Stable Diffusion(ステーブル・ディフュージョン)という言葉を聞いて、
- 「自分でも高品質なAIイラストや画像を生成したい」
- 「Web UIのAUTOMATIC1111って聞いたけど、インストールや使い方が難しそう…」
と困っていませんか?
ご安心ください。
今回の記事は、Windows PC、Mac PCユーザー、さらにGPUの知識がない初心者の方でも、Stable Diffusion Web UI(AUTOMATIC1111版)を今日から使えるように、
- 基礎知識
- インストール方法
- 使い方
最新の解決策まで、全てを体系的に解説する完全ガイドです。
2025年最新の情報を元に、画像生成AIの世界であなたの思い通りのイラストや画像を生成できるよう、一緒に手順を確認していきましょう。
知識:Stable Diffusion Web UIの全体像
Stable Diffusionとは
Stable Diffusion(ステーブル・ディフュージョン)とは、Stability AIという会社が開発。
2022年に公開された無料の画像生成AIモデルです。
最大の特徴は、プロンプト(呪文と呼ばれるテキスト)を入力するだけで、ユーザーが思い描いた画像を自動で生成できることです。
- 人物
- 風景
- アニメ
- 実写
など、多様なスタイルの画像を作成することが可能です。
Stable Diffusionの技術はオープンソースとして提供されています。
そのため、世界中の開発者が自由にカスタマイズできます。
様々なアプリケーションが登場しています。
Stable Diffusion Web UIとは
Stable Diffusion Web UIとは、Stable Diffusionという画像生成AIを、ブラウザ上で簡単に操作できるインターフェースのことです。
プログラミングの知識は一切不要。
- ボタンをクリック。
- テキストを入力。
- 画像をドラッグ&ドロップ。
これらの直感的な操作で画像生成を行えます。
このWeb UIの中でも、最も広く利用されているのが、AUTOMATIC1111氏が開発した「AUTOMATIC1111版」です。
Web UI AUTOMATIC1111とは
Stable Diffusion Web UI AUTOMATIC1111版は、その豊富な機能と高いカスタマイズ性から、画像生成AIの事実上の標準(デファクトスタンダード)となっています。
特徴: txt2img、img2imgといった基本機能から、ControlNetやLoRAなどの高度な拡張機能まで、全ての機能が搭載されています。
強み: コミュニティが活発で、情報が多く、トラブルシューティングの解決策が見つかりやすい点です。
AUTOMATIC1111とForge版の違い
2025年最新版として、AUTOMATIC1111版の高速化を目的として開発された「Forge(フォージ)版」も登場しています。
| 項目 | AUTOMATIC1111版 | Forge版 |
| 特徴 | 汎用性と機能の豊富さ | VRAM使用量削減と高速化 |
| VRAM効率 | やや低い | 最適化されている |
| 推奨ユーザー | 機能を網羅したい初心者・上級者 | VRAMが不足しがちなユーザー、高速生成を重視するユーザー |
| 互換性 | 拡張機能の対応が最も多い | AUTOMATIC1111の拡張機能を多く使えるが、一部非対応あり |
初心者の方は、情報の多い「AUTOMATIC1111版」から始めることを推奨します。
Stable Diffusion Web UIのインストール方法
Web UIを起動する環境は様々です。
自分のPCのスペック(知識:CPU、VRAMなどの性能)と用途に合わせて最適なインストール方法を選択しましょう。
Windowsにインストールする場合
Windows PCにローカルでインストールする手順は、最も一般的な方法です。
高性能なNVIDIA GPU(VRAM 8GB 以上を推奨)が搭載されている場合に最適です。
必須ソフトウェアの準備
AUTOMATIC1111を動作させるために、以下のソフトウェアを事前にインストールします。
- Python 3.10.6: Stable Diffusionの本体を実行するためのプログラミング言語の環境。インストール時に「Add Python to PATH」に必ずチェックを入れます。(→ Python公式サイト)
- Git: GitHubからWeb UIのソースコードをダウンロード(clone)するためのツール。(→ Git公式サイト)
Web UIのダウンロードと起動
GitHubからリポジトリをcloneし、Web UIのフォルダを作成します。
Bash
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
ダウンロードしたフォルダ内にある「webui-user.bat」をダブルクリックして実行します。
初回起動時に、必要なファイル(ライブラリやモデルなど)が自動でダウンロードされます。
インストールが完了します。
ターミナルに「Running on local URL: http://127.0.0.1:7860」が表示されたら起動完了です。
ブラウザでこのURLにアクセスしWeb UIを開きます。
Macにインストールする場合(17文字)
Mac PCにインストールする方法も可能です。
しかし、Windowsと比較して複雑になる場合が多いです。
Mac(特にM1/M2/M3チップのApple Silicon搭載機)の場合は、特別な設定やライブラリが必要になります。
Web UIの起動には「webui.sh」ファイル(Windowsの.batに相当)をターミナルで実行します。
Macの場合、VRAM(知識:GPU専用メモリ)とメインメモリを共有します。
そのため、VRAM 16GB 以上のモデルが推奨されます。
低スペックのMacで画像生成を試すと処理時間が長くなりすぎる可能性があります。
GPUクラウドサービスとは
GPUクラウドサービスは、自分のPCに高性能なGPUが搭載されていない場合でも、インターネット経由で高性能なサーバーにアクセスは可能です。
画像生成AIを実行する方法です。
- VRAMが不足しがちなMacユーザー
- 低スペックPCのユーザー
におすすめです。
料金は時間ごとの従量課金。
使った分だけ支払うことが可能です。
特に、GPUSOROBANやGoogle Colabは日本のユーザーに人気が高いです。
Stable Diffusionの環境構築が容易に行えます。
Google Colabにインストールする場合
Google Colab(Colaboratory)は、Googleが提供する無料(または有料のPro/Pro+)のクラウドサービスです。
ブラウザ上からPythonのコードを実行します。
Stable Diffusion Web UIを起動できます。
手順は、公開されているノートブック(Pythonのコードと説明が書いてあるファイル)をコピーします。
実行ボタンを順番に押すだけで完了します。
メリット: 環境構築が簡単。高いスペックのGPU(NVIDIA Tesla T4、A100など)を利用可能。
スマホからでも操作が可能です。
デメリット: 無料版には利用時間や使えるGPUに制限があります。
頻繁に使うと有料版が必要になります。
GPUクラウドサービス「GPUSOROBAN」にインストールする場合(Ubuntu)
GPUSOROBANは、日本の企業が提供する業界最安級のGPUクラウドサービスです。
UbuntuというOSを使用。
VScodeなどのツールを使ってサーバーにアクセス。
Web UIをインストールします。
手順はローカルPCでのインストールと似ています。
しかし、サーバー環境(Ubuntu)の操作が必要となります。
メリット: 低コストで安定したGPU環境を利用可能。高い専門性を持つ方のサポートも受けられる場合があります。(→ GPUSOROBAN公式サイト)
デメリット: Linux/Ubuntuの基本的なコマンド操作の知識が少し必要になります。
Web UI AUTOMATIC1111の基本操作
Stable Diffusion Web UIの使い方【初心者向け】
Web UIの画面は一見複雑に見えますが、画像生成に必要な主要な項目は限られています。
| 項目 | Web UI上のタブ | 役割(何ができるか) |
| 基本生成 | txt2img (テキスト to 画像) | プロンプトを入力し、新規画像を生成します。 |
| 応用生成 | img2img (画像 to 画像) | 元画像を元に、プロンプトで修正・変化させます。 |
| 設定管理 | Settings (設定) | Web UI全体の動作、日本語化、VRAM最適化などを調整します。 |
| 拡張機能 | Extensions (拡張機能) | ControlNetなど、機能を追加・管理します。 |
txt2imgの使い方
txt2img(テキストから画像を生成)は、Stable Diffusionの基本となる機能です。
- プロンプト欄(上側の大きなテキスト欄):生成したい画像の内容を英語で入力します。(例: masterpiece, 1girl, cat ears, school uniform, cherry blossom)
- ネガティブプロンプト欄(下側のテキスト欄):生成してほしくない要素を入力します。(例: low quality, worst quality, blurry, extra fingers, bad anatomy, EasyNegative)
- 生成ボタン:「Generate」(生成)ボタンを押すと、画像生成が開始されます。
初心者の方は、まずプロンプト例をそのまま使って、「Generate」を押してみることを推奨します。
パラメータの設定
画像生成のクオリティを左右する重要なパラメータは以下の通りです。
| パラメータ | 役割 | 推奨値 |
| Sampling Method (サンプラー) | ノイズを取り除く方法(知識:画像生成の計算アルゴリズム) | DPM++ SDE Karras または Euler a |
| Sampling Steps (ステップ数) | 生成の回数(処理時間と画質に影響) | 20~40 |
| Width, Height (サイズ) | 画像の幅と高さ | 512×512(基本)、512×768(全身・縦長) |
| CFG Scale (指示強度) | プロンプトに従う強度 | 7~11 |
| Seed (シード) | 画像生成開始点の番号(固定すると同じ画像が生成されます) | -1(ランダム) |
Stable Diffusion Web UI プロンプトを紹介
プロンプトは画像生成AIの心臓部です。高品質な画像を得るための呪文の入れ方のコツを解説します。
プロンプトの例・入れ方のコツ
プロンプトは重要な要素から順番に入力し、カンマ(,)で区切るのが基本です。
- 画風・品質: masterpiece, best quality, ultra detailed, photorealistic
- 被写体: 1girl, cute face, long hair, school uniform
- 背景: cherry blossom, cityscape, night, cinematic lighting
- ポーズ・動作: standing, looking at viewer, dynamic pose
- 強調/弱化: プロンプトを括弧で囲み、重みをつけます。例: ((cat ears)):1.3(猫耳を強く反映)
- ネガティブプロンプト: ネガティブプロンプトには、「EasyNegative」などの学習済みのファイルを利用することで、手の破綻や顔の崩れを大幅に軽減できます。

モデル・拡張機能の活用
Stable Diffusion Web UI おすすめモデルを紹介
モデルとは、AIが画像生成のために学習したデータファイル(知識: Checkpointまたは.safetensors)です。
モデルを変更することで、生成画像の画風(アニメ系、実写系など)が大きく変わります。
モデルとは
モデルは、Stable Diffusion Web UIの左上にあるプルダウンメニューで切り替えます。
- リアル系モデル: フォトリアルな画像生成に特化したモデル。(例: Realistic Vision、Juggernautなど)
- アニメ系モデル: 日本のアニメやイラスト調の画像生成に特化したモデル。(例: MeinaMix、Anythingなど)
モデルファイル(Checkpoint)の入れ方・使い方
- モデルファイルをHugging FaceやCivitaiなどのサイトからダウンロードします。
- ダウンロードした.safetensors/.ckpt/.ptファイルを、Web UIのインストールフォルダ内の
stable-diffusion-webui/models/Stable-diffusionフォルダに格納します。 - Web UIの左上のモデル選択欄の右側にあるリロードボタン(再読み込み)をクリックして反映させます。
Stable diffusion XI(SDXL)の使い方
SDXL(Stable Diffusion XL)は、2023年に登場した最新のモデルアーキテクチャです。
SDXLを利用することで、従来モデルよりも格段に高画質で複雑な構図を生成できます。
SDXLの特徴: プロンプトの理解力が高く、テキストの指示がそのまま画像に反映されやすいです。
使い方: SDXL専用のモデル(例: SDXL Base Model、SDXL Refiner)をダウンロード。
Web UIで選択します。
推奨サイズは1024×1024 以上となるため、VRAM 12GB 以上が必要になる場合が多いです。
追加学習モデルLoRAの使い方・作り方
LoRA(ローラ)は、モデル本体の画風を変えることなく、「特定のキャラクターの容姿」や「特定の服装」などの要素を追加するための追加学習モデル(知識: 小さな差分ファイル)です。
使い方: LoRAファイルを stable-diffusion-webui/models/Lora フォルダに入れます。
Web UIのプロンプト欄の下にある「LoRA」ボタン(または Show/hide extra networks)をクリック。
使いたいLoRAを選択すると、プロンプト欄に <lora:ファイル名:強度> が自動で入力されます。
作り方: LoRAの作り方には、Kohya’s GUIなどの外部ツールを使って、自分の用意した画像データを学習させる手順が必要です。(→Stable Diffusion「LoRAの作り方」わずか3ステップ!)
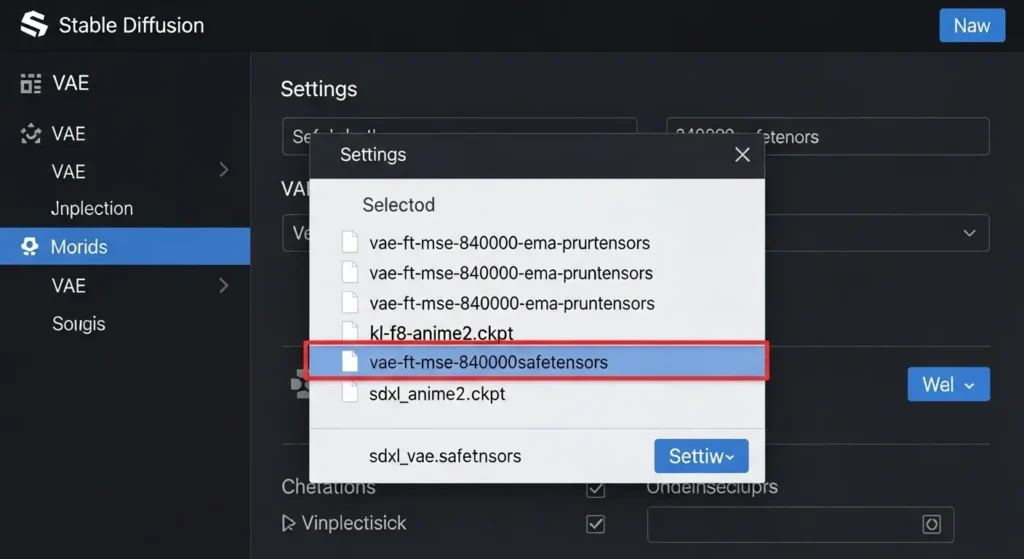
VAEの入れ方・使い方
VAE(Variational AutoEncoder)は、生成画像の「色味」や「コントラスト」といった最終的な仕上がり」に影響を与えるファイルです。
VAEを使う理由: 特にアニメ系モデルで、画像が「ぼやけ」たり、「色」がくすむことを解決し、鮮やかな高画質化を実現します。
入れ方: VAEファイル(例: vae-ft-mse-840000-ema-pruned.safetensors)を stable-diffusion-webui/models/VAE フォルダに入れます。
使い方: Web UIの Settings > VAE の項目で、ダウンロードしたVAEを選択。
「Apply settings」を押すと適用されます。
Web UIのカスタマイズと応用技術
Stable Diffusion Web UI 設定方法
Web UIを快適に使うために、最初に行っておきたい設定を解説します。
Stable Diffusion Web UIの日本語化
Web UIのインターフェースを日本語に変更することで、初心者でも直感的に操作しやすくなります。
- Extensions(拡張機能)タブを開く。「Install from URL」(URLからインストール)サブタブをクリックします。
- URL欄に 日本語化ファイルのGitHubリポジトリのURL(例: localizationリポジトリ)を入力。「Install」ボタンを押します。
- Installed(インストール済み)タブに戻る。「Apply and quit」(適用して終了)ボタンを押すと、再起動後に日本語化が完了します。
バージョンをアップデート・ダウングレードする方法(17文字)
Web UIは頻繁に更新されるため、不具合の解決や新機能の導入のためにアップデートが必要になります。
- アップデート: Web UIのフォルダ内の
git pullコマンドを実行するか、Extensionsタブの「Check for updates」(更新をチェック)を使って行います。 - ダウングレード: 特定のバージョンに戻る場合は、ターミナルで
git checkout <コミットID>コマンドを実行します。
拡張機能の使い方
Web UIの最大の魅力は、拡張機能(Extensions)による機能の追加です。
Extensions タブから、公式リポジトリの一覧を表示。
使いたい拡張機能を選択してインストールします。
ControlNetの使い方(12文字)
ControlNetは、生成画像の「構図」や「ポーズ」を正確に制御するための最も重要な拡張機能です。
- ControlNetを拡張機能タブからインストール。Web UIを再起動します。
txt2imgタブの下にControlNetのセクションが表示されます。- 「Enable」(有効)にチェックを入れる。元にしたい画像(ポーズの画像など)をアップロードします。
- Preprocessor(前処理)で「openpose」(知識: 人物の骨格)を選択。Model(モデル)で対応するControlNetモデルを選択します。
- 生成ボタンを押すと、元画像の構図やポーズに従った画像が生成されます。
img2imgの使い方
img2img(画像から画像を生成)は、既存の画像を元に新しい画像を生成する機能です。
img2imgタブを開く。元にしたい画像をアップロードします。- プロンプト欄に、元画像をどう変えたいかを指示するテキストを入力します。(例: 元画像が写真の場合、プロンプトに
anime styleを追加) - Denoising strength(知識: ノイズの除去強度。値が高いほど元の画像から大きく変化します)の値を調整します。推奨は0.5~0.7程度です。
- 「Generate」を押すと、元画像の構図を維持しつつ、プロンプトに従った新しい画像が生成されます。
その他のimg2imgの応用機能
- Inpaint(インペイント):画像の一部をマスク(塗りつぶし)し、マスクした部分だけをプロンプトで修正します。人物の服装や背景の一部変更に便利です。
- Outpaint(アウトペイント):画像の外側を拡張し、背景を自動で生成して補完します。

顔・表情のコントロールとエラー対策
生成画像の表情のコントロール
Stable Diffusionで全身や複数人物の画像を生成する際、顔や表情が崩れることが多いです。
- GFPGAN/CodeFormer: Web UIの「Extras」(追加機能)タブや、
txt2imgタブの「Restore faces」(顔の復元)オプションで利用可能です。生成後に自動で顔の部分を高画質化し、破綻を修正します。 - ADetailer (adetailer): 最新の拡張機能で、画像生成中に「顔」や「手」を自動で認識し、別のプロンプトで修正・描写を強化します。顔のクオリティを大幅に向上させるため、2025年現在、必須のツールとされています。

Stable Diffusion Web UI エラーを解説
Web UIを利用する際に発生しやすいエラーの原因と解決方法を解説します。
| エラーの種類 | 主な原因 | 解決策 |
| VRAM不足 (メモリ エラー) | 画像サイズが大きすぎる、Batch sizeが大きすぎる | サイズを小さくする。--medvram や --lowvram を起動オプションに追加する。 |
| AssertionError | Pythonのバージョンが間違っている | Python 3.10.6を再インストールし、PATHが正しく通っているか確認する。 |
| 起動できない (Web UIが開かない) | URLが正しくない、ポート 7860が他のアプリで使われている | ブラウザに http://127.0.0.1:7860 を手動で入力する。起動コマンドに --listen や --port XXXX を追加する。 |
運用とライセンスの種類
Docker版Stable Diffusion Web UIを使う方法
Docker(ドッカー)は、ソフトウェアの動作環境を隔離します。
簡単に構築・実行できるツール(知識: コンテナ技術)です。
メリット: PythonやGitのインストール手順をスキップできます。
環境依存のエラーが発生しにくいです。
異なるOS間でも同じ環境を再現できます。
使い方: Docker Desktopをインストール。
公開されているDocker Imageを docker pull コマンドでダウンロード。
docker run コマンドで起動します。
技術者や安定運用を重視する方におすすめです。
Stable diffusion Onlineとは(15文字)
Stable Diffusion Onlineとは、Web UIをローカルにインストールすることなく、ブラウザから直接、画像生成を行えるサービスの総称です。
例: Perplexity AIの画像生成機能、DreamStudio(Stability AI公式)、PICSOROBAN(GPUSOROBAN提供)。
メリット: インストール不要。
PCのスペックに依存しない。
スマホから利用可能。
デメリット: 無料枠に制限があることが多く、モデルや拡張機能の自由なカスタマイズができない場合があります。
初心者が「試しに」使うのに最適なツールです。
著作権・商用利用・ライセンスについて
生成画像の利用には、「Stable Diffusion 本体 モデル」と「追加学習 モデル(LoRAなど)」の両方のライセンスを確認する必要があります。
特に、商用利用(収益化を目的とした利用)を行う場合は注意が必要です。
Hugging Faceでのライセンス・注意事項の例
Hugging Faceは公式モデルや研究系モデルの配布が多いです。
- CreativeML Open RAIL-M: Stable Diffusionの主要モデルの多くが採用しているライセンスです。基本的に商用利用は可能ですが、「違法な目的」「差別」「ハラスメント」などを含む利用は禁止されています。
- Non-commercial: 研究目的や個人の趣味の範囲内での利用のみが許可され、商用利用は不可です。
Civitaiでのライセンス・注意事項の例
Civitaiはユーザーが作成したLoRAやCheckpointの配布が多いです。
- CC0/CC-BY: 比較的自由度が高く、商用利用が可能な場合が多いです(CC-BYはクレジット表記が必要)。
- 派生モデルの制限: 元のモデルが商用不可の場合、派生モデル(Mixモデル)も同様に商用利用が禁止されることがあります。必ずライセンスの詳細を確認してください。
最新動向: ライセンスは後から変更されることもあるため、ダウンロードした時点だけでなく、運用中も最新情報を確認しておく必要があります。
2025年最新トレンドと応用
もっと自由な画像生成を
Web UIの最新機能を活用し、生成画像の自由度を高めるためのトレンドを紹介します。
連携モデルの活用
- ControlNet Depth/Normal: 画像生成の「深度」(立体感)や「輪郭」を制御し、よりリアルで高画質な画像を生成します。風景や3D制作に応用できます。
- Tiling(タイリング): 継ぎ目なく繋がるテクスチャ画像を生成する機能で、ゲーム制作やWebデザインの背景素材に活用されます。
業務効率化への応用
- Batch Count/Batch Size: 複数枚の画像を一括で生成し、作業時間を短縮する機能です。(知識: Batch SizeはVRAMの消費が大きくなるため、スペックに応じて調整が必要です)
- プロンプト Matrix: 複数のプロンプト要素を組み合わせ、その全てのバリエーションを自動で生成し、比較するためのツールです。効果的なプロンプトを探す時間を大幅に削減できます。

Stable Diffusion Web UI 攻略のチェックリスト
Stable Diffusion Web UI 使い方
Stable Diffusion Web UI(AUTOMATIC1111)を使って、思い通りの画像を生成するための最終チェックリストです。
| 項目 | Web UI AUTOMATIC1111 攻略のコツ |
| 起動環境 | PCのVRAMが不足する場合は、Google ColabやGPUSOROBANを選びましたか? |
| 高画質化 | プロンプトの先頭に「masterpiece, best quality」を入力し、VAEを適用しましたか? |
| 構図制御 | 全身画像の場合、縦長サイズ(512×768など)を選択しましたか? |
| 破綻防止 | ネガティブプロンプトに「bad anatomy, extra fingers」を入れ、adetailerを有効にしましたか? |
| 日本語化 | 拡張機能を使って、Web UIを日本語に設定しましたか? |
もっと自由な画像生成を
Stable Diffusionの技術は日々進化しています。
AUTOMATIC1111の基本操作に慣れたら、次は以下の関連記事を読んで、より深い知識と応用技術を身に付けましょう。
- [ネガティブプロンプト徹底解説] Stable Diffusionで全身画像を完璧に生成!高画質化とプロンプト呪文全集
- [最新 ControlNet 応用術] Web UIでのポーズ制御と高画質化の極意(内部リンク)
収益化への行動:おすすめツールと応用
Stable Diffusion Web UIを使って生成した画像は、様々な形で収益化に繋げることが可能です。
高性能なGPUクラウドサービス(アフィリエイト)
安定した高画質画像生成には、高性能なGPUが不可欠です。
ローカルPCでの動作が遅い方は、以下のGPUクラウドサービスの利用を検討することを推奨します。
- GPUSOROBAN: 業界最安級の価格設定と安定性が特徴の日本企業のサービスです。
AI画像編集ツール(アフィリエイト)
生成した画像を最終的に加工し、ブログのアイキャッチやSNS投稿用に仕上げるために、以下のツールが便利です。
- Canva Pro: 画像編集やデザインのテンプレートが豊富で、Webコンテンツ制作の効率化に繋がります。(→ アフィリエイトリンク)
最新PC・周辺機器(アフィリエイト)
ローカル環境で高性能な画像生成を行いたい方には、NVIDIA GeForce RTX 4060 以上のGPUを搭載したPCがおすすめです。
Web UI AUTOMATIC1111に関するよくある質問
Q. Web UIを起動してもブラウザに画面が表示されません(17文字)
A. 主に2つの原因が考えられます。
1つは、コマンドプロンプト(ターミナル)に「Running on local URL: http://127.0.0.1:7860」が表示されているにも関わらず、自動でブラウザが開かない場合です。
この場合は、ブラウザのURL欄に http://127.0.0.1:7860 を手動で入力。
Enterを押してください。
もう1つは、インストール時のエラー。
そもそもWeb UIが正常に起動できていない場合です。
コマンドプロンプトのエラー内容を確認してください。
再度、PythonやGitのインストール手順を見直す必要があります。
Q. スマホ(iPhone/Android)からWeb UIを使うことはできますか?
A. ローカルPCにインストールしたWeb UIは、基本的にスマホから直接、アクセスすることはできません。
スマホから利用したい場合は、
- Google Colab(ノートブックに
--shareオプションを追加して実行) - GPUSOROBANなどのGPUクラウドサービスを利用する方法
が主流です。
これらのサービスで生成されたURLにアクセスすることで、スマホのブラウザから操作が可能になります。
Q. AUTOMATIC1111は重いですか?低スペックPCでも使えますか?
A. AUTOMATIC1111は多機能な反面、VRAM(GPUメモリ)を多く消費する傾向があります。
特に、高解像度やBatch Sizeを大きくすると重くなります。
VRAM 8GB 未満の低スペックPCの場合は、起動コマンドに --medvram や --lowvram オプションを追加することで、メモリ使用量を削減しましょう。
動作を軽くすることが可能です。
より快適に利用したい場合は、VRAM効率に優れた「Forge版」の利用を検討するか、GPUクラウドサービスの利用を推奨します。
画像生成の応用事例
多様なプロンプトの実験


img2img と ControlNet の応用


その他の Web UI 機能の紹介


追加画像情報