
「Stable Diffusionで、自分だけのオリジナルキャラクターや絵柄を生成したい!」
そう思っているAI初心者の方は多いでしょう。
その夢を実現する最も効率的な方法が、LoRA(Low-Rank Adaptation)学習です。
LoRAは、大規模なAIモデルの性能を維持しつつ、極めて少ない教師データとリソースで特定のスタイルや特徴を学習させる画期的な手法です。
しかし、
- 「環境構築が難しい」
- 「パラメータが複雑で失敗した」
という声も少なくありません。
今回の記事は、Windows PC、Mac PC、そしてクラウド環境を使うすべてのユーザー層(AIエンジニア、研究者、学生、個人開発者、画像生成AI利用者)に向けた、2025年最新トレンドに対応したLoRA 学習方法の完全ガイドです。
- 基本の知識
- sd-scriptsを使った具体的な手順
- 最適なパラメータ設定
そしてよくある質問やトラブル対処法まで、すべてを網羅しています。
この記事を読めば、あなたも高品質なLoRAを自作し、収益化の道を開くことが可能になります。
さあ、自由な画像生成の世界へ踏み出しましょう。
Stable DiffusionとLoRAの基本知識
Stable Diffusionとは
Stable Diffusion(ステーブル ディフュージョン)は、MidjourneyやDALL-Eと並ぶ、AI画像生成の分野で最も有名なモデルの一つです。
特徴は、無料かつオープンソースで公開されている点です。
ローカル環境(自分のPC)やクラウド環境で誰でも自由に利用できることです。
ユーザーが入力したテキスト(プロンプト)に基づき、数秒で高品質な画像を生成することが可能です。
基本となる大規模なベースモデル(例: SD1.5、SDXL)は、膨大なデータセットを学習しています。
様々な画風やコンセプトに対応しています。
Stable Diffusionをスマホで使う方法!無料でAIイラストを作成する初心者向けガイド
LoRAとは
LoRA(Low-Rank Adaptation:低ランク適応)は、既存の大規模なAIモデル(Stable Diffusionのunetなど)を効率的にファインチューニング(微調整)するための手法です。
従来の学習方法(例: Dreambooth)がモデル全体を変更します。
大きなファイルサイズ(数GB)になります。
対して、LoRAはモデルの重みの差分(アダプテーション)のみを学習します。
これにより、LoRAファイルサイズは数MBから数百MB程度に抑えられます。
VRAM容量の少ないPCでも高速に学習・利用可能となります。
- 特定のキャラクター
- 服装
- ポーズ
- 絵柄
などを追加で覚えさせる目的で使われます。
AI画像生成の効率と自由度を大幅に向上させました。
(注釈: ファインチューニング:既に学習済みのAIモデルに対し、特定のデータセットを使って追加学習を行い、用途に応じて性能を微調整すること。)
Stable Diffusion Web UIの推奨環境
LoRAを利用するだけでなく、学習を実行する場合は、PCのスペック、特にGPUとVRAMが非常に重要です。
| 環境 | 推奨スペック(学習実行用) | 備考(2025年最新トレンド) |
| OS | Windows 10/11、Linux | Macやスマホは実行環境としては厳しいいため、Colabなどのクラウド利用を推奨します。 |
| GPU | NVIDIA RTX 3060 12GB VRAM 以上 | LoRA 学習には最低8GB VRAMが必要ですが、SDXLや高品質な学習には16GB 以上が理想。ゲーミングPCが向いています。 |
| メモリ | 16GB 以上(32GB 推奨) | |
| ストレージ | SSD 256GB 以上(学習データ保存に余裕があること) |
もしVRAM不足で学習が困難な場合、クラウドサービス(例: Google Colab、RunPodなど)の利用をおすすめします。高性能なGPUを必要な時間だけ借りることが可能です。
Stable Diffusion Colab完全ガイド|無料かつ高速なAI画像生成方法
LoRA学習 環境構築と準備
LoRA学習の環境構築
LoRAの学習には、現在、Kohya’s sd-scripts(コウヤズ エスディー スクリプツ)を使うのが一般的であり、最も高い精度と多機能を提供します。
主な手順は以下の通りです。
- PythonとGitのインストール
- sd-scriptsのダウンロード(Git Clone)
- 仮想環境(venv)の作成とライブラリのインストール
- Accelerate configの設定
(サイト外リンク1)
Python 公式サイト:https://www.python.org/ (サイト外リンク2)
Git 公式サイト:https://git-scm.com/
LoRA学習の環境構築
sd-scriptsを使った学習環境の構築は、以下のステップで行います。
venv環境の作成とライブラリの準備
sd-scriptsの導入は、依存関係の問題を避けるため、venv(仮想環境)内で_行う_のが推奨です。
- GitHubからsd-scriptsリポジトリをクローンします。
git clone https://github.com/kohya-ss/sd-scripts.git - フォルダに移動。venv環境を作成・起動します。
cd sd-scriptspython -m venv venv.\venv\Scripts\activate(Windowsの場合) - 必須ライブラリをインストールします。
pip install -r requirements.txtさらに学習に必要なPyTorch(torch)やbitsandbytesなどのライブラリをインストールします。GPUに応じたCUDAバージョンを選ぶことが重要です。 (2025年現在、最新版のsd-scriptsではインストーラやbat/sh ファイルで簡単に導入できる方法も提供されています。)
accelerate configの設定
学習の実行環境(GPUの数やVRAM)を適切に設定するために必要な手順です。
accelerate config とコマンドプロンプトで実行します。
多くの場合、「Does this script run on a single machine?」にYes、「Do you want to use DeepSpeed?」にNoを選ぶ程度で大丈夫です。
ファイルを格納するディレクトリの準備
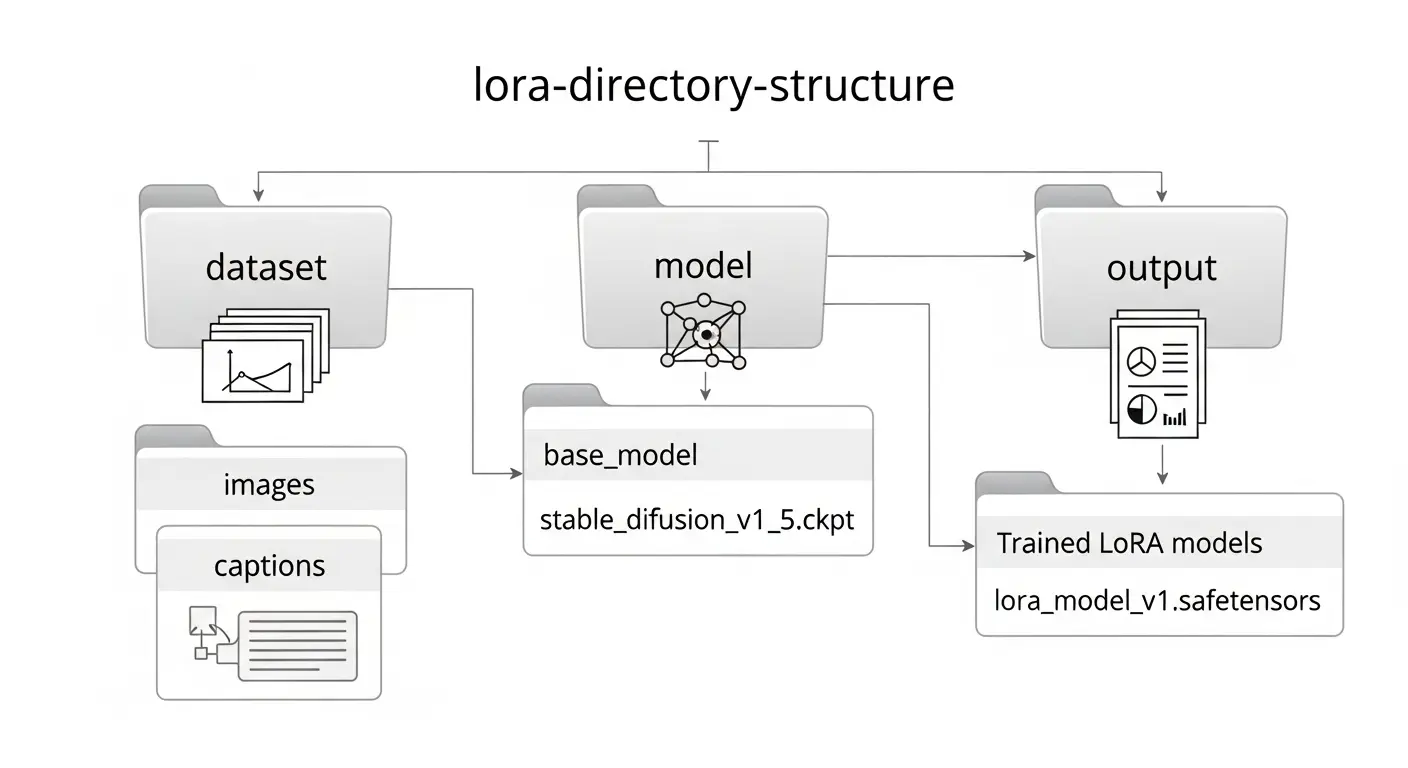
学習をスムーズに行うために、以下のようなディレクトリ(フォルダ)構成を事前に作っておきます。
/LoRA_Training_Project
├── /dataset <-- 教師画像ファイルを入れる
│ └── /10_my_character <-- [繰り返し回数]_[任意の名前]
├── /model <-- ベースモデル (Checkpoint) を入れる
├── /output <-- 学習結果のLoRAファイルが出力される
└── /sd-scripts <-- sd-scriptsが入ったフォルダ
LoRA学習に使用する教師データの準備
LoRAの品質を決める最も重要な要素が、教師データ(画像ファイル)です。
教師画像の収集と枚数
画像生成AI初心者が最も失敗しやすいポイントの一つが、教師データの準備です。
| 項目 | 推奨される設定 | 解説 |
| 枚数 | 最低20枚〜30枚 | 特定のキャラクターや服装なら10枚程度でも可能な場合もあります。多いに越したことはないですが、品質が優先です。(内部リンク推奨: Stable Diffusion 学習 データセット作成ガイド) |
| 解像度 | 512×512 または 768×768 推奨 | ベースモデルに応じて解像度を選定します。SDXLの場合は1024×1024を推奨。 |
| 品質 | 高品質で一貫性があること | 背景やポーズがバラバラすぎると過学習や意図しない結果になる可能性があります。 |
教師データのタグ付けとキャプション作成
stable-diffusion-webui-wd14-taggerの利用
教師データの画像に対し、適切なキャプション(タグ)を付与することがLoRAの精度を決める重要なステップです。
タグが不十分だと、AIが「何を学習すればいいか」を正確に認識できず、失敗の原因となります。
wd14-taggerは、画像を自動で解析します。
関連するタグ(髪型、服装、表情、背景など)をテキストファイル(.txt)として出力してくれる拡張機能です。
キャプションの作成
- Stable Diffusion Web UI(AUTOMATIC1111版やForge版など)を導入している場合、拡張機能タブからwd14-taggerをインストールします。
- tagger タブで教師画像フォルダを指定し、実行します。画像ファイルと同じ名前のテキストファイルが自動で作成されます。
キャプションの編集
自動作成されたキャプションファイル(.txt)を開いて、以下の編集を行います。
- トリガープロンプトの追加: AIに「このLoRAを使え」と指示するための特定の単語を追加します。(例: mychara、lora_nameなど)。先頭に書くことが一般的です。
- 学習させたくない特徴の削除: 例: 背景の色(white backgroundなど)、不要なポーズや服装など、LoRAに覚えさせたくない要素は削除します。

LoRA 学習パラメータ設定と実行
LoRA学習パラメータ徹底解説
sd-scriptsの学習は、コマンドライン(CLI)実行またはGUI(Gradioを使ったインターフェース)から行います。
初心者にはGUIの利用を強くおすすめします。
datasetconfigファイルとAccelerateファイルの作成
GUIを使わない場合、学習の各種設定を記述した設定ファイル(JSONやTOML形式)を作成する必要があります。
- datasetconfigファイル: 教師データのパス、解像度、繰り返し回数(repeats)、バケット(bucket)設定などを記述します。
- Accelerateファイル: GPUの設定(mixed precisionなど)を記述します。accelerate configで作成した設定を読み込む形です。
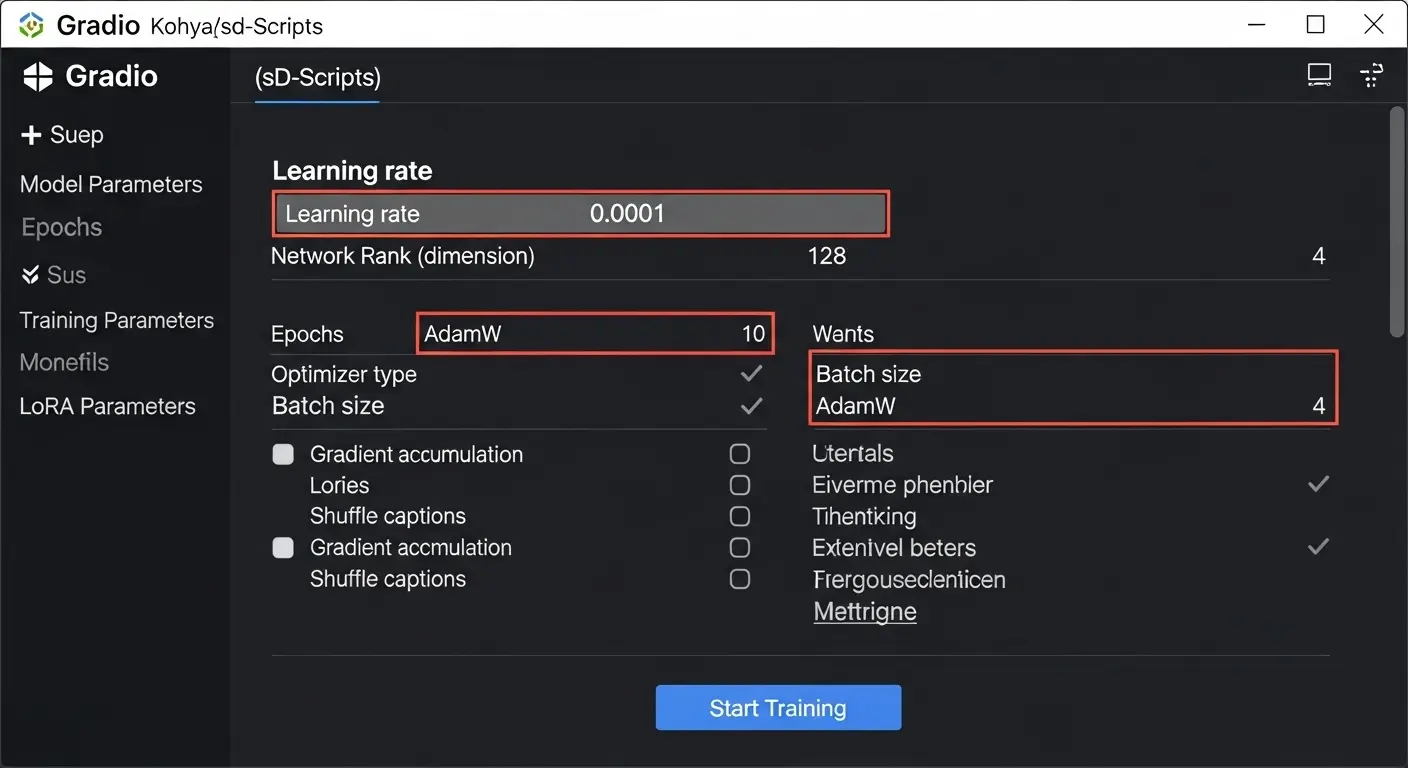
主要パラメータの調整
学習の成功を決める最も重要な項目です。
| パラメータ名 | 推奨設定 | 解説(初心者向け) |
| Network Rank (r) / Alpha (α) | r=16, α=8 または r=32, α=16 | LoRAの表現力の次元を決めます。高いほど表現力は増えますが、過学習しやすくなります。Alphaは学習率の調整に使われ、一般にRankの半分程度に設定します。 |
| Learning Rate (lr) | 1e-5 程度 | 学習の進み具合(速度)を決める重要な値です。高すぎると不安定に、低すぎると時間がかかります。(注釈: 1e-5は0.00001のこと) |
| Batch Size | 1 | 一度に処理する画像の枚数。VRAM容量が許す限り大きいほうが安定しますが、VRAM不足の場合は1に設定します。 |
| Epochs | 10〜20 程度 | データセット全体を何回学習させるか。教師データの枚数や繰り返し回数との兼ね合いで調整します。 |
| Optimizer | AdamW または Lion | 学習効率を決めるアルゴリズム。AdamWが標準的ですが、Lionはより高性能とされます。 |
学習の実行
GUIまたはコマンドラインで設定を確認後、学習を開始します。
accelerate launch --config_file="path/to/accelerate/config.toml" train_lora.py ...
実行中はVRAM使用率やLoss値の変化を監視します。Loss値が極端に低下し続ける場合は、過学習の可能性があります。
LoRA学習の失敗と対処法
よくある失敗:insufficient shared memory(shm)のエラー
Linux環境やDockerを使ったクラウド環境で学習を実行する際に発生しやすいエラーです。
これは、共有メモリ(shm)の容量が不足していることが原因です。
特に、大きなバッチサイズや高解像度で学習する場合に起こります。
解決策
Dockerを利用している場合は、起動時に--shm-size オプションを使って共有メモリ容量を確保します。
(例: docker run --shm-size="32g" ...)。ローカル環境の場合は、OS側の設定を見直す必要があります。
LoRA 学習 失敗の主な原因と解決策
| 失敗の種類 | 主な原因 | 解決策 |
| 過学習 (Overfitting) | 学習回数(Epochs)が多すぎる、教師データ枚数が少なすぎる、Learning Rateが高すぎる。生成画像が教師画像に似すぎてしまい、汎用性が失われます。 | Epochsを減らす、教師画像を増やす(30枚以上)、Learning Rateを下げる、正則化(Regularization)画像を使う。 |
| 学習が進まない | Learning Rateが低すぎる、教師データに一貫性がない、キャプションが不適切。 | Learning Rateを上げる、教師データを厳選する、キャプションにトリガープロンプトを含める。 |
| 意図しない要素が混入 | 教師データに特定の背景や服装が多すぎる。 | wd14-taggerで不要なタグを削除する。学習時にネガティブプロンプトの役割をする正則化データを使う。 |
| VRAM不足 | Batch Sizeが大きい、解像度が高すぎる。 | Batch Sizeを1にする、解像度を下げる、bitsandbytesの8bit Optimizerを利用する、Colabなどクラウドサービスの利用を検討する。 |
LoRA学習の失敗はこれで解決!原因特定とパラメーター設定の完全ガイド
生成結果の動作確認と応用
動作確認
学習が完了した後、出力フォルダに.safetensors 形式のLoRAファイルが作成されます。
これをStable Diffusion Web UIのLoRAフォルダに入れて、動作確認を行います。
- ベースモデルとLoRAを選択。
- プロンプトにトリガープロンプト(例: mychara)を入力。
- LoRAの強度(Weight)を調整(0.6〜1.0が一般的)して生成します。

もっと自由な画像生成へ:LoRA fine tuningの応用
LoRAの強みは、ベースモデルの知識とLoRAが学習した特徴を組み合わせて、さらに多様な画像を生成できることです。
- 複数のLoRAの組み合わせ: キャラクターLoRAと画風LoRAを同時に使用することで、より複雑な表現が可能になります。
- LoRA マージ(結合): 複数のLoRAを一つに統合し、新しいモデルを作る手法です。(内部リンク推奨: LoRA マージ(結合)方法と注意点)
- 商用利用: 規約を確認し、自作したLoRAや生成画像を販売・配布して収益化に繋げることも可能です。

アドセンス・アフィリエイト収益化戦略
収益化に向けたコンテンツ戦略
この記事は、LoRA 学習という専門的な知識を提供し、検索意図が明確なユーザーを集客することを目的としています。
収益化のために以下の要素を活用します。
アフィリエイト(ツール、サービス)
LoRA 学習には高性能なGPUやクラウドサービスが必須です。
- ゲーミングPC/グラボの紹介: 推奨環境(RTX 4070、RTX 4090など)を満たすPCやGPUを紹介します。(アフィリエイトリンク)
- クラウドコンピューティングサービス: Google Colab ProやRunPod、PaperspaceなどのGPUレンタルサービスを紹介します。(アフィリエイトリンク)
- 画像編集・管理ツール: 教師データの準備に役立つソフトを紹介します。
サイト外リンク
Stable Diffusion Web UI (AUTOMATIC1111)
アドセンス(専門性と回遊率)
専門的な知識記事は滞在時間が長くなり、アドセンス収益に貢献します。
また、関連子記事を豊富に用意することで、回遊率を高め、ユーザーの滞在時間と広告表示回数を増やします。
(内部リンク推奨: Stable Diffusion「LoRAの作り方」わずか3ステップ!)
2025年最新トレンド情報
2025年のAI画像生成の最新トレンドとして、LoRAの派生手法であるLoHaや新しいOptimizer(Lionなど)の登場、そしてSDXL対応の進展は重要です。

よくある質問と回答(FAQ)
LoRA 学習で最も重要なパラメータは何ですか?
最も重要なパラメータは、Learning Rate(学習率)とNetwork Rank(ネットワークランク)です。
- Learning Rate: 学習の速度を決定し、高すぎると過学習を招き、低すぎると時間がかかります。1e-5や1e-6程度から試すのが基本です。
- Network Rank (r): LoRAの表現力を決めます。16や32が標準的で、高いほど細部まで学習できますが、過学習のリスクも増えます。
LoRAとDreamboothの違いは何ですか?
LoRAとDreamboothは、どちらもベースモデルに新しい概念を学習させる手法ですが、学習の範囲と出力ファイルサイズに大きな違いがあります。
| 項目 | LoRA | Dreambooth |
| 学習範囲 | モデルの一部(差分)のみ | モデル全体(Checkpoint) |
| ファイルサイズ | 数十MB~数百MB | 数GB |
| 学習時間 | 短い(数分~数時間) | 長い(数時間~数十時間) |
| VRAM必要容量 | 比較的少ない(8GB 程度から可能) | 多い(16GB 以上が理想) |
まとめ:LoRA学習で自由なAI生成を実現
本記事では、Stable Diffusionを使ったLoRA 学習方法の全体像を、環境構築から教師データ準備、パラメータ設定、トラブル対処法まで、網羅的に解説しました。
LoRA 学習は、最初は複雑に感じるかもしれませんが。
しかし、本記事の手順に沿って進めていけば、AI初心者の方でも確実に「自分だけのLoRA」を作って理想の画像を生成することができます。

(サイト外リンク5) Kohya’s sd-scripts GitHub リポジトリ: https://github.com/kohya-ss/sd-scripts
(サイト外リンク6) Stable Diffusion 公式サイト(Stability AI): https://stability.ai/
(サイト外リンク7) Civitai(LoRA モデル配布サイト): https://civitai.com/
(サイト外リンク8) Google Colab 公式サイト: https://colab.research.google.com/
さあ、本記事で得た知識を活かして、あなたの創造性を解き放ちましょう。