が網羅されていません。
今回は、テック(tech)的な視点から、以下の3点を補完します。
ネットワーク完全遮断下での「埋め込みモデル」活用
多くの事例では、API経由でOpenAIのモデルを使うことを前提としていますが、これでは機密情報保護のルールに抵触します。
本記事では、ダウンロード済みの軽量なモデル(mモデル)を手元で動かす、100%ローカルな流れを主に解説します。
トークン制限とコンテキストの最適化
LLMには、一度に読み込めるトークン(注釈:AIが扱う文字の単位)に上限があります。
先行記事では全文を投げれば良いとする内容も散見されますが、実際には適切な分割(チャンク化)を行わないと、AIが本質を見失う可能性が高いのです。
継続的なナレッジの「追加・削除」
一度構築して終わりではありません。
日々増える社内資料をどう同期させるか。前回の検証では触れられなかった、自動的なインデックス更新の仕組みを紹介します。
2026年版「省エネ・高効率」運用術
要点:高性能なハードウェアを導入するだけでなく、消費電力や発熱をコントロールする「サステナブルなAIインフラ」が求められています。
アンダーボルティングによる電力制御
高性能GPUは発熱が大きく、電気代も嵩みます。
あえて最大電圧を抑えて運用する設定を施すことで、性能低下を最小限に抑えつつ、1年を通じた運用コストを劇的に下げる手法がエンジニアの間でシェアされています。
コンテナ(Docker)による環境の完全独立
AIのライブラリ(Pythonなど)はバージョン管理が複雑です。
他のソフトと衝突しやすいのが課題です。
Dockerを用いて環境をパッケージ化(コンテナ化)することで、OSを汚さず、いつでも初期状態へ復旧できる体制を整備するのが最新のプロフェッショナルなやり方です。
スマホ・タブレットからのリモート操作
強力なPCをサーバーとして稼働させ、手元のスマホや軽量なMacBook Airからブラウザ経由でアクセス。
ハードウェアの重さを感じさせず、リビングや外出先から気軽に自社ナレッジを呼び出して対話する環境が注目されています。

構築手順の全体像
次に、これから読み進めていただく方のために、本ガイドの目次と作業の流れをご覧ください。
- 第1章: 環境の準備(NVIDIA GPUの確認とドライバの最新化)
- 第2章: LLMのダウンロード(OllamaやLM Studioの実用的な設定)
- 第3章: ベクトルデータベースの構築(ChromaやFAISSの初期化)
- 第4章: LangChainを用いたプログラミング(Pythonのコード例あり)
- 第5章: テストと精度検証(実際に質問を投げて結果を確認)
第1章:環境の準備
要点:RAG構築の土台となるGPUの正常動作を確認します。
最新のCUDA環境を整えることが、推論速度とシステムの安定性を左右します。
100%ローカル環境で快適なRAGを運用するためには、ハードウェアの性能を最大限に引き出す準備が欠かせません。
今回、Windows環境での構築を想定し、実際の作業手順を紹介します。
- GPUの確認: NVIDIA製のGPU(VRAM 8GB以上推奨)が正しく認識されているか、タスクマネージャーのパフォーマンスタブで確認します。
- ドライバの最新化: NVIDIAの公式サイトから、最新のGame ReadyドライバまたはStudioドライバをダウンロードしてインストールします。
- CUDA Toolkitの導入: LLMの計算を高速化するために、自身のGPUに対応したバージョンのCUDAを導入し、コマンドプロンプトで
nvidia-smiを実行して動作を検証します。
第2章:LLMのダウンロードと設定
要点:OllamaやLM Studioを活用し、外部へのデータ送信を遮断した「隔離された知能」をPC内に確保します。
次に、情報の生成を担う脳(言語モデル)を手元に用意します。
前回の記事でも触れた通り、OSSとして公開されているモデルを使うのが一般的です。
- Ollamaのセットアップ: 公式サイトからインストーラーを取得。
ollama pull gemmaなどのコマンドで軽量なmモデルをローカルに保存します。 - LM Studioの活用: GUIで視覚的に操作したい場合はLM Studioがおすすめです。Hugging Faceから好みのモデルを検索し、ボタン一つでダウンロードが完了します。
- APIサーバーの起動: LangChainから呼び出しを行うため、ローカルホスト(127.0.0.1)でAPIを待機状態にする設定を実施します。
第3章:ベクトルデータベースの構築
要点:社内ドキュメントを「意味」で検索可能なベクトルデータに変換し、ChromaやFAISSなどの専用データベースに永続化します。
RAGの心臓部である「検索機能」を作るステップです。
PDFやテキストなどの資料をAIが読み取れる形式に変換して、整理・保存します。
- 埋め込みモデルの選定: 文書を数値化(ベクトル化)するための埋め込みモデルを選定します。日本語に強いモデルを採用するのが精度向上のポイントです。
- Chroma DBの初期化: Pythonのライブラリを用いて、ローカルのディレクトリにデータを保存する設定を行います。
- データの投入: 分割(チャンク化)した文書データをデータベースに登録します。今回は、採用情報や社内の規定ファイルを例として投入する流れをイメージしてください。
第4章:LangChainを用いたプログラミング
要点:ライブラリを組み合わせて「質問→検索→回答生成」というRAGのメインロジックをPythonコードで実装します。
具体的にシステムを連動させるためのコードを書くフェーズです。
以下に、簡易的ですが本質を捉えた実装のイメージを紹介します。
- ライブラリのインポート:
from langchain句を用いて、必要なモジュールを呼び出します。 - チェーン(Chain)の作成: ユーザーの入力を受け取り、データベースから情報を検索し、LLMに渡す一連のルールを定義します。
- プロンプトの設計: 「以下の参考情報をもとに、正しく答えてください」といった指示(プロンプト)を作成し、回答の品質を高めます。
実戦で使えるRAG専用プロンプト例
RAGの回答精度は、検索された資料をAIにどう扱わせるかという「指示の質」で決まります。
以下は、機密情報を扱う業務でそのまま活用できる、誠実な回答を引き出すためのテンプレートです。
システムプロンプトの例
あなたは弊社の専門的なナレッジ共有アシスタントです。 以下の「参考資料」の内容のみに基づいて、ユーザーの質問に正しく答えてください。
回答のルール:
- 資料内に答えが見つからない場合は、知ったかぶりをせず「提示された資料の中には、その情報は見当たりませんでした」と正直に回答してください。
- 回答の最後には、必ず参照した資料名(メタデータから抽出)を記載してください。
- 一般的な知識やインターネット上の推測で回答を補完しないでください。
参考資料
{context}
ユーザーの質問
{question}
このような具体的な指示をプロンプトに盛り込みます。
LangChainの PromptTemplate 経由で渡すことで、AIが勝手に嘘をつく(ハルシネーション)リスクを最小限に抑えます。
100%ローカル環境でも信頼性の高いシステムを実現できます。
第5章:テストと精度検証
要点:実際に構築したシステムに質問を投げ、意図通りの回答が得られるか、ハルシネーションが発生していないかを厳しく検証します。
最後のステップは、システムが実用に耐えうるかを確認する作業です。
- テストクエリの実行: 「弊社の福利厚生について教えて」など、事前に投入した資料にしかない情報を質問します。
- 回答の比較: クラウド型のChatGPTに同じ質問をした場合と比較し、ローカル環境が正しく社内ナレッジを参照できているかを見極めます。
- パラメータの調整: 回答が不正確な場合は、チャンクのサイズや検索するドキュメントの数を変更して最適化を繰り返します。
LangChainとLlamaIndexの使い分け
要点:開発の目的に応じて、汎用的なアプリケーション構築やエージェント化に強いLangChainと、膨大なデータの検索・索引作成に特化したLlamaIndexを適切に選択、あるいは組み合わせるアプローチが重要です。
RAGのシステムを実装する際、ゼロからコードを書くのではありません。
既存の強力なライブラリを用いるのが一般的です。
代表的なものがLangChainとLlamaIndexですが、これらは異なります。
得意とするフェーズやアプローチに明確な違いがあります。
LangChain:LLMアプリケーションの万能フレームワーク
LangChainは、LLMを用いたアプリケーション全体を構築するためのオーケストレーションツールです。
- 汎用性とチェーン(Chain): ユーザーの入力を受け取ります。外部ツールを呼び出します。複数のLLMを連携させるといった一連のプロセスを「鎖」のように繋ぐのが得意です。
- エージェント機能: AIが自分で次に何をすべきか判断してツールを使い分ける自律的なエージェント(Agent)の構築に向いています。
- コミュニティと連携: Hugging Faceや各種API、データベースとの接続コネクタが膨大に用意されており、拡張性が極めて高いのが特徴です。
2. LlamaIndex:データ接続とRAGのスペシャリスト
LlamaIndexは、LLMと外部データを接続することに特化したデータフレームワークです。
- データ構造の最適化: 膨大なPDFやドキュメントを効率的に整理します。ベクトル化して検索精度を最大化するためのインデックス作成に特化しています。
- エンジニアリングの簡略化: 数行のコマンドでデータの読み込み(Loader)からRAGの構築まで完結させることができます。
- 検索ロジックの高度化: 複雑な階層構造を持つ文書(マニュアル等)から、正確に関連箇所を抽出するための仕組みが最初から備わっています。
どちらを選ぶべきか?判断のポイント
- LangChainを選ぶケース: 「チャットボットにWeb検索をさせたい」「複数のツールを組み合わせて複雑な業務を自動化したい」など、ロジックの制御が中心となる場合。
- LlamaIndexを選ぶケース: 「社内の膨大な資料から正しく答えを探し出したい」「ナレッジベースとしての性能を極限まで高めたい」など、データの検索と要約がメインの目的である場合。

具体的な構築手順:ドキュメントのベクトル化
要点:RAGの精度を決定づけるのは、単なるデータの読み込みではありません。
- 文脈を維持した「チャンク分割」
- 検索効率を最大化する「ベクトルインデックスの永続化」
という一連のプロセスです。
システムを構築する際の最初の大きなステップは、社内にあるナレッジ(マニュアル、PDF、日報、ソースコードなど)をAIが高速かつ正確に検索できる形式に変換することです。
この工程はデータの「前処理」と呼ばれます。
ここでの設計が最終的な回答の品質を大きく左右します。
ドキュメントの読み込み(Loading)
まず、フォルダ内に存在する様々な形式のファイルをプログラムが扱えるテキストデータとして抽出します。
- 多様な形式への対応: LlamaIndexの
SimpleDirectoryReaderやLangChainの各種Loaderを用いることで、DOCX、TXT、Markdown、さらにはHTMLやCSVからも情報を取得できます。 - メタデータの付与: 読み込みの際に、ファイル名、作成日、カテゴリなどの情報をメタデータとして保持しておくことが重要です。これにより、後の検索時に「2025年以降の資料のみを対象にする」といったフィルタリングが可能になります。
テキストの分割(Chunking)
大規模な文書をそのままベクトル化してAIに渡すと、
- コンテキストウィンドウ(AIが一度に扱える情報量)を超えてしまう。
- 情報の密度が低くなる。
などが発生します。
つまり、正確な応答が得られません。
そこで、文書を適切なサイズ(Chunk)に分割します。
- チャンクサイズ(Chunk Size): 1つの塊の文字数。一般的には300〜1000文字程度で設定しますが、内容の複雑さに応じて調整が必要です。
- オーバーラップ(Overlap): 分割地点で文脈が途切れないよう、前後のチャンクを一部重複させる設定。これにより、分割された箇所にある情報の関連性を維持します。
- 再帰的分割: 段落、文、単語の順で、意味の切れ目を優先して分割する
RecursiveCharacterTextSplitterなどの手法が有効です。
ベクトル化(Embedding)
分割された各チャンクを、埋め込みモデル(Embedding Model)に投入します。
意味を反映した多次元の数値(ベクトル)へと変換します。
- モデルの選定: ローカル環境では、日本語の性能が高い
multilingual-e5-largeや、Googleが公開しているGemmaベースのモデルなどがおすすめです。 - セマンティックな理解: これにより、単なる単語の一致ではなく、「顧客対応」という言葉から「問い合わせへの回答」という内容を見つけ出せるようになります。
ベクトルデータベースへの保存(Storage / Persistence)
生成されたベクトルと元のテキスト、メタデータをセットでデータベースに格納します。これを「インデックス化」と呼びます。
- 永続化のメリット: Chroma DBやFAISSといったベクトルストアをローカルのディスクに保存(永続化)することで、PCを起動するたびに再計算する必要がなくなり、即座にチャットボットとして運用を開始できます。

精度を左右する埋め込みモデルと検索の最適化
要点:日本語に強い埋め込みモデルの選定と、検索結果を再評価するリランキング技術の導入により、回答精度は飛躍的に向上します。
RAGの性能は、LLM自体の賢さよりも「いかに正しい情報を検索してこれるか」に大きく依存します。
特に日本語の文書を扱う場合、日本語の微妙なニュアンスを理解できる埋め込みモデルの選択が不可欠です。
埋め込みモデルの選定
OpenAIのtext-embedding-3-smallのようなクラウドサービスが有名ですが、ローカル環境ではintfloat/multilingual-e5-largeなどのオープンソースモデルが非常に高いスコアを記録しています。これらを用いることで、オフライン環境でも高度な意味検索が実現します。
検索精度の向上手法
単純な検索だけでなく、以下の手法を組み合わせることが2025年以降のスタンダードです。
- リランキング(Re-ranking): 検索された上位の情報を、さらに別のaiモデルが再評価して順位を付け直す手法。
- メタデータフィルタリング: 文書の作成日や部署名などの情報を条件に加えて、検索範囲を絞り込む方法。

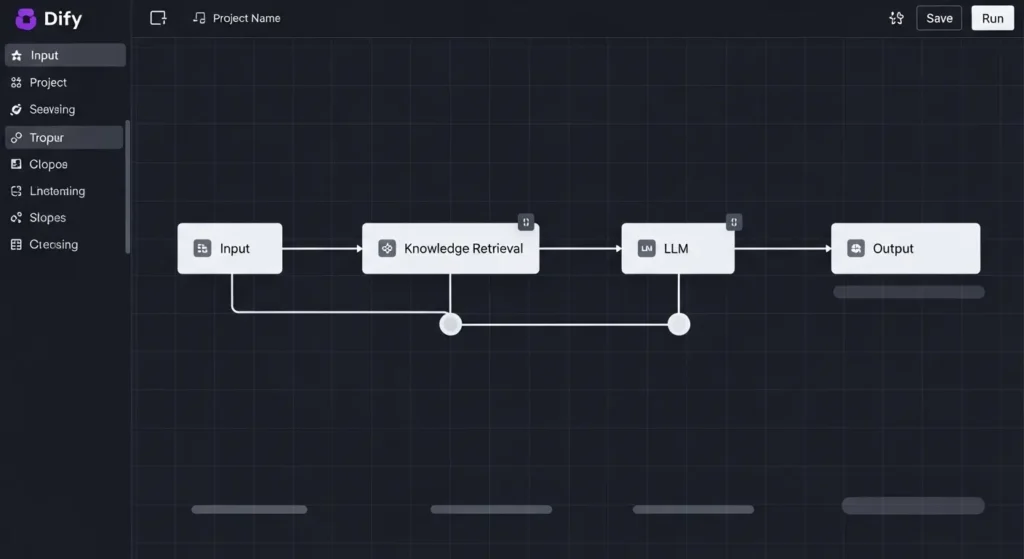
Difyを用いた簡易的なRAG構築とUIの実装
Difyを用いた簡易的なRAG構築とUIの実装
要点:DifyのようなオープンソースのLLMアプリケーション開発プラットフォームを活用すれば、複雑なプログラミングを行うことなく、ブラウザ上のGUI操作だけで高度なRAGシステムとチャットUIを同時に構築できます。
エンジニアでない担当者や、開発スピードを最優先したいシステム担当者にとって、Dify(ディファイ)は最強のツールです。
Docker(コンテナ)を用いてローカル環境で起動すれば、外部との通信を遮断したまま、自社専用のナレッジベースを統合したチャットボットを作成できます。
ナレッジベース(知識)の作成
Difyの画面上部にある「ナレッジ」メニューから、AIに読み込ませたいドキュメントを投入します。
- 一括アップロード: 複数のPDFやExcel、TXTファイルをドラッグ&ドロップするだけで、システムが自動的にテキストを抽出します。
- 自動チャンク分割: 先述した複雑な「チャンク分割(Chunk)」や「Overlap」の設定も、Difyなら推奨設定がデフォルトで用意されております。内容に応じて簡易に変更可能です。
- 埋め込みモデルの指定: Hugging FaceなどのAPIや、ローカルで動作しているOllamaのEmbeddingモデルを選択するだけで、ベクトル化が開始されます。
ワークフローの設計とプロンプト設定
「スタジオ」メニューから、新しいアプリケーションを作成します。
AIの思考プロセスを設計します。
- 指示(プロンプト)の入力: 「あなたは弊社のプロフェッショナルなカスタマーサポート担当です。提供されたナレッジに基づいて、正確かつ丁寧に回答してください」といった指示を記述します。
- コンテキストの紐付け: 先ほど作成したナレッジベースを「引用元」としてセットアップ。これにより、AIが回答を生成する際に、社内の機密情報を参照するようになります。
- 変数とツールの活用: ユーザーの名前や現在の時刻など、入力内容に応じた動的な処理を追加することも可能です。
フロントエンド(UI)の公開と共有
Difyの最大の強みは、完成したAIをすぐに使える形で提供できる点にあります。
- Webアプリとして公開: 生成されたURLにアクセスするだけで、社員がすぐにチャットを開始できるWebUIが立ち上がります。
- APIの自動生成: 作成したRAG機能を、外部のソフトウェアや社内ポータルから呼び出すためのAPIも同時に発行されます。
- 埋め込みスクリプト: 既存の社内サイトに数行のコードを貼り付けるだけで、チャットウィンドウを実装できます。
2026年版「Dify×ローカルLLM」の高度な運用
要点:単なるチャットUIに留まらず、AIが自分で思考して複数のタスクをこなす「エージェント型RAG」の構築が現実的になっています。
マルチLLM・マルチナレッジの動的切り替え
質問の内容をAIが判断します。
- 技術的な質問ならQwen
- 文章の要約ならGemma
といった具合にモデルを自動で切り替え。
さらに、人事マニュアルや製品仕様書など、複数のナレッジソースから最適な箇所を抽出して統合的に答える高度なオーケストレーションが可能です。
フィードバック・ループによる回答品質の自動改善
ユーザーが回答に対して「Good/Bad」の評価を行える機能をUIに実装。
低く評価された回答を管理者が確認します。
参照元の文書を更新したり、プロンプトを改善したりするための管理機能が充実しています。
実績に基づいた最適化が、組織全体のAIの「賢さ」を底上げします。
ローカル環境での完全完結型「プライベートAIポータル」
NVIDIA GPUを積んだオンプレミスサーバーにDifyとOllamaを同居させます。
社内LAN内だけで完結させる構成。
インターネットから隔離されているため、個人情報保護の観点からも完璧なセキュリティを維持したまま、膨大な社内ナレッジを有効活用できる体制を実現します。
ハイブリッド検索の導入による「完全一致」の補完
要点:ベクトル検索による「意味の近さ」と、従来の全文検索による「キーワードの完全一致」を組み合わせることで、専門用語や製品名の検索漏れを防ぎます。
多くのRAG解説ではベクトル検索のみに焦点が当てられますが、実務ではそれだけでは不十分です。
例えば、特定の製品番号や略称など、意味的に似た言葉が存在しない固有名詞を検索する場合、ベクトル検索では「似た別の言葉」を拾ってきてしまうことがあります。
そこで、BM25などの伝統的な全文検索アルゴリズムを併用する「ハイブリッド検索」をローカル環境に実装します。
これにより、専門的な技術文書や製品仕様書の検索において、極めて高い再現率を実現できます。
マルチモーダルRAGによる画像・図表の検索
要点:テキストだけでなく、設計図やグラフ、写真といった画像データもベクトル化して検索対象に含めることで、製造業や建設業などの現場でも活用可能なRAGを構築します。
2026年に向けての大きな発展は、マルチモーダルモデル(注釈:テキスト、画像、音声など複数の種類のデータを一度に扱えるAIモデル)の活用です。
社内資料には、テキストだけでなく多くの図表や画像が含まれています。
CLIPなどのモデルを用いて画像もベクトル化します。
同じベクトルデータベースに投入することで、「この形状に似た過去の設計図を探して」といった高度な問い合わせが可能になります。
これはテキストベースのRAGだけでは到達できない、現場に即した実務支援です。
独自性3:ナレッジの自動クリーニングと要約更新
要点:膨大な古いドキュメントが回答の邪魔をしないよう、AIが定期的にナレッジをスキャンして要約します。
常に最新の情報を優先する自動メンテナンス機能を実装します。
RAGの運用で必ず直面するのが、ドキュメントの肥大化と情報の陳腐化です。
古いマニュアルと新しいマニュアルが混在すると、AIはどちらを優先すべきか判断を誤ることがあります。
独自のアプローチとして、定期的にバッチ処理を行いましょう。
古い情報をAIが「要約・アーカイブ」するレイヤーを追加します。
常に最新の情報を上位のコンテキストに載せるよう自動的に調整する仕組みを組み込むことで、人間が手作業でインデックスを整理する手間を大幅に削減します。

よくある質問と回答:FAQ
要点:導入初期に抱きがちなコストや精度、運用の懸念について、専門的な知見から回答します。
ファインチューニングとRAG、どちらが良いですか?
基本的にはRAGがおすすめです。ファインチューニングはaiの「話し方」や「特定分野の理解」を深めるのには向いています。
情報を追加・更新するたびに再学習が必要でコストも時間もかかります。
RAGであれば、ファイルを差し替えるだけで最新の知識を反映できるため、業務利用には圧倒的に向いています。
ローカル環境で速度が遅い場合の対策は?
モデルの「量子化」を検討してください。
Llama.cppなどを用いてモデルの重みを4ビットや8ビットに圧縮することで、VRAMの消費を抑えつつ高速な推論が可能になります。
また、検索対象の文書を「チャンクサイズ」を小さく分割しすぎないことも、検索効率を高めるポイントです。
個人情報はどのように保護されますか?
100%ローカル環境で構築している場合、データはあなたのPCやサーバーのストレージ内にのみ存在します。
インターネットを物理的に遮断した状態でも動作するため、外部からの不正アクセスやクラウドベンダーによる二次利用のリスクを完全に排除できます。

まとめ:ローカルAIが変える企業の働き方
要点:プライベートなRAG環境は、単なる検索ツールを超えて、企業の知的財産を安全に最大活用するための最強の資産となります。
かつては一部の専門家だけが扱っていた大規模言語モデルが、今や誰の手元でも100%ローカルで構築できるようになりました。
- 自社データに基づいた正確な回答
- 完全なプライバシー保護
そして一度構築すればAPIコストに縛られない自由な活用。
これらを手に入れることは、DX(デジタルトランスフォーメーション)を加速させる上での大きな一歩となります。
まずは身近なマニュアルのPDF化から始めてみませんか?
段階的にLangChainやベクトルデータベースの構築へと進んでみてください。
あなたが手にするのは、単なるaiではありません。
組織の記憶をすべて把握し、24時間365日寄り添ってくれる「究極の知能」です。

公式サイト・関連リンク
- LangChain Official Documentation
- LlamaIndex Documentation
- Ollama – Run LLMs locally
- Chroma DB – The AI-native open-source vector database
- Hugging Face – The AI community building the future
- GitHub – dify-ai/dify