
ChatGPTやClaudeなどのクラウドAIは非常に便利ですが、機密情報の漏洩リスクやサブスクリプション費用が懸念されることもあります。
エンジニアや研究者の方々は、自分のPC内で自由にAIを動かしたいと考えたことがあるかもしれません。
従来、大規模言語モデル(LLM)をローカル環境で動かすには、複雑な仮想環境の構築や依存関係の問題がありました。
しかし、Ollamaという革新的なツールの登場により、その常識は大きく変わりました。
本記事では、Windows環境でOllamaをインストールし、実際にモデルを動かすまでの全プロセスを詳しく解説します。
この記事を読み終える頃には、あなたのWindows PCはプライバシーが守られた強力なAIステーションへと進化しています。
Ollama Windows セットアップ
要点:公式サイトからインストーラーをダウンロードし、実行するだけで基本的なセットアップは完了します。
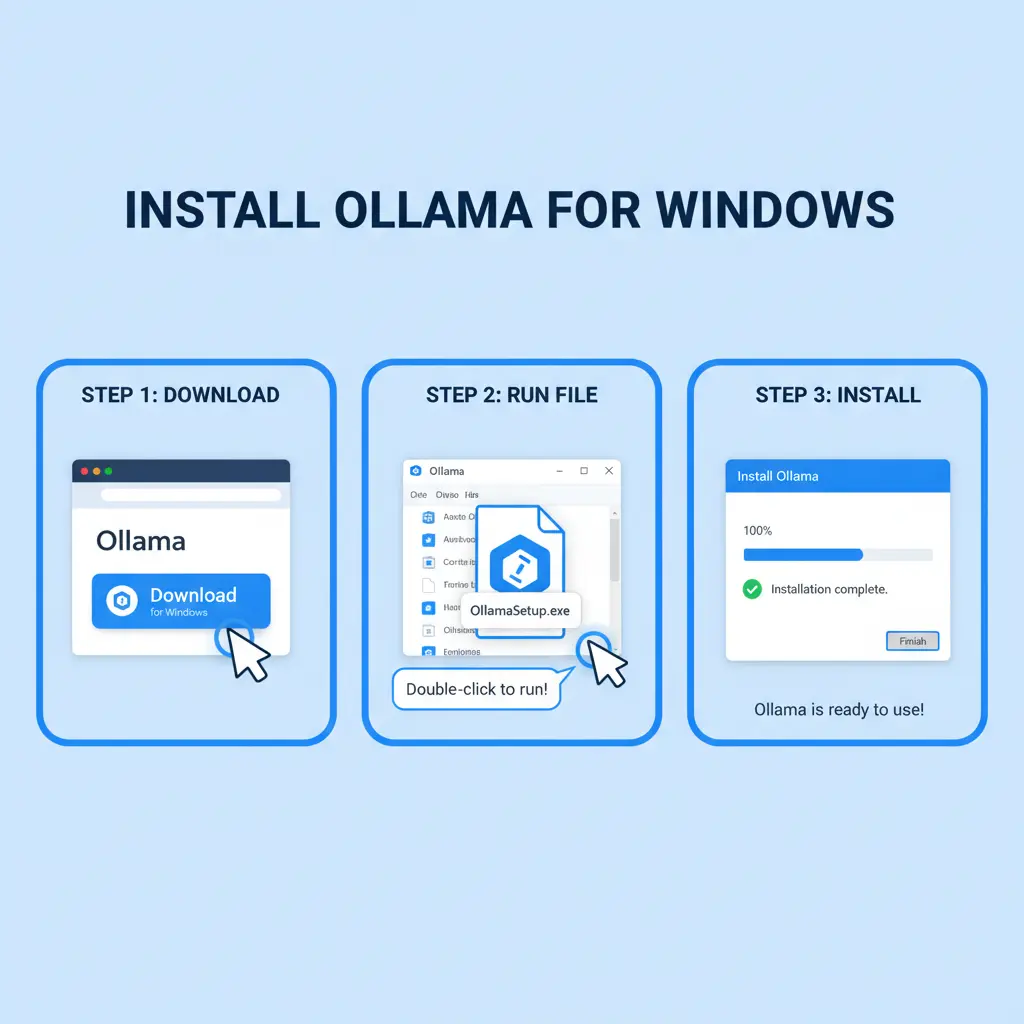
公式インストーラーの入手
- Windows環境でOllamaを利用するために、公式サイトへアクセス。
- トップページの「Download for Windows」ボタンをクリック。
- OllamaSetup.exeがダウンロードされ、必要な環境が自動的に整います。
インストールの実行
- ダウンロードが完了したら、ファイルを開いてインストールを開始。
- 画面の指示に従いクリックを進め、数分で処理が完了します。
- 起動後、システムトレイにOllamaのアイコンが表示されていれば、バックグラウンドでサービスが正常に稼働しています。
注釈: WSL2(Windows Subsystem for Linux 2)とは、Windows上でLinuxプログラムを直接動かす仕組みです。Ollamaはこの技術を利用して動作します。
Ollama ローカルLLM Windows
要点:コマンドプロンプトやPowerShellから簡単なコマンドを入力するだけで、モデルのダウンロードと実行が可能です。
モデルのダウンロードと実行
- インストール後、WindowsのスタートメニューからPowerShellまたはコマンドプロンプトを起動。
- 以下のコマンドを入力します。bash
ollama run llama3最初にモデルデータのダウンロードが必要なため、インターネット接続環境でしばらく待ちます。完了すると、そのまま対話モードが起動します。
実際の操作方法
対話モードになれば、ChatGPTのように質問を入力できます。
ローカルで動作しているため、入力した情報が外部サーバーに送信されることはありません。
使用後は「/bye」と入力すれば終了できます。
注釈: 大規模言語モデル(LLM)とは、膨大なテキストデータを学習し、人間のように自然な文章を生成できるAIモデルです。
Ollama Windows GPU
要点:NVIDIA製のGPUを搭載している場合、Ollamaは自動的にそれを認識し、高速な推論を実行します。
GPUアクセラレーションの確認
OllamaはWindows上でのNVIDIA GPU(CUDA)を自動検知します。実際にGPUが使用されているか確認するには、モデルの実行中にタスクマネージャーのパフォーマンスモニターをチェックします。
仮想環境とパフォーマンス
VRAMが不足している場合、Ollamaは自動的にCPUでの処理に切り替えます。
快適に動かすには最低でも8GB以上のVRAMが推奨されます。
また、最新モデルでは、量子化技術の進歩により、一般的なノートPCでも実用的な速度で起動できます。
注釈: 推論(Inference)とは、学習済みモデルにデータを与え、結果を導き出すAIのプロセスを指します。
Ollama Windowsの使い方
要点:ライブラリ機能やAPIを利用することで、単なる対話ツール以上の活用が可能です。
利用可能なモデルの一覧
Ollamaでは、llama3以外にも様々なモデルが利用可能です。
公式サイトのmodelsページにアクセスすれば、GoogleのGemmaや日本語に強いCommand Rなど最新の言語モデルを確認できます。
それらを使いたい場合は、以下の形式でコマンドを入力します。
bash
ollama run モデル名
API経由でのアクセス
Ollamaは起動中にローカルホストのポート11434でAPIサーバーとしても動作します。
これにより、PythonプログラムやOpen WebUIなどの外部ツールからOllamaを介してAIを利用できます。
これは独自のAIアプリケーションを構築する上で非常に強力な機能です。
Ollama Windows WSL2
要点:最新のWindows版OllamaはWSL2を意識せずに使用できますが、高度な開発では依然としてWSL2との連携が有効です。

仮想環境での柔軟な運用
Windowsネイティブ版Ollamaをインストール後、WSL2からlocalhost経由でそのAPIを叩くことが可能です。
この方法により、Windows上でAIを動かしつつ、開発環境はWSL2のLinux環境で行うことができます。
更新とメンテナンス
ツールの更新は、新しいインストーラーをダウンロードして再度実行するか、システムトレイのアイコンから更新を確認できます。
ローカルLLMの世界は日進月歩ですので、定期的な更新を行い、最新のモデルを利用し続けることが重要です。
よくある質問
Q: インストール後、コマンドが見つからないというメッセージが表示されます。
A: インストール完了直後は、一度コマンドプロンプトを閉じて開き直す必要があります。
それでも解決しない場合は、環境変数PATHにOllamaの実行ファイルが含まれているか確認してください。
Q: 特定のモデルを削除したい場合はどうすればいいですか?
A: ollama rm モデル名というコマンドを実行してください。
ローカルのストレージを節約するため、不要なモデルの整理をお勧めします。
Q: 商用利用は可能ですか?
A: Ollamaツール自体はMITライセンスで提供されていますが、動かす各モデル(llama3やGemmaなど)にはそれぞれの利用規約があります。
使用前に各モデルのライセンスを確認してください。
まとめ:WindowsでAIの力を手に入れよう
要点:OllamaはWindowsでのAIローカル環境構築において、2025年現在最も推奨されるツールです。
ローカル環境でLLMを動かすことは、自分だけの強力な知能を手に入れることと同じです。
Ollamaを使ってWindowsにAI環境をインストールする方法を紹介しました。
数回のクリックと簡単なコマンド入力で、次世代の知能を自分のPCで動かせることが理解いただけたと思います。
プライバシーを保ちながらインターネットがない場所でも自由にLLMを使える環境は、あなたの創作活動や開発業務を強力にサポートしてくれます。
まずは公式サイトから「Download for Windows」を試して、その驚きの速さと手軽さを体験してみてください。