
- はじめに:理想の1枚を描き出す魔法の鍵
- Stable Diffusion モデル 種類と基礎知識
- 2026年におけるモデル管理の最新事情
- Stable Diffusion モデル 比較:実写系おすすめ
- Stable Diffusion モデル おすすめ:アニメ・イラスト系
- Pony系モデル専用「スコアタグ」の魔法
- 2026年流「ハイブリッドアニメモデル」の探し方
- Stable Diffusion モデル 種類:2.5D・セミリアル系
- 2026年の新常識「SDXL Turbo / Lightning」による超高速生成
- マージモデルシェアと「自作2.5D」のコツ
- Stable Diffusion モデルダウンロード:入手先とサイト紹介
- 2026年最新「モデルのトレンド分類」と探し方
- Stable Diffusion モデル 使い方:インストールと設定手順
- Stable Diffusion LoRAの活用と導入方法
- Stable Diffusion モデル比較:SD 1.5 vs SDXL vs FLUX
- Stable Diffusion モデル 商用利用とライセンスの注意点
- マージモデルシェアの重要性
- 2026年のトレンド「マルチモーダルRAGモデル」
- Stable Diffusion モデルの使い方:プロンプトと設定のコツ
- Stable Diffusion モデル インストール後のメンテナンス
- Stable Diffusion モデルの使い方:プロンプトの基礎
- 厳選!特定のジャンルに寄り添う特化型モデル一覧
- よくある質問(FAQ)
- まとめ:自分だけの「最高の一枚」を見つけよう
はじめに:理想の1枚を描き出す魔法の鍵
要点:Stable Diffusionのモデルは、AIが何をどのように描くかを決定する最も重要な要素であり、目的に合った選択がクオリティ向上の近道です。
最近、SNSや広告で見かける美しいAIイラストや、本物の写真と見紛うような高品質な実写画像。
それらを目にするたびに、自分もあんな風に綺麗な画像を作ってみたい、と思ったことはありませんか。
しかし、いざStable Diffusionを始めてみても、思うような絵柄にならなかったり、クオリティが低かったりと、理想と現実のギャップに悩む方は少なくありません。
実は、画像生成AIの世界において、クオリティの8割を決めると言っても過言ではないのがモデル選びです。
モデルとは、AIが学習した知識の塊です。
アニメ調が得意なモデルもあれば、実写を極めたモデルもあります。
今回、この記事では、数千種類以上存在するモデルの中から、2026年現在で特におすすめしたいものを一覧形式で紹介します。
この記事を最後まで読めば、あなたがどのモデルを選べます。
どのようにインストールすれば良いかが明確になります。
今日からクリエイターとしての第一歩を自信を持って踏み出せるようになるでしょう。
Stable Diffusion モデル 種類と基礎知識
要点:Stable Diffusionのモデル環境を構築するには、Checkpointを核として、画風を補正するVAEや特定の要素を強化するLoRAを適切に組み合わせる知識が必要です。
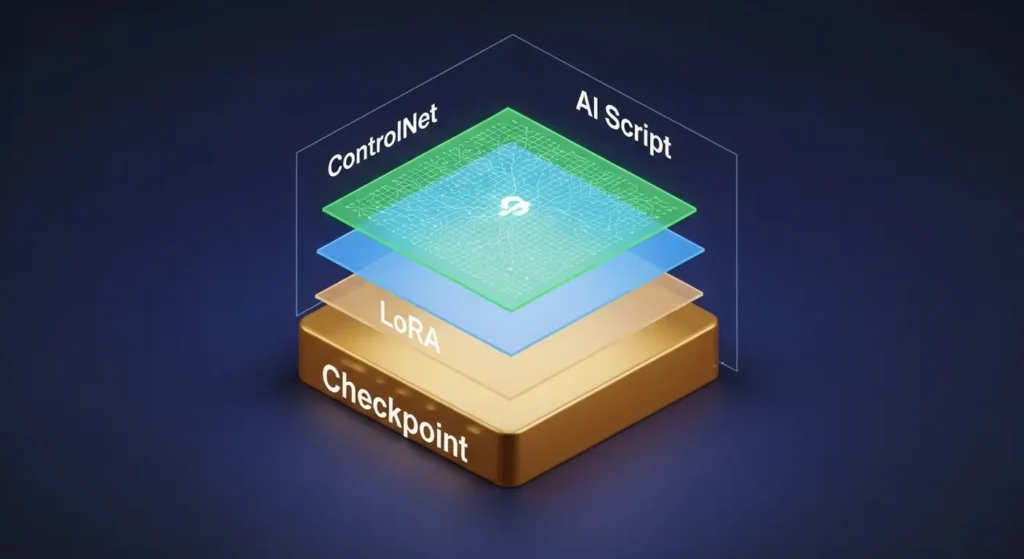
Checkpoint(チェックポイント)とは
Checkpoint は、画像生成の土台となる最も重要なファイルです。
AI が膨大な画像とテキストのペアを学習した結果が詰まっております。
これ一つで実写風かアニメ風かが決まります。
- 主な拡張子: 以前は
.ckptが一般的でしたが、現在は悪意のあるプログラムが含まれるリスクが低い.safetensors形式が推奨されています。 - 学習ベースの違い: 現在、広く使われているベースモデルには「SD 1.5」と「SDXL」があります。SD 1.5は動作が軽く低スペックなPCでも動きますが、SDXL はより高品質で高解像度な画像が生成可能です。
LoRA(ローラ)の役割と強み
LoRA(Low-Rank Adaptation)は、Checkpoint の画風を大きく変えずに、特定のキャラクターや背景、ポーズなどを追加で学習させた小さなファイルです。
- メリット: Checkpoint が数 GB という巨大なサイズなのに対し、LoRA は数十〜数百 MB と軽量です。
- 使い方: WebUI の専用タブから選択し、プロンプト内に特定のコードを記入することで、効果を発揮します。
VAE(ブイエーイー)による色彩の改善
生成した画像が全体的に白っぽくなったり、色がくすんで見えたりする時は、VAE が正しく適用されていない可能性があります。
- 機能: AI が内部で処理する数値データを、私たちの目に見える美しい色彩に変換する工程を担います。
- 内蔵モデル: 最新のモデルでは、Checkpoint 内部に VAE が最初から内蔵されているタイプも多く、初心者でも設定の手間が省けるようになっています。
ControlNet(コントロールネット)の導入
2026年現在、上級クリエイターの間で当たり前のように活用されているのが ControlNet です。
- 概要: 画像の構図や人物のポーズを、線画や深度情報を用いて直接コントロールする拡張機能です。
- 利便性: プロンプトだけでは難しい特定のポーズや部屋のレイアウトの指定を、驚くほど正確に再現できます。
注釈:プロンプト(呪文)とは、AI に対して「何を描いてほしいか」を指示するための英単語や文章のことです。
Stable Diffusionプロンプト保存と再利用の決定版:AIイラスト生成を時短
2026年におけるモデル管理の最新事情
要点:モデルの数が増え続ける中で、ブラウザ上で効率的にプレビューを確認し、管理するツールの導入が必須となっています。
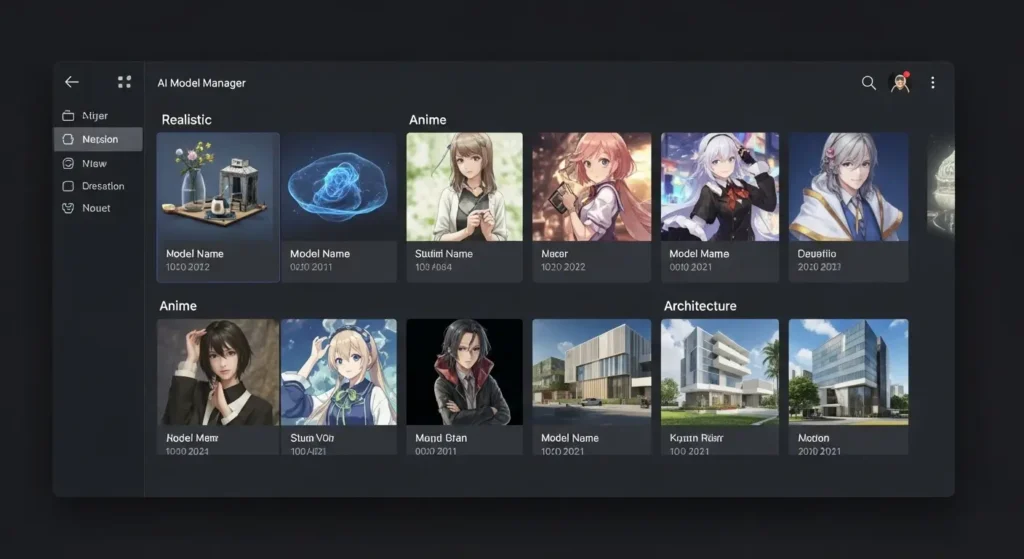
以前はディレクトリ内のファイル名だけで判断していましたが、現在はモデルごとのサンプル画像を自動で表示します。
ライセンスやバージョンを一括でチェックできる環境が整っています。
これにより、商用利用の可否などを間違えるリスクを大幅に減らすことが可能です。
Stable Diffusion モデル 比較:実写系おすすめ
要点:実写(フォトリアル)系モデルは、
- 肌の質感
- 光の当たり方
- 背景のディテール
において、実在する写真と見分けがつかないレベルにまで進化しています。
特に2026年現在は、従来のSDXLベースに加え、次世代のFLUX系モデルが業界のスタンダードになりつつあります。
FLUX.1 [dev / schnell] シリーズ
2026年現在、実写系において「最強」の名を欲しいままにしているのがFLUXシリーズです。
従来のStable Diffusionで課題だった「指の描写」や「文字の正確さ」をほぼ克服しています。
- 特徴: DSLRカメラで撮影したような圧倒的な解像感。肌の毛穴や産毛まで描写可能。
- 強み: 複雑なプロンプトへの忠実度が非常に高く、ライティングの指定も正確に反映されます。
Juggernaut XL (Ragnarok / v10)
SDXLベースの最高峰として君臨し続ける定番モデルです。
2026年のアップデート版(Ragnarok等)では、さらにフォトリアルな質感が強化されています。
- 特徴: 映画のワンシーンのようなドラマチックなライティング(シネマティック)が得意。
- 強み: 人物だけでなく、建築物や風景のリアリティも非常に高く、汎用性が抜群です。
Realistic Vision V6.0
長年愛され続けているシリーズの最新版です。
過度な美化をせず、あえて「現実的な不完全さ」を描写することで、本物の写真のような質感を生み出します。
- 特徴: 派手すぎない自然な発色と、日常的なスナップ写真のような雰囲気。
- 強み: 日本人を含むアジア系の顔立ちを、違和感なく自然に生成できるため、国内ユーザーに非常に人気があります。
RealVisXL V5.0
写真としての「正確性」を極限まで追求したモデルです。
- 特徴: 歪みの少ないレンズ効果や、被写界深度(ボケ味)の表現が極めてリアル。
- 強み: ファッションフォトやポートレートなど、特定のカメラ機材を想定したような高品質な作品作りに適しています。
実写系モデルの性能比較表(2026年版)
| モデル名 | ベース技術 | 得意ジャンル | リアル度 | 動作の軽さ |
| FLUX.1 | FLUX | オールジャンル | ★★★★★ | ★★☆☆☆ |
| Juggernaut XL | SDXL | シネマティック・建築 | ★★★★☆ | ★★★☆☆ |
| Realistic Vision | SD 1.5 / SDXL | 人物・スナップ | ★★★★☆ | ★★★★☆ |
| RealVisXL | SDXL | ポートレート・写真 | ★★★★★ | ★★★☆☆ |
実写クオリティを爆上げする「2026年流」設定術
要点:良いモデルを選ぶだけではありません。
2026年現在の最新パラメーター設定を適用することで、さらに1段階上のリアリティを引き出せます。
- CFGスケールの調整:実写系ではCFGスケールを高くしすぎないのがコツです。
3.5 〜 5.5程度に設定すると、AI特有の「テカリ」が抑えられ、より生身の肌に近い質感が得られます。 - ネガティブプロンプトの最小化:最新のFLUXやSD 3.5系モデルでは、長いネガティブプロンプトは逆に画質を損なう場合があります。
bad quality, text程度の最小限に留めるのが2026年のトレンドです。 - HiRes.fixの活用:一度生成した画像を1.5倍〜2倍に拡大再生成する「HiRes.fix」は必須です。拡大時のデノイジング強度は
0.3 〜 0.4に設定することで、元の造形を崩さずに細部の描き込みだけを強化できます。
注釈:デノイジング強度とは、画像を再生成する際に「どれくらい元の絵を書き換えるか」という数値です。
低いほど元の形を維持します。
Stable Diffusion モデル おすすめ:アニメ・イラスト系
要点:アニメ・イラスト系モデルは、2026年現在、単なる絵柄の変更を超え、複雑なポーズの再現性やライティングの美しさ、そして指や背景の破綻の少なさにおいて飛躍的な進化を遂げています。
特にSDXLベースの Pony系 や Illustrious系 が主流です。

Illustrious-XL(2026年最新本命モデル)
2025年末から2026年にかけて、アニメ系モデルの決定版として紹介されているのが Illustrious-XL です。
- 特徴: 従来のモデルよりも自然な文章による指示の理解力が極めて高いのが特徴。
- 強み: 複雑な構図や、2人以上の人物を描き分ける能力に優れています。アニメ的なフラットな塗りから、厚塗り風まで幅広いスタイルに対応。
Pony Diffusion V6 XL(最強のポーズ再現性)
画像生成ファンの間で定番と呼ばれる、圧倒的な人気を誇るモデルです。
- 特徴: Danbooruタグと呼ばれる特有の単語を使って指示を行うことで、驚くほど正確なポーズや服装を再現できます。
- 強み: 拡張機能や LoRA との相性が抜群に良く、キャラクターの一貫性を保つのに最適です。
Animagine XL V3.1
高品質で鮮やかな色彩と、精細な背景描写が特徴のモデルです。
- 特徴: 3Dゲームや最新のアニメーション映画のような雰囲気を持つ画像を作成しやすい点。
- 強み: 高解像度設定での出力に強く、ポスターのような一枚絵の制作に向いています。
アニメ・イラスト系モデルの推奨設定比較
| モデル名 | 推奨プロンプト形式 | 得意なテイスト | 2026年の評価 |
| Illustrious-XL | 自然な文章 | モダンアニメ | ★★★★★ |
| Pony Diffusion | タグ形式 | ポーズ・キャラ | ★★★★★ |
| Animagine XL | 混合形式 | 幻想的・背景 | ★★★★☆ |
Pony系モデル専用「スコアタグ」の魔法
要点:Pony Diffusion系のモデルを使う際は、専用の品質タグを冒頭に入れることで、クオリティを劇的に向上させることが可能です。
Ponyをベースにしたマージモデルでは、通常のプロンプトに加え、以下のようなスコアタグを使用することが公式に推奨されています。
- 入力例:
score_9, score_8_up, score_7_up, rating_safe, source_anime, (プロンプト本文) - 効果: これにより、AIが「学習データの中でも特に高い評価の画像」を優先的に参考にするようになり、色や描写の密度が大きく上がります。
2026年流「ハイブリッドアニメモデル」の探し方
要点:Civitaiなどで「Illustrious」や「Pony」という名で検索し、新着のマージモデルをチェックするのが最新のトレンドです。
最近は、一つのモデルだけをそのまま使うのではなく、AutismMix や NoobAI といった特定の強みを持った派生モデルを試してみる人が増えています。
自分の好みに合った絵柄を見つけたら、ぜひそのモデルの説明ページを最後までご覧になり、推奨されるネガティブプロンプトもコピーしておきましょう。
注釈:ネガティブプロンプトとは、AIに「描かないでほしい要素」を伝えるための指示です。
例えば worst quality(最低品質)などを入れることで、悪いクオリティな生成を防ぐことができます。
Stable Diffusion モデル 種類:2.5D・セミリアル系
要点:2.5D(セミリアル)系モデルは、アニメの可愛らしさと実写のリアルな質感を両立させた、SNSや広告で最も人気の高いジャンルです。
2026年現在は、肌の透明感や照明表現が劇的に向上しています。

Counterfeit V3.0 (2.5Dの金字塔)
初心者からプロまで幅広く支持されている、2.5D系の定番モデルです。
- 特徴: 背景の描き込み描写が非常に精細で、イラストレーターが描いたような芸術アート的な雰囲気を出し出せます。
- 強み: どんなプロンプトでも安定して高品質な画像を生成できるため、最初に導入すべき一つです。
Rev Animated (ファンタジー特化)
ファンタジー世界やゲームグラフィックのような世界観を得意とするモデルです。
- 特徴: 重厚な色彩と、魔法や光の効果が美しく再現されます。
- 強み: 人物の顔立ちが整っており、美少女だけでなく格好いい男性や動物もハイクオリティに描画できます。
XXMix_9realistic (アジア系セミリアル)
日本人やアジア人のリアルな美しさを追求しつつ、アニメ的な可愛さを残したモデルです。
- 特徴: 肌の質感や瞳の輝きが繊細で、フォト風のポートレートに適しています。
- 強み: 実写に近いけれど加工修正しすぎない、絶妙なバランスが魅力です。
2026年の新常識「SDXL Turbo / Lightning」による超高速生成
要点:2.5Dモデルの多くが、現在ではわずか数ステップで高解像度な画像を作れるように進化しています。
以前は1枚の画像を作るのに数分から2時間以上かかっていたこともありましたが、最新の技術では数秒以内に完了します。
- 効率の向上: LCM LoRA や SDXL Lightning(l1)を組み合わせることで、作業スピードが大きく上がりました。
- リアルタイム生成: 入力した文章に合わせて、画面の絵が次々に変わる体験が可能になりました。
マージモデルシェアと「自作2.5D」のコツ
要点:Civitaiに掲載されていない独自の絵柄を作るには、実写系とアニメ系を半分ずつでマージするのが最も簡単な方法です。
自分だけのオリジナルモデルを作成する際は、下記のポイントを意識しましょう。
- ベースの選択: はじめに基本となる ckpt を2つ選びます。
- 比率の調整: 最初は半分ずつから始め、少しずつ数値を変更して理想の雰囲気を探します。
- 検証の実施: 同じプロンプトで複数のマージモデルを比較し、最高の結果を保存します。
注釈:マージとは、2つ以上の学習済みモデルを合成し、新しい特徴を持った一つのモデルを作るのことです。
Stable Diffusion モデルダウンロード:入手先とサイト紹介
要点:高品質な画像生成に欠かせないモデルsは、CivitaiやHugging Faceといった世界的なプラットフォームから無料でダウンロード可能です。
利用目的に応じて最適なサイトを選択し、ライセンスを守って活用しましょう。

Civitai(シビタイ):画像生成AI特化の最大手
AI画像生成に関わる方なら、必ずチェックすべきサイトです。
- 特徴: 各モデルの詳細ページに実際に生成された参考画像が並んでおり、雰囲気を確認しやすいのが最大のメリットです。
- 機能: 右上のボタンをクリックするだけで簡単に download でき、使っている人のレビューや評価を参考に選ぶことができます。
Hugging Face(ハギングフェイス):技術者向けの総本山
機械学習の研究や開発のための大規模なプラットフォームです。
- 特徴: stability ai 公式の base モデルや、最新の論文に基づいた実験的な models が豊富に掲載されています。
- 使い方: files タブから必要な safetensors を探す手順となります。検索機能を活用して最新情報を追いましょう。
SeaArt(シーアート):ブラウザで試せるクラウドサービス
ローカル環境を構築するのが難しい初心者向けのオンラインサービスです。
- 特徴: ログインするだけでクラウド上の gpu を使い、web ブラウザから直接画像を作れます。
- 利便性: スマホでも動作し、有名な checkpoint があらかじめ用意されているため、試しに始めてみたい方に最適です。
2026年版「安全なダウンロード」と著作権の守り方
要点:運営側のチェックを通った安全なファイルのみを使うことと、license 条件を守るリテラシーがこれまで以上に重要視されています。
- プライバシーポリシーの確認: 会員登録の際は、メールアドレス等の個人情報の取り扱いに注意が必要です。
- 商用利用の可否: 各モデルに書かれている license をしっかり見て、クレジット表記がなしでいいのか、販売が可能なのかを判断しましょう。
2026年最新「モデルのトレンド分類」と探し方
要点:現在の主流は、sdxl よりもさらに進化した flux や illustrious といった新世代の新しい型に移行しつつあります。
探し方のコツとしては、上部のカテゴリータブから新着順に並べ変え、注目度の高いものを上から順に見ていくのがスムーズです。
- 実写実在系: photoreal な美女や人物画像を作りたい時に選びます。
- anime 2d イラスト: manga 風や可愛い女の子を描くのに適しています。
- 風景・建築: 部屋の内装や自然の描写に特化したモデルも増えています。
注釈:Danbooru(ダンボール)タグとは、画像の内容を説明するための英単語タグの集合で、anime 系のモデルでよく使われます。
Stable Diffusion モデル 使い方:インストールと設定手順
要点:ダウンロードしたモデルファイルは、指定のディレクトリに配置し、WebUI上で切り替えることで使用可能になります。
モデルを手に入れたら、実際に使えるように設定しましょう。ここでは最も普及しているStable Diffusion WebUI (AUTOMATIC1111) を例に解説します。
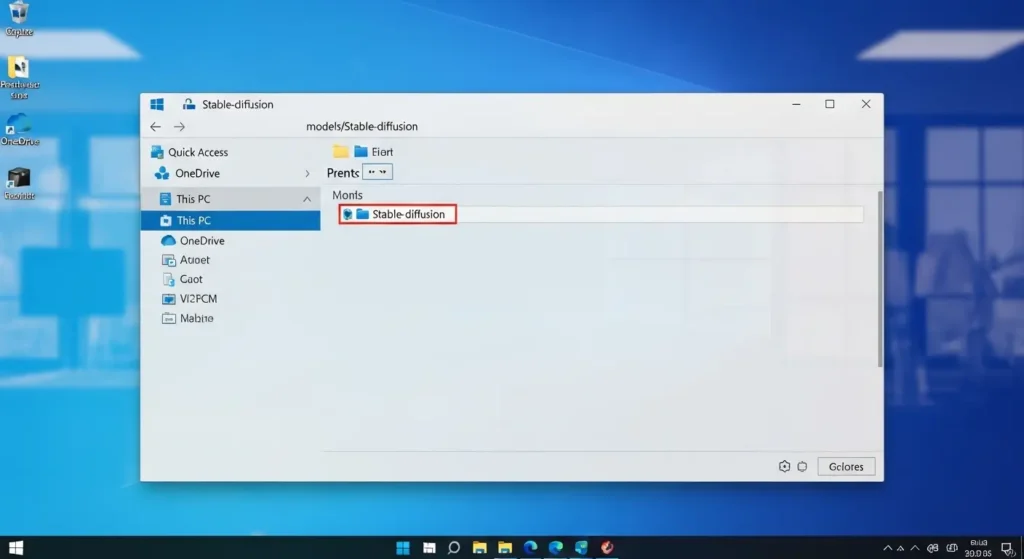
モデル インストールのステップ
- モデル配布サイトから .safetensors ファイルをダウンロードします。
- Stable Diffusionをインストールしたフォルダを開きます。
models/Stable-diffusionというディレクトリを探します。- その中に、ダウンロードしたファイルを移動(またはコピー)します。
- WebUIを起動している場合は、画面上部の「Refresh」ボタンをクリックするか、UIを再起動します。
WebUI モデルの切り替え方法
画面左上の「Stable Diffusion checkpoint」というドロップダウンメニューをクリックします。
先ほど追加したモデル名が表示されているので、それを選択すれば完了です。ロードには数十秒かかる場合があります。
Stable Diffusion LoRAの活用と導入方法
要点:LoRAはCheckpoint単体では表現しきれない細かな特徴を追加する拡張機能であり、微調整に欠かせません。
ベースモデルだけでは「特定のこのキャラクターを完璧に描きたい」といった細かな要望に応えるのは難しいものです。そこで役立つのがLoRAです。
LoRAの役割
LoRAは
- 「特定の顔立ち」
- 「特定の画風」
- 「特定の服装」
などを上乗せするフィルターのようなものです。
Checkpointが「油絵の具一式」だとしたら、LoRAは「特定の描き方のテクニック」のようなイメージです。
LoRA 使い方
- LoRAファイルを
models/Loraフォルダに入れます。 - WebUIの「Lora」タブを選択し、使用したいLoRAをクリックします。
- プロンプト内に
<lora:モデル名:1.0>のような記述が追加されます。 - 末尾の数字(強度)を変更することで、どれくらいそのLoRAの影響を出すか調整できます。
Stable Diffusion モデル比較:SD 1.5 vs SDXL vs FLUX
要点:ベースとなるエンジンのバージョンによって、推奨されるPCスペックや生成される画像のクオリティ、対応する拡張機能が異なります。
モデルを探していると、「SD 1.5」や「SDXL」といった言葉をよく目にします。これらは土台となる技術のバージョンです。
| バージョン | 特徴 | 推奨VRAM | メリット |
| SD 1.5 | 最も普及している | 8GB以下でもOK | 拡張機能やLoRAが豊富。動作が軽い。 |
| SDXL | 高解像度・高品質 | 12GB以上推奨 | プロンプトの理解力が高い。細部まで綺麗。 |
| FLUX | 2026年最新鋭 | 16GB以上推奨 | 指の描写や文字の描写が完璧に近い。 |
注釈:VRAM(ブイラム)とは、ビデオメモリのことです。グラフィックボード(RTX 4060等)に搭載されているメモリで、画像生成AIの処理能力に直結します。
2026年最新トレンド「FLUX」モデルの衝撃
現在、急速にシェアを伸ばしているのがFLUXです。
これまでのStable Diffusionでは難しかった
- 「看板の文字を正しく描く」
- 「複雑に絡み合った指を正確に描写する」
といった課題をクリアしており、商用利用でも高いクオリティを発揮します。
Stable Diffusion モデル 商用利用とライセンスの注意点
要点:全てのモデルが自由に商用利用できるわけではなく、Civitaiなどの利用規約を必ず確認する必要があります。
生成した画像を販売したり、業務で利用したりする場合、モデルのライセンス(CreativeML OpenRAIL-M 等)を確認しなければなりません。
- 商用利用不可の例: モデル開発者が「このモデルで作った画像の販売は禁止」と定めている場合があります。
- マージモデルの権利: 複数のモデルを混ぜ合わせた「マージモデル」の場合、元となった全てのモデルの規約を遵守する必要があります。
- クレジット表記: 利用時に開発者の名前を記載することが条件となっているものもあります。
注釈:CreativeML OpenRAIL-M(クリエイティブ・エムエル・オープンレイル・エム)とは、AIモデルに特化したライセンス体系で、自由な利用を認めつつ、有害な目的での使用を禁止する条項が含まれています。
マージモデルシェアの重要性
要点:自分でモデルをマージ(混合)することで、世界に一つだけの独自の画風を作り出すことが可能です。
「アニメ系と実写系の中間が欲しい」といった場合、既存のモデル同士を混ぜ合わせる「マージ」というテクニックがあります。
マージの仕組み
WebUIの「Checkpoint Merger」機能を使うと、2つまたは3つのモデルを任意の割合(例:モデルAを70%、モデルBを30%)で合成できます。
これにより、特定のモデルの弱点を別のモデルで補うといった高度な調整が可能になります。
人気のマージモデル例
多くの人気モデル(AnythingやRealistic Vision等)自体が、実は優れたマージの結果として生まれたものです。
2026年のトレンド「マルチモーダルRAGモデル」
要点:単なる画像生成だけでなく、文章の文脈や特定のデータベースから情報を引用して正確な描写を行うモデルが登場しています。
最新のAI技術(RAG:検索拡張生成)を画像生成に応用する動きが加速しています。
RAG(ラグ)とは
これまではAIが覚えている知識だけで描いていましたが、RAG対応モデルは「特定の企業の製品」や「実在の建物」のデータを外部から参照し、正確に描写することができます。
これにより、架空の物体ではなく、実務に即した正確なビジュアル作成が可能になります。
注釈:RAG(Retrieval-Augmented Generation)とは、外部の信頼できる情報を検索し、その情報を反映させて回答や生成を行う技術のことです。

Stable Diffusion モデルの使い方:プロンプトと設定のコツ
要点:モデルの性能を100%引き出すには、推奨される設定(サンプラー、CFGスケール、ステップ数)を守ることが不可欠です。
どんなに良いモデルを使っても、設定が悪いと宝の持ち腐れです。
- サンプラー(Sampler): 画像を生成するアルゴリズムです。最近は
Euler aやDPM++ 2M Karrasが定番です。 - CFGスケール: プロンプトにどれくらい忠実に従うかの数値です。通常は
7前後が安定します。高くしすぎると画像が焼けたように不自然になります。 - ステップ数: 描き込みの回数です。実写系なら
30〜50、イラスト系なら20〜30が目安です。多すぎてもクオリティが変わらないばかりか、時間が無駄になります。
Stable Diffusionで全身画像を完璧に生成!高画質化とプロンプト呪文全集
Stable Diffusion モデル インストール後のメンテナンス
要点:モデルは日々更新されるため、定期的に新バージョンを確認しましょう。
不要な古いモデルを整理することがPCの快適な動作に繋がります。
更新のチェック
人気のモデルは「V2」「V3」とアップデートされます。
Civitaiの「Follow」機能を使うと、お気に入りモデルの更新通知を受け取ることができます。
ストレージの管理
モデル一つで数GBあるため、気づくと数百GBの容量を消費しています。
使わなくなったモデルは外付けSSDなどに移動します。
PC内部のストレージ(Cドライブ等)を空けておくことで、システムの動作が安定します。
Stable Diffusion モデルの使い方:プロンプトの基礎
要点:モデルの真価を引き出すには、プロンプトの記述ルールを理解し、ChatGPTなどのLLM(大規模言語モデル)をエージェントとして活用する「2026年流」の生成ワークフローが非常に効果的です。
ChatGPTやClaudeをプロンプトエージェントとして活用する
画像生成AIの進化に伴い、人間が手動で呪文を考えるよりも、
- ChatGPT
- Claude
- Gemini
といった最新のLLMにプロンプト生成を依頼する手法が一般化しています。
- 精度の向上: LLMに対して「Stable Diffusion用のプロンプトを作って」と依頼する際、対象のモデル(Model)がSD 1.5ベースかSDXLベースかを事前に伝えると、より適切なバリエーションの呪文を提案してくれます。
- 日本語からの翻訳: 日本語で「青い髪の美しい女性」と入力するだけで、LLMが
beautiful woman with blue hair, detailed eyes, masterpieceといった、AIが理解しやすい英語のタグ形式に変換してくれます。 - NSFW設定の回避: 公序良俗に反する内容(NSFW)を避けます。安全なコンテンツ(Safe for Work)として出力させるためのネガティブプロンプトも、LLMなら一瞬で徹底的に網羅してくれます。
2026年最新:動画生成AIとの組み合わせ
現在、静止画のモデルから動画を生成する技術もリリースされています。
お気に入りのモデルで作った静止画をベースに、DALL-E 3やNovelAIとは異なるアプローチです。
自分だけのショート動画を作ることが可能です。
- 一貫性の保持: 特定のCheckpoint(YayoiやBlue Pencilなど)で生成した人物の顔を固定したまま、背景だけを動かすといった特殊な処理も、専用の拡張機能を使えば個人レベルで実現できます。
- 音声との同期: 生成したキャラクターに、別途用意した音声データを組み合わせて喋らせる「AIエージェント」的な活用も、今や2.0世代のスタンダードな楽しみ方です。
厳選!特定のジャンルに寄り添う特化型モデル一覧
要点:目的(Dream)に合わせたモデル選びができるよう、編集部が今おすすめするバリエーション豊かな厳選モデルを項目ごとに整理しました。
パステル・芸術系:Pastel-Mix
(Pastel)Pastel Mixは、水彩画のような淡い色彩と柔らかい質感が特徴です。
夢(Dream)の中の風景のような、幻想的なイラストを作りたい方に適しています。
緻密な線画系:Blue Pencil
Blue Pencilは、アニメ系の中でも特に線の美しさに定評があります。
キャラクターの髪のなびきや服のシワなど、細かい描写をこだわりたい方に最適です。
実写・日本美系:Yayoi
Yayoiは、日本人の顔の造形を極めて高い精度で再現するために開発されたモデルです。
実在感のある日本人女性を生成したい際、どちらのモデルを使うか迷ったら、まずはこれをおすすめします。
よくある質問(FAQ)
要点:初心者がつまずきやすいポイントについて、専門的な知見からお答えします。
Q:モデルを読み込もうとするとエラーが出ます。
回答: モデルのバージョン(SD 1.5用かSDXL用か)が、使用しているベース環境と合っていない可能性があります。
また、ファイルが破損している場合もあるので、再ダウンロードを試してください。
Q:生成された画像が白っぽくなってしまいます。
回答: VAEが設定されていない可能性があります。
「Settings」タブから適切なVAEを選択するか、VAEが内蔵されたモデルを使用してください。
Q:スマホでもこれらのモデルは使えますか?
回答: 基本的にStable Diffusionは高いPCスペックを要求するため、スマホ単体での動作は難しいです。
ただし、Google Colaboratoryやクラウドサービスを利用すれば、スマホのブラウザからPC環境を操作して生成することが可能です。
Q:どのモデルが一番「最強」ですか?
回答: 目的によります。実写なら「Realistic Vision」、アニメなら「Animagine XL」が2026年でも不動の人気です。
まずは自分が作りたいジャンルの定番モデルを数種類試すことから始めましょう。
まとめ:自分だけの「最高の一枚」を見つけよう
要点:モデル選びは、あなたの想像力を形にするための最も楽しいプロセスです。
ここまで、
- Stable Diffusionのモデル一覧
- おすすめの種類
- インストール方法
そして最新のトレンドまで幅広く紹介してきました。
2026年現在、AIの進化は目覚ましく、モデル一つを変えるだけで、昨日までは難しかった表現が魔法のように実現します。
大切なのは、知識を詰め込むことではありません。
実際に一つでも多くのモデルを触ってみることです。
試行錯誤(トライアル)の中で、あなただけの「これだ!」と思える最高のモデルに出会えたとき、AI画像生成の本当の楽しさが始まります。
この記事が、あなたのクリエイティビティを加速させる一助となれば幸いです。
さあ、今すぐお気に入りのモデルをダウンロードして、新しい世界を描き始めましょう!